Prediction data is the output produced by a model. You must add data that was trained on historical data to your model’s code to start ingesting and storing prediction data for monitoring.
-
Click the registered model and go to the Data Drift page.
NoteIf you want to do this from the Overview page, go to Add Data > Prediction Data. -
Click Register Prediction < Upload Prediction Config.
-
In the Register Prediction window, upload or paste a JSON configuration that describes the prediction variables and the location of the prediction dataset.
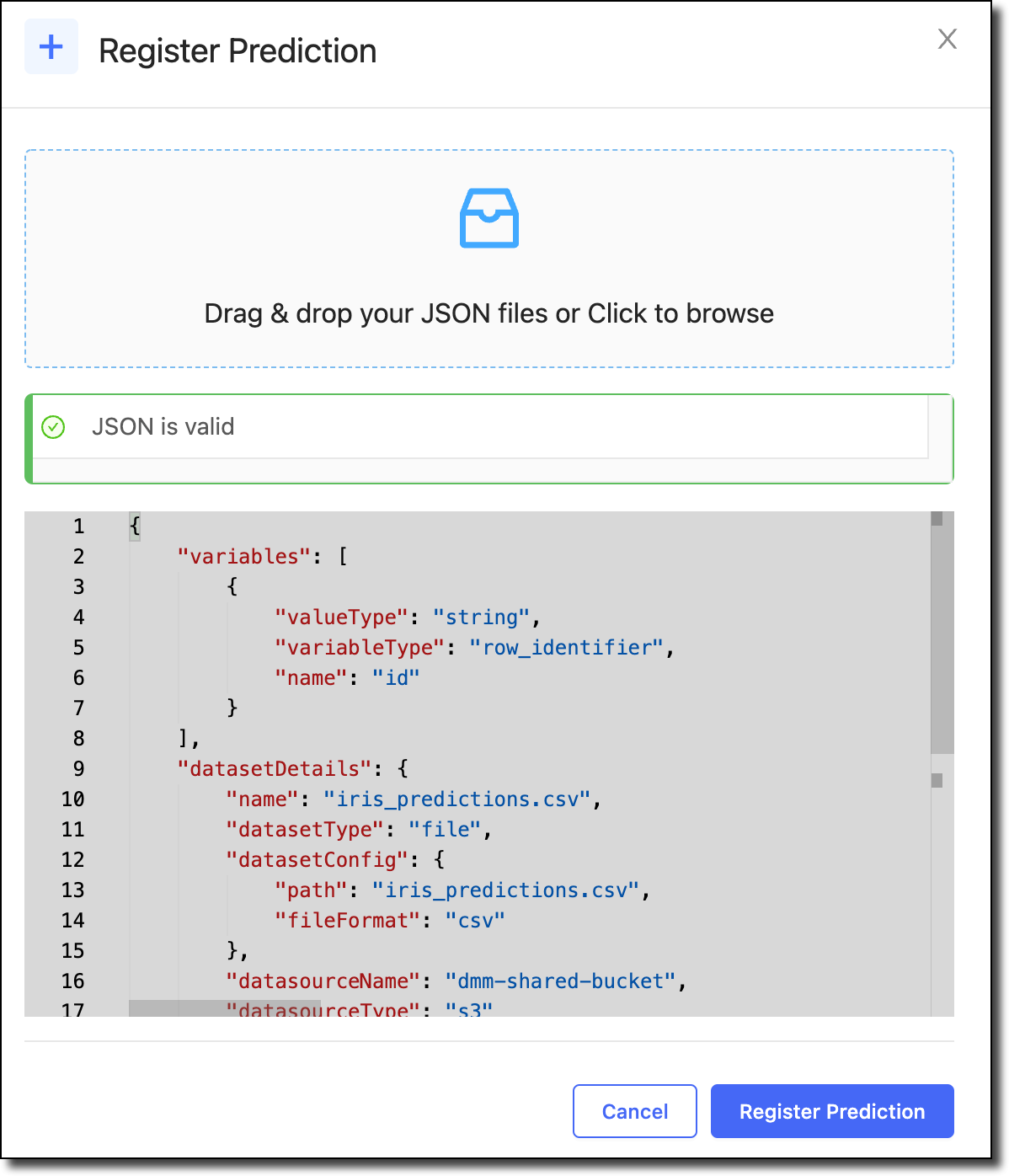
The following is a sample file. This file doesn’t require any variable information. You can include prediction variableTypes, although, you typically include these when you define your training data to get a complete set of metrics. If you define the variables here, you will only get drift predictions. You can also define the following variables:
sample_weight,prediction_probability, andtimestamp. The configuration must always include thedatasetDetailsandmodelMetadatainformation.See Monitoring Config JSON for details about each field in the JSON.
{ "variables": [ { "name": "campaign", "variableType": "sample_weight", "valueType": "numerical" } ], "datasetDetails": { "name": "Predictions.csv", "datasetType": "file", "datasetConfig": { "path": "Predictions.csv", "fileFormat": "csv" }, "datasourceName": "abc-shared-bucket", "datasourceType": "s3" } } -
Click Register Prediction and the Model Monitor will start calculating drift on the registered dataset.
After you add the prediction data, you might want to check its status.
-
From the navigation pane, click Model Monitor.
-
Click the name of the model for which you set up ground truth data ingestion.
-
On the Overview page’s Data Traffic tab, you can see the history of the ingested data and review the model’s metadata and schema.
-
Click Ingest History to check to see if the status is
Done. The following are other statuses you might see:Completed with Warnings-
Click the three vertical dots at the end of the row and click View Details.
Failed-
Click the three vertical dots at the end of the row and click View Details.
If the ingestion failed, Domino stops the continuous ingestion. After you fix the issue, re-register the prediction data and Domino restarts continuous ingestion from this point.
NoteIf you re-register the same dataset, Domino processes the entire table again. This causes duplicate records which affects the drift and model quality calculations. Skipped-
The dataset had no rows to fetch.
You can click Status to select checkboxes to filter by status.
-
Click Refresh to see a graph of the Data Ingest Timeline.
After the data is ingested, you can perform an ad-hoc model quality analysis to validate your setup. Then, set up a schedule to perform model quality analysis automatically.
After the drift calculations are complete, you can see the divergence value for each feature in the Drift column. The computation used the default Test Type and Threshold values.
-
To access this page, in the navigation pane, click Model Monitor.
-
Go to the model whose data drift you want to see and then click Data Drift.
NoteTo change the default settings to experiment with other Test Types, Conditions, and Default Threshold Values, in the navigation pane click Settings. Then, click Test Defaults, make your changes and click Save.
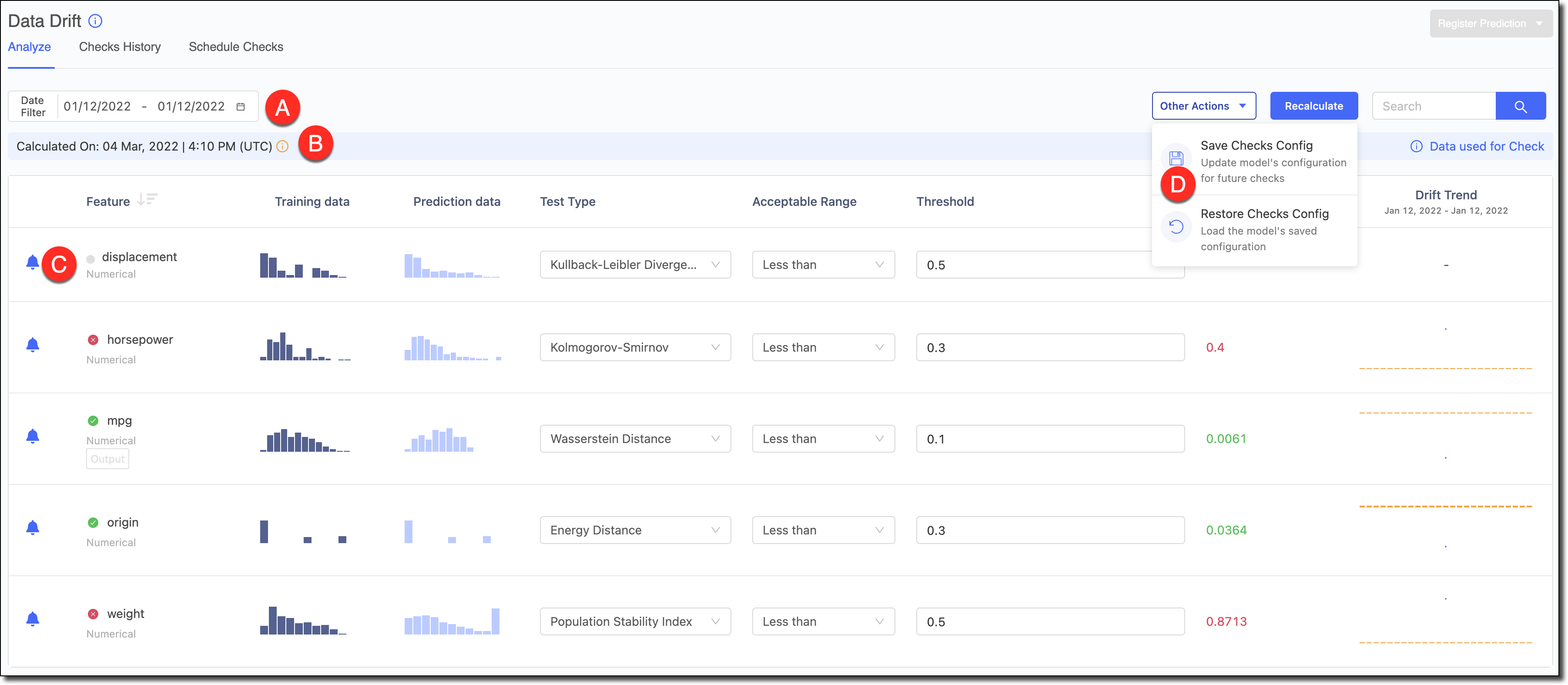
A - Use the Date Filter to refine the data and review the Drift and its trends for specific periods.
B - If your model had a timestamp column declared, it’s used to get the timestamp of different predictions in the dataset. If the timestamp wasn’t declared, then the data’s ingestion time in the Model Monitor is used as its timestamp.
C - To reduce alert noise, click the bell icon next to features to disable alerts to exclude them from the Scheduled Checks.
D - If you made changes to the test types, thresholds, and so on and want to save them as the default configuration for the model to be used for running scheduled checks, go to Other Actions > Save Checks Config to save the changes. If you experimented with configurations and wanted to load the model’s default configuration to reset the Analyze table, go to Other Actions > Restore Checks Config.