For VPC deployments: This topic covers possible explanations for why a queue is stuck. Also, see Execution States.
In a VPC deployment, a run stuck in the Queued state means that no machines in the chosen hardware tier are available. A new machine must spin up, which can take a few minutes. If your run remains queued after several minutes, it’s possible that a capacity limit has been reached, or there may be some problem with the system.
-
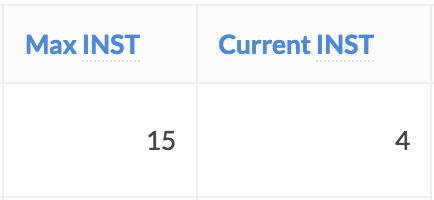
Go to the Dispatcher page, and locate the description of the stuck hardware tier near the top of the page. If Current INST >= Max INST, then you’ve reached the limit.
-
Click Launch Instance to launch additional instances beyond this limit that will run until they timeout.
-
If this is a recurring problem, you can configure a higher limit in the hardware tier definition.
In rare cases, a machine can get into a stuck or crashed state where it can’t accept jobs, but also blocks other machines from spinning up, resulting in a blocked queue. A stuck machine can be identified by an Instance State of Running (and no version number), but an empty Executor State (rather than Available):

In contrast, a healthy executor:
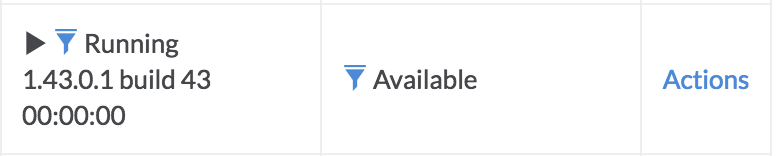
An executor that has just started will look like a stuck one until the Domino service comes online (this can take a few minutes). A sign of an executor that has just started is a recent LaunchExecutorDispatcherAction of the same tier. You can see this in the Actions section on the Dispatcher page.
If you do have a stuck machine:
-
Put it in maintenance mode. Once you’ve done so, a new machine will start up to unblock the queue.
-
Stop the stuck executor and take it out of maintenance mode, after optionally pulling logs or otherwise inspecting the machine.
If there are no stuck machines, and Max INST < Current INST, then you might have reached an AWS-imposed limit on a resource. These limits include:
-
number of running machines of a given instance type
-
total running instances
-
total number of EBS volumes
Dispatcher logs will indicate whether this is the case - look for a LimitExceeded exception, e.g. InstanceLimitExceeded. These limits can be increased via a request to AWS.
It’s also possible for AWS to run out of capacity for the selected instance type in your deployment’s availability zone. Try manually launching an instance via the tier’s "Launch" button at the top of the dispatcher page - an error message will pop up if there is insufficient capacity available. You should also see an InsufficientInstanceCapacity exception in the Dispatcher logs. If this happens, there isn’t anything you can do but wait for AWS to provide additional capacity - you’ll probably want to advise users to switch to a different hardware tier in the meantime.
If you see other AWS-related exceptions in the Dispatcher logs, check https://status.aws.amazon.com for outages.
There may be some other issue with the system. Please reach out to support@dominodatalab.com for additional assistance.