An artifact is a file whose purpose is not source code or a data set. Artifacts usually contain the output from your data analysis jobs, such as plots, charts, serialized models, and so on. Your workspaces, jobs, and other executables can access data in your project artifacts just as they would any other source of data.
Keep in mind that accessing project artifacts in your executions can impact their performance. This is because many events can trigger a project file sync, and running executions must wait for the sync to complete before they can access the data again.
-
In a DFS-based (Domino File System) project, artifacts are stored alongside the rest of your project files. You can save them just as you would any other files in your project.
-
In a Git-based project, artifacts are stored in a special Artifacts folder in the DFS. See the instructions below for saving artifacts in a Git-based project.
-
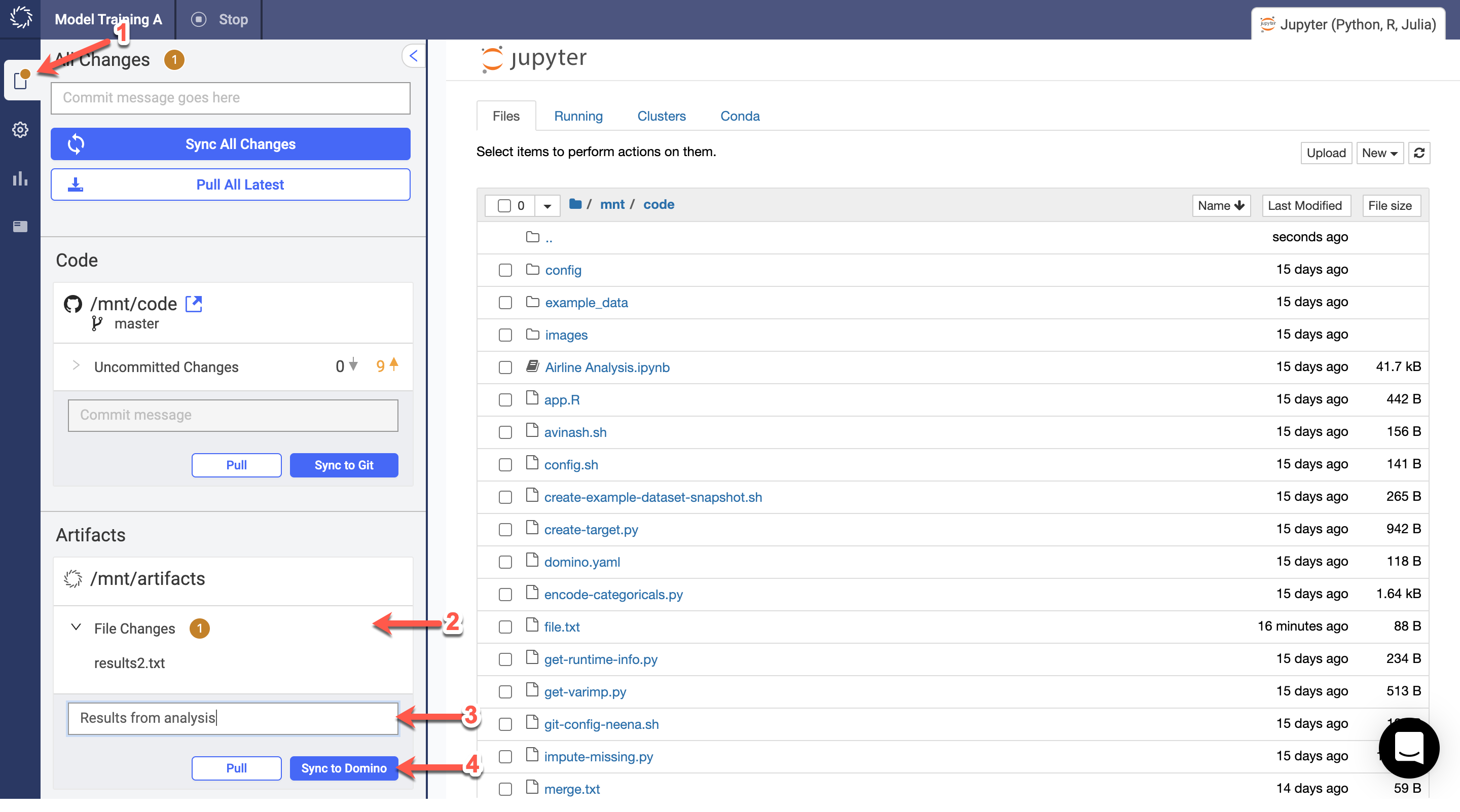
In the navigation pane of your workspace, click File Changes.
-
Under Artifacts, expand File Changes.
-
Enter a commit message.
-
Click Sync to Domino. Domino saves your artifacts to the Domino File System (DFS).
If you are storing small data files as project artifacts, you can access them from your code just like any other data source. This topic explains how to get the path to a project artifact file so you can refer to it in your code.
Keep in mind that accessing project artifacts in your executions can impact their performance. This is because many events can trigger a project file sync, and running executions must wait for the sync to complete before they can access the data again. Datasets are recommended for better efficiency and scalability; see Work with datasets in projects.
|
Tip
| If you are working with a large number of project artifacts, consider using the Domino CLI to manage them. |
Your profile files are accessible at the path /mnt/code.
For example, if you have a file under Files in your project at reference-project-ner/dataset/ner_dataset.csv, you can refer to it in your code as /mnt/code/reference-project-ner/dataset/ner_dataset.csv.
|
Tip
|
Replace /mnt with the $DOMINO_WORKING_DIR environment variable to make your code more portable.
This is especially useful when projects are exported and imported.
|
When you start a run or launch a workspace, Domino copies your project files to a Domino execution. When working with large volumes of data, this presents the following potential issues:
-
By default, you can store 10,000 files in a Domino project and you might exceed the limit.
-
By default, you can only transfer individual files that are 8 GB to and from your Domino project files, and you might exceed the limit.
-
The time required to transfer data to and from the Domino executions is proportional to the size of the data. It can take a long time if the size of the data is large, which can lead to long startup and shutdown times for workspaces, jobs, apps, and launchers.
You can solve these problems with Domino datasets because:
-
Domino datasets do not have a limit on the number of files that can be stored.
-
Domino datasets do not have a limit on the size of any individual file.
-
Domino datasets are directly attached to executions as networked file systems, so you do not have to transfer their contents when executions start or complete.
Project files are not accessible when you are using an on-demand compute cluster. To work around this limitation, you can copy the files you need into the project’s default dataset.
-
Learn about project file security and sharing.
-
Learn about special files in projects.
-
Learn about project artifacts.
-
Learn about data and code in DFS-based projects.