Apache Hadoop is a collection of open source cluster computing tools that supports popular applications for data science at scale, such as Spark.
To interact with Hadoop from your Domino executors, configure your Domino environment with the necessary software dependencies and credentials. Domino supports most providers of Hadoop solutions, including MapR, Cloudera, and Amazon EMR. After a Domino environment is set up to connect to your cluster, Domino projects can use the environment to work with Hadoop applications.
If your Domino administrators have already created an environment for connecting to a Hadoop cluster, you can follow these subsections of the setup instructions to use that environment in your Domino project.
For users setting up projects to work with an existing environment, read these subsections:
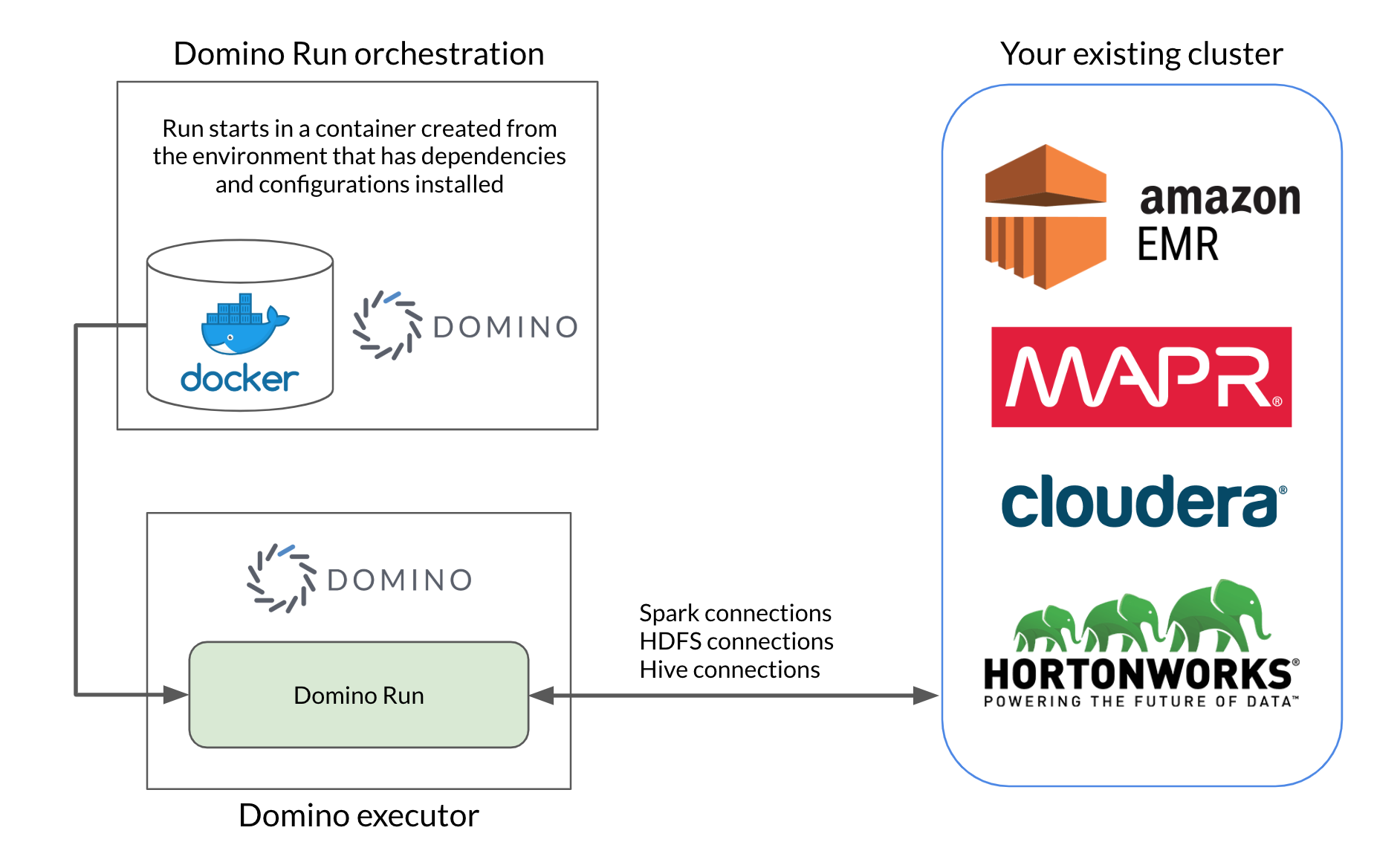
After your project is set up to use the environment, you can execute code in your Domino Runs that connects to the cluster for Spark, HDFS, or Hive functionality.
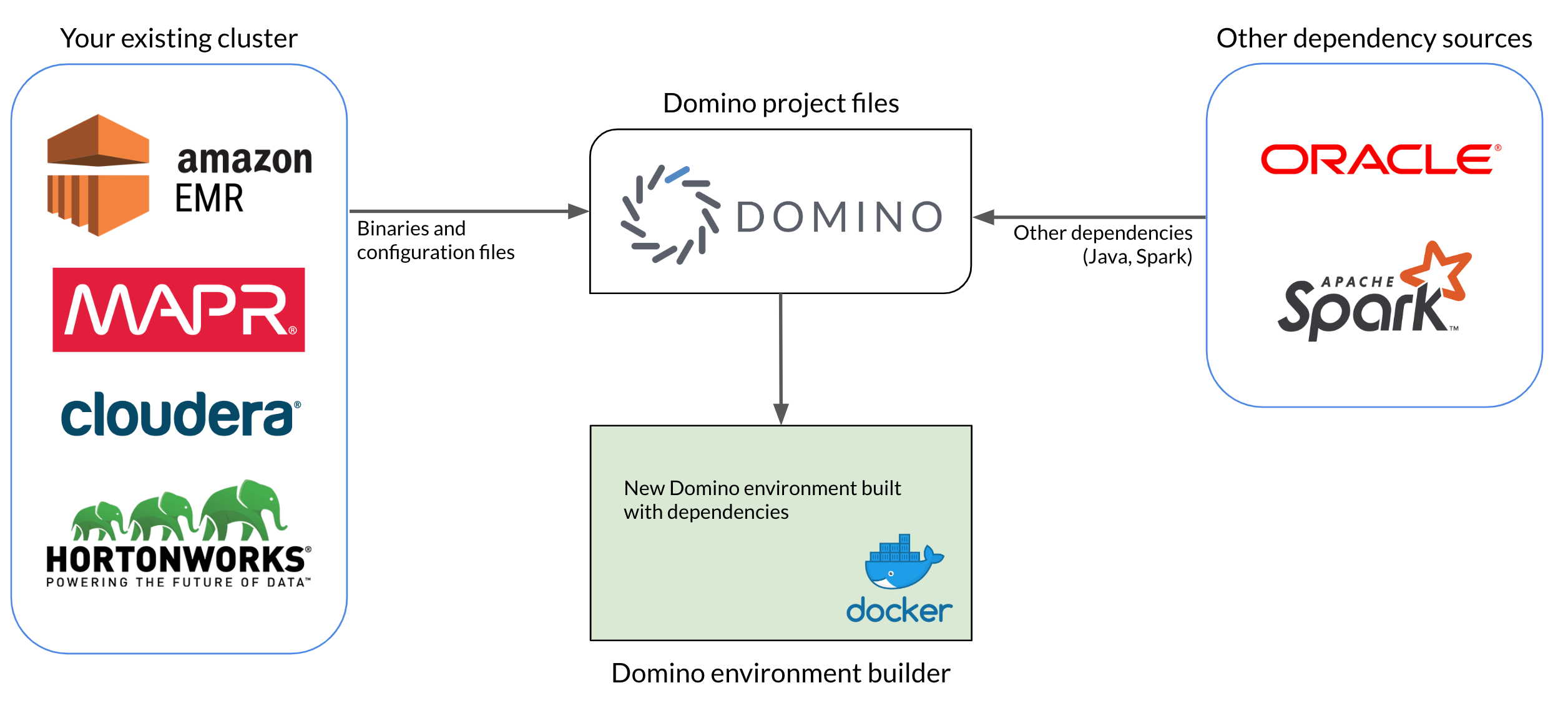
To connect to your existing Hadoop cluster from Domino, you must create a Domino environment with the necessary dependencies installed. Some of these dependencies, including binaries and configuration files, will come directly from the cluster itself. Others will be external software dependencies like Java and Spark, and you will need to match the version you install in the environment to the version running on the cluster.
The basic steps for setting up an environment to connect to your cluster are:
-
Gather binaries and configuration files from your cluster.
-
Gather dependencies from external sources, like Java JDKs and Spark binaries.
-
Upload all dependencies to a Domino project, to make them accessible to the Domino environment builder.
-
Author a new Domino environment that pulls from the Domino project, then installs and configures all required dependencies.
For Domino admins setting up a Domino environment to connect to a new cluster, read the full provider-specific setup guides:
Domino also supports running Spark on a Domino executor in local mode, querying Hive tables with JDBC, and authenticating to clusters with Kerberos. See the following guides for more information.