A datasets scratch space is a scalable mutable (i.e. read-writeable) filesystem directory for temporary data storage and exploration. They are a complement to the core Datasets functionality. They provide a space to keep intermediate data results or candidates for dataset Snapshots as you explore your data. These spaces are designed for when you don’t know what you want just yet (i.e. you don’t know what you don’t know). These spaces are automatically mounted for Workspace sessions for each User for every Project (i.e. they are Per User Per Project). Here are some key properties:
-
They do not preserve reproducibility. Files placed in a datasets Scratch Space are not versioned or tracked. A datasets scratch space is simply a long-lived directory with the scalable properties of datasets (i.e. large file sizes and many individual files).
-
They are only available for Workspaces.
-
You get a unique datasets scratch space per user per project.
-
If you shutdown and launch workspaces, the datasets scratch space is exactly as you left it. All the contents remain; unless you promote the contents to a dataset snapshot.
-
If you spin up multiple, concurrent workspaces in a project, all those workspaces will see the same datasets scratch space. Remember, your Scratch Space is private to you, so any file locks present are due to your actions or code.
-
When no workspaces are running, the contents of the datasets scratch space can be promoted to a snapshot of a dataset within the project.
For a given project (with name project-name), your datasets scratch space for that project will be at: /domino/datasets/{username}/{project-name}/scratch, where username is your Domino username.
Remember, you only get Scratch Spaces with Workspaces.
Examples
Let’s say for these examples, my username is dara-data.
-
Project:
big-data, Owner:alex-algoMy Scratch Space is at:
/domino/datasets/dara-data/big-data/scratchNotice that it doesn’t matter than the owner is
alex-algo. The scratch path is still with my username. Also, it is assumed I have the appropriate permissions to the Project. -
Project:
big-data, Owner:dara-dataMy Scratch Space is at:
/domino/datasets/dara-data/big-data/scratchNotice that it doesn’t matter that there are other Projects with the name
big-data. They won’t conflict because the scope of the path is only for Workspaces in that Project.
You can always view the contents of your datasets scratch space by launching a workspace and navigating to your scratch space. It is simply another directory (with all the high performance properties of datasets).
-
File Browser.
If you’d like to get an idea of the contents of the scratch space without using a workspace, you can navigate to the datasets project level page.
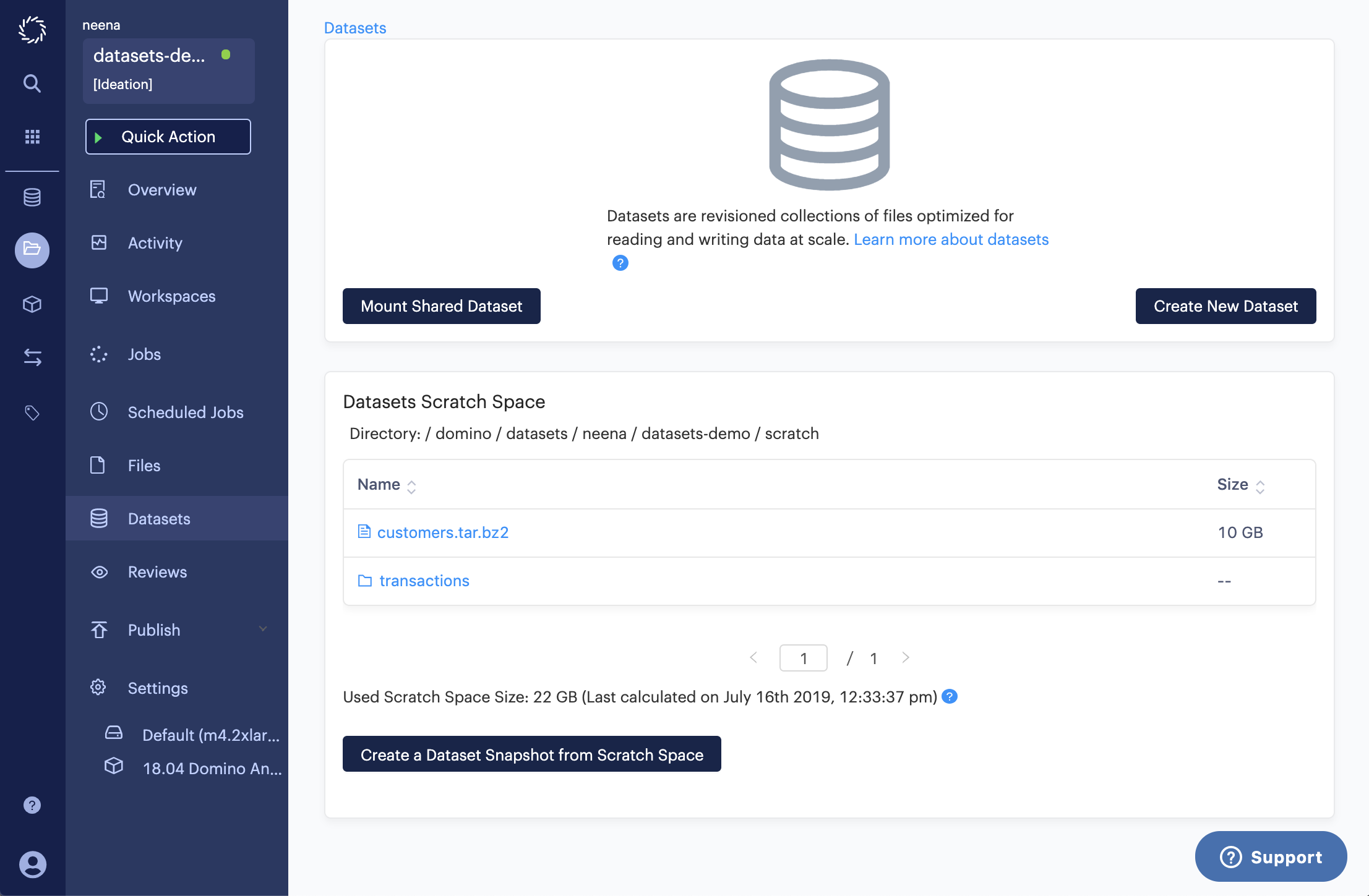
There you will find a file browser that displays the contents of your scratch space. If you have lots of files, you can paginate through. You can also drill down into any folders that are in your scratch space. As you modify the contents of your scratch space (e.g. add/delete/edit files, add/delete/edit folders), refreshing the file browser will reflect those changes.
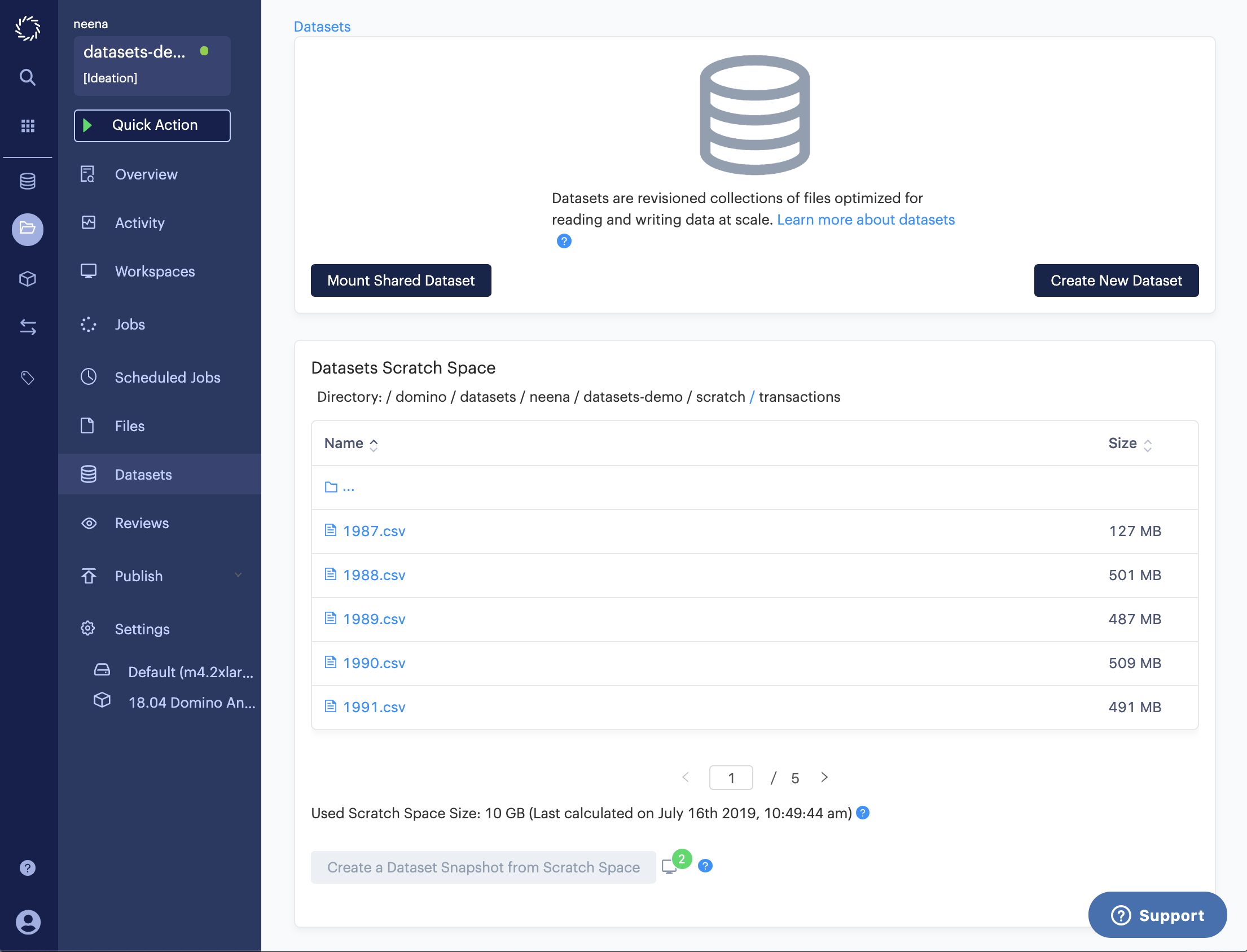
-
Calculated Size.
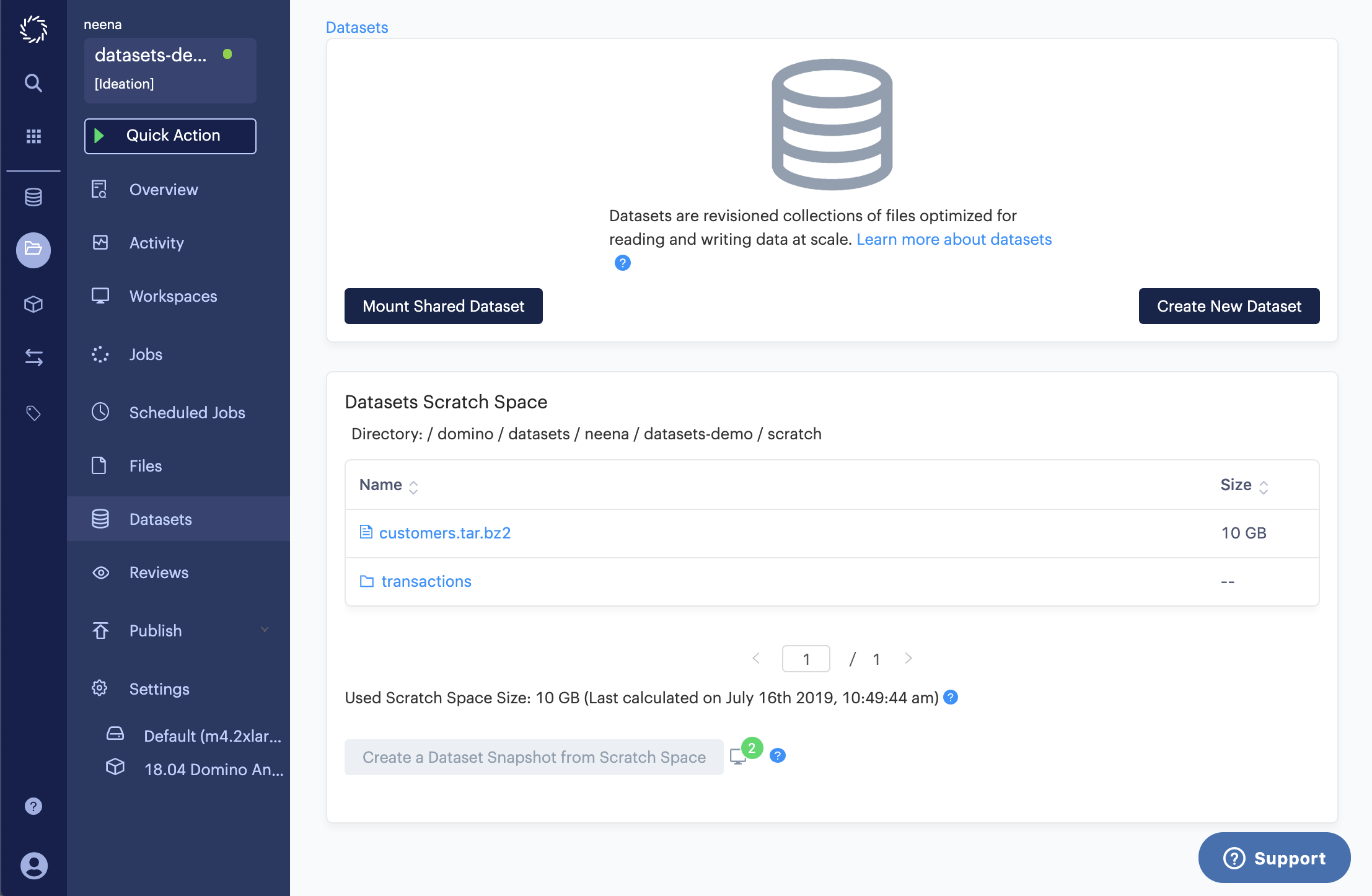
The used scratch space size is calculated anytime a workspace is stopped. The timestamp of the calculation is also provided.
In this example, I have two workspaces open, and my current calculation is 10 GB. This actually doesn’t reflect the 12 GB in the transactions folder that I created since the last time a workspace was closed.
When I close one of the workspaces, the used scratch space size is updated to 22 GB.
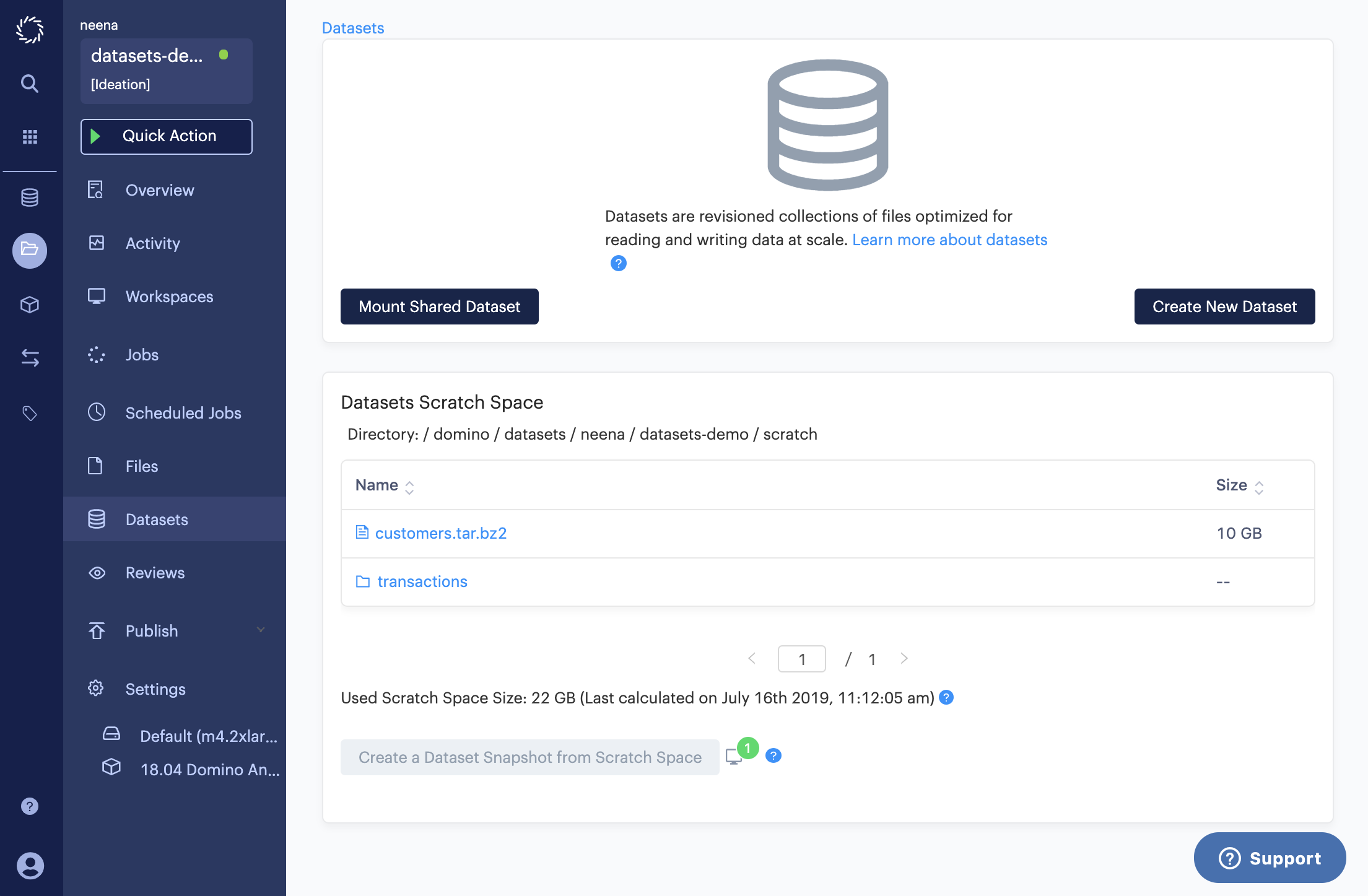
The contents of your scratch space can be made into a dataset snapshot.
-
No workspaces can be running to create a dataset snapshot from the contents of your scratch space. The Create a dataset snapshot from scratch space is only enabled when no workspaces are running.
-
You will only be able to promote to a dataset within your project.
-
Once the contents of the space scratch is made into a dataset snapshot, contents of the scratch space will be deleted (i.e. the scratch space is cleared).
Workflow
-
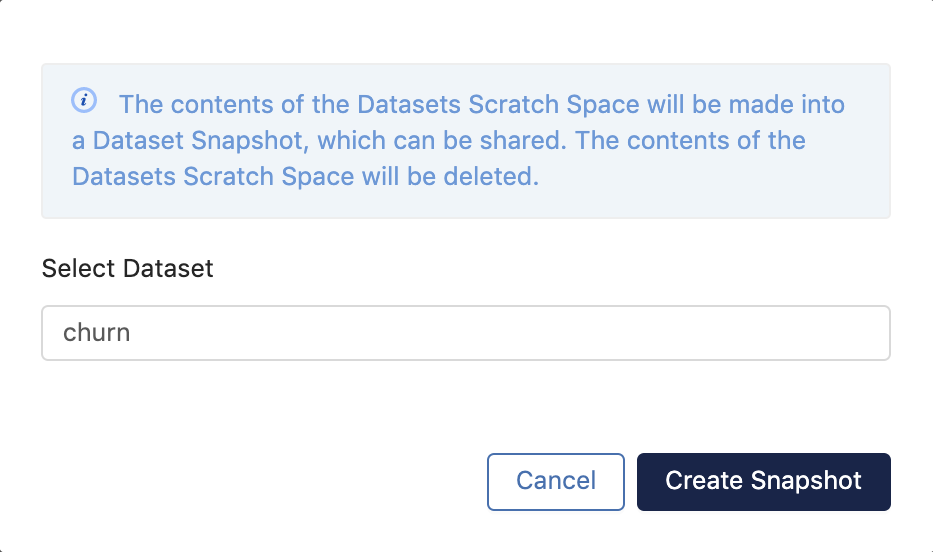
Click Create a Dataset Snapshot from Scratch Space
-
Using the input box in the modal, select a dataset in your project.
WarningWhen you create a dataset snapshot from the contents of the datasets scratch space, those contents will no longer be in the datasets scratch space (i.e. the contents of the datasets scratch space will be deleted upon promotion to a dataset snapshot). -
Click Create Snapshot
-
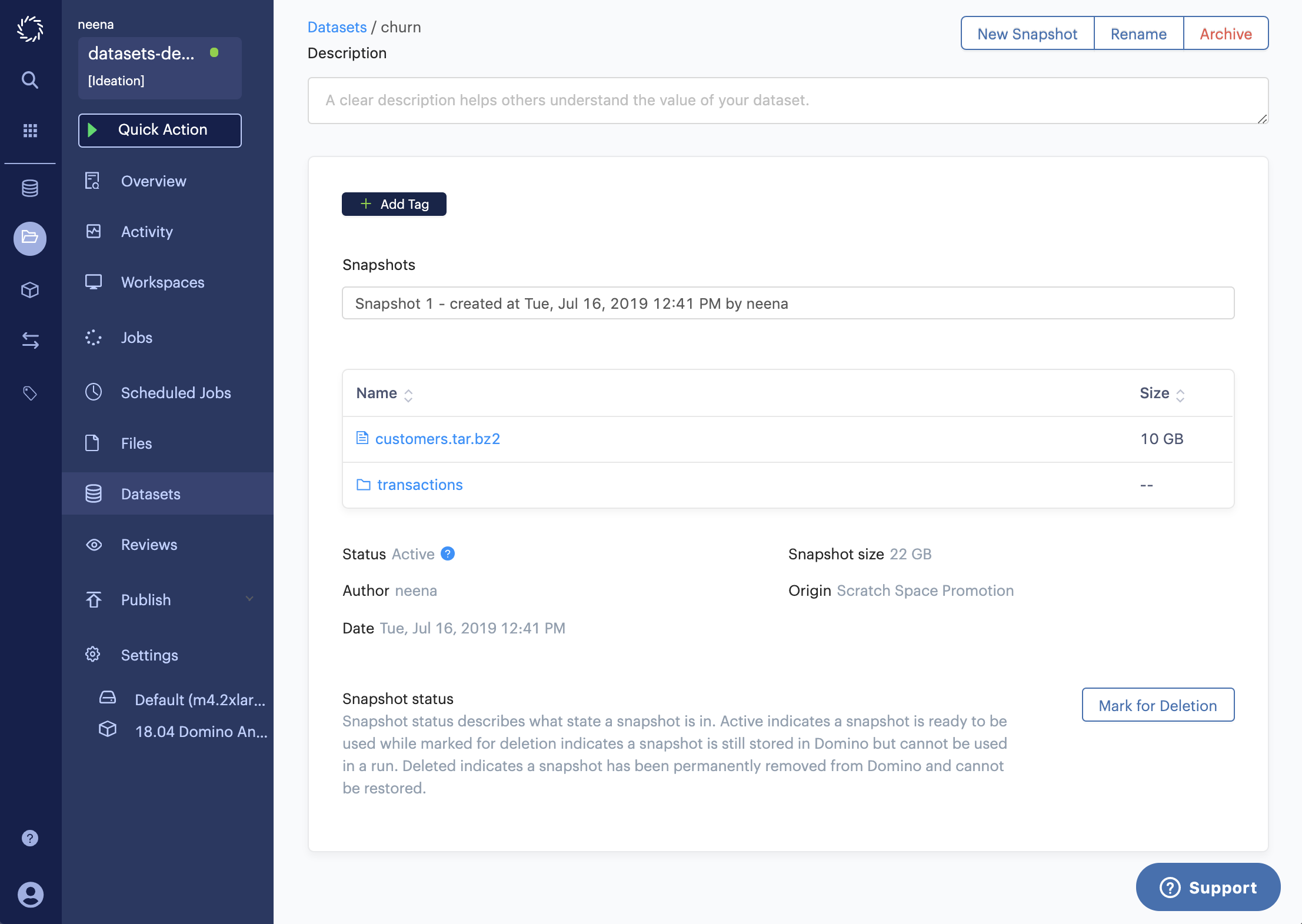
To confirm, you can navigate to the details page of your newly created snapshot.
Using a datasets scratch space for indefinite storage is discouraged. Not only does this potentially lead to wasteful storage consumption and costs, it may also be unnecessarily compromising reproducibility. Finally, while a datasets scratch space is reliable persistent storage, an accidental loss could occur from a user accidentally deleting contents from the scratch space. Creating a snapshot of valuable work from the scratch space prevents accidental loss.
To mitigate the risk of using scratch spaces for indefinite storage, a user interface indicator provides a scratch space risk notification that alerts the user of the risk associated with the contents in the scratch space. Specifically, we want to notify the user of the length of time since potentially new work has not been made into a snapshot. Here, the length of time is a proxy for risk profile.
By default, the three ranges are:
-
Low Risk: Less than or equal to five days.
-
Medium Risk: Greater than five days and less than or equal to ten days.
-
High Risk: Greater than ten days.
There are three risk ranges, separated by two thresholds; hence, the thresholds define the ranges. The risk ranges are in terms of days and have a lower bound of zero days and no upper bound. The thresholds are configurable via two central configuration values.
Namespace: common
Key: com.cerebro.domino.dataset.scratch.riskThresholdOneInDays
Value: number
Default: 5
This option controls the first datasets scratch space risk threshold in days.
Namespace: common
Key: com.cerebro.domino.dataset.scratch.riskThresholdTwoInDays
Value: number
Default: 10
This option controls the second datasets scratch space risk threshold in days.
The administration page for dataset scratch spaces is the same of as the datasets administration page. Once in the administration area, you can navigate by selecting Datasets under the Advanced menu option.
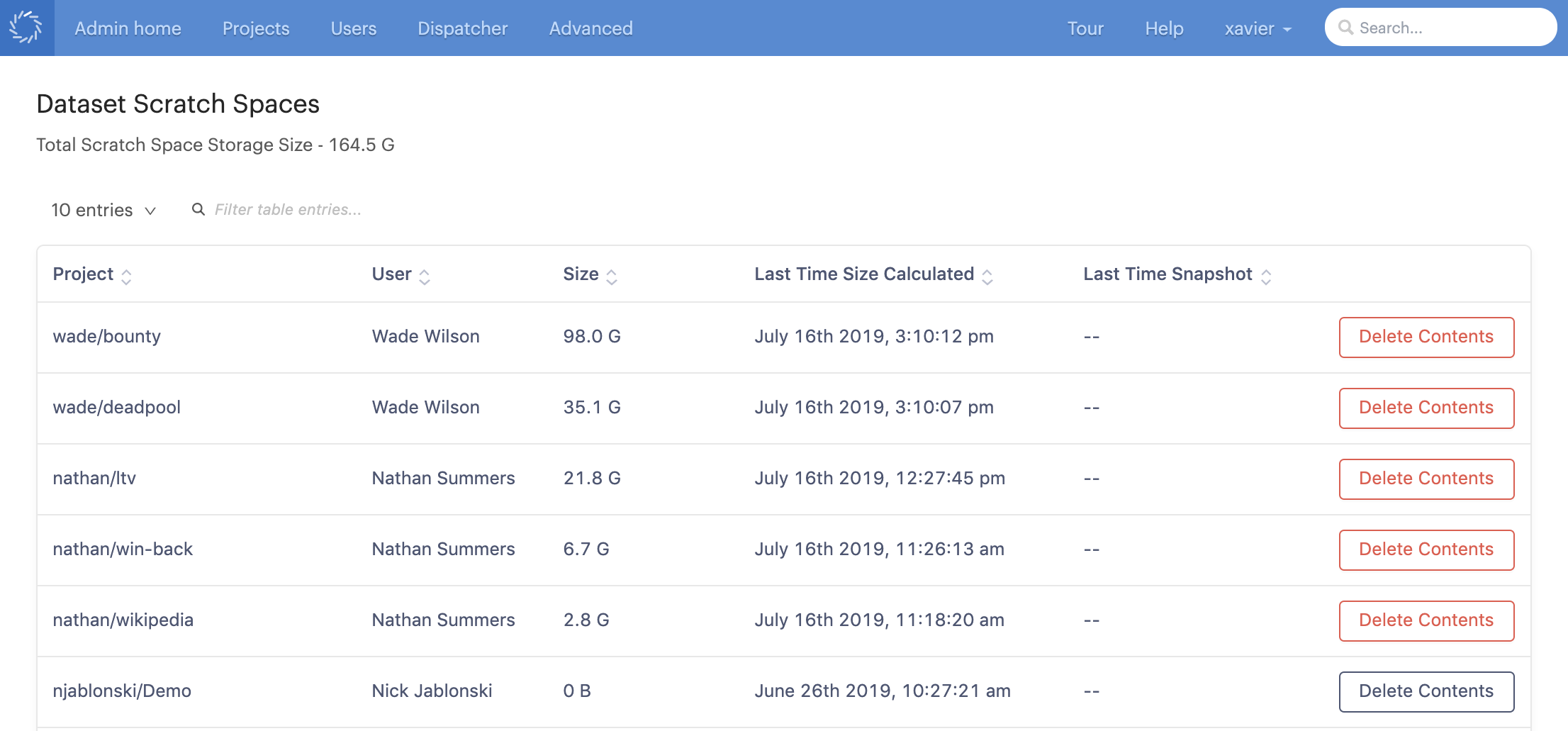
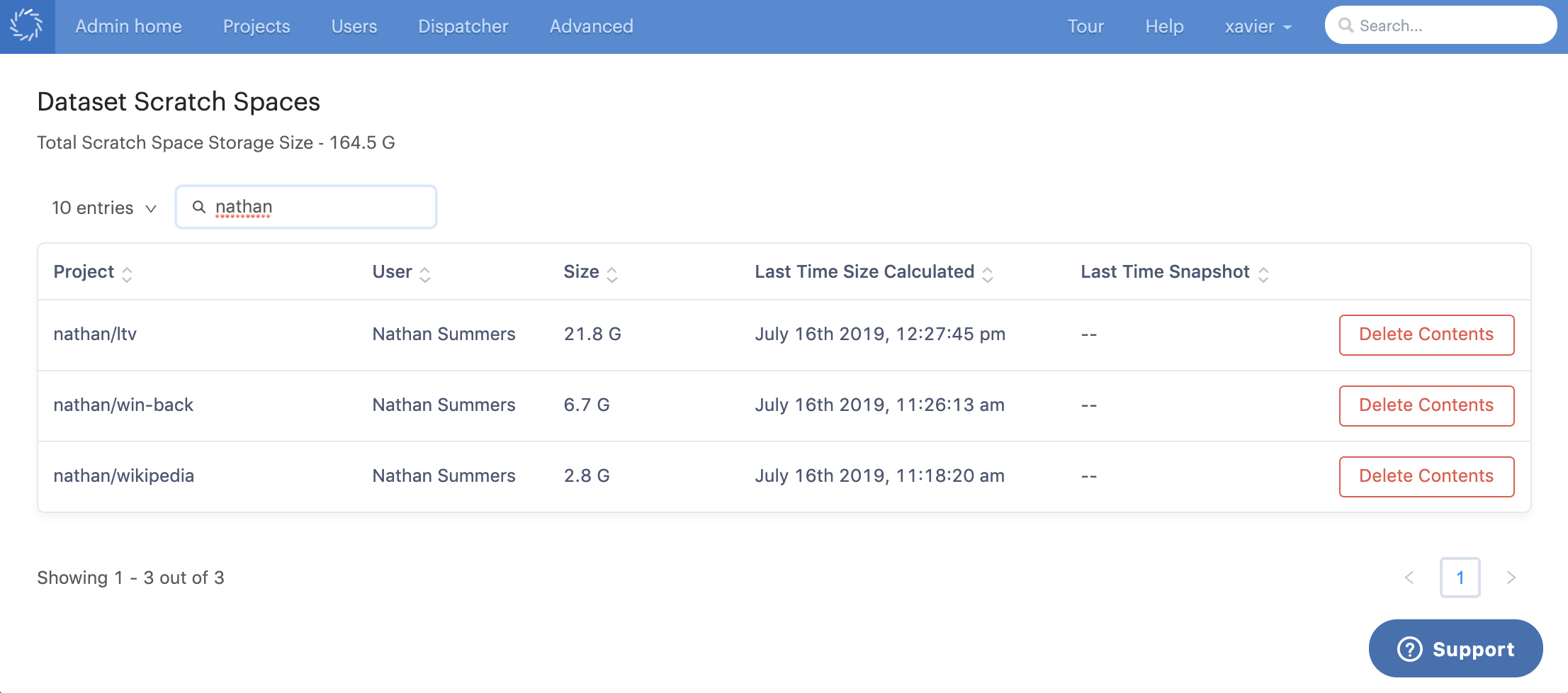
A dataset scratch spaces administration section is below the datasets administration section. A table of all dataset scratch spaces is shown.
-
Project
Unique identifier which is a concatenation of:
{owner_username}/{project_name} -
User
Full name of user.
-
Size
Used scratch space size.
-
Last Time Size Calculated
Timestamp of when the value in the Size column was calculated.
-
Last Time Snapshot
The last time the contents of that scratch space was promoted into a dataset snapshot. No value means the contents of the scratch space has never been made into a dataset snapshot.
Workflow
-
Click Delete Contents for the datasets scratch space you want to delete the contents of.
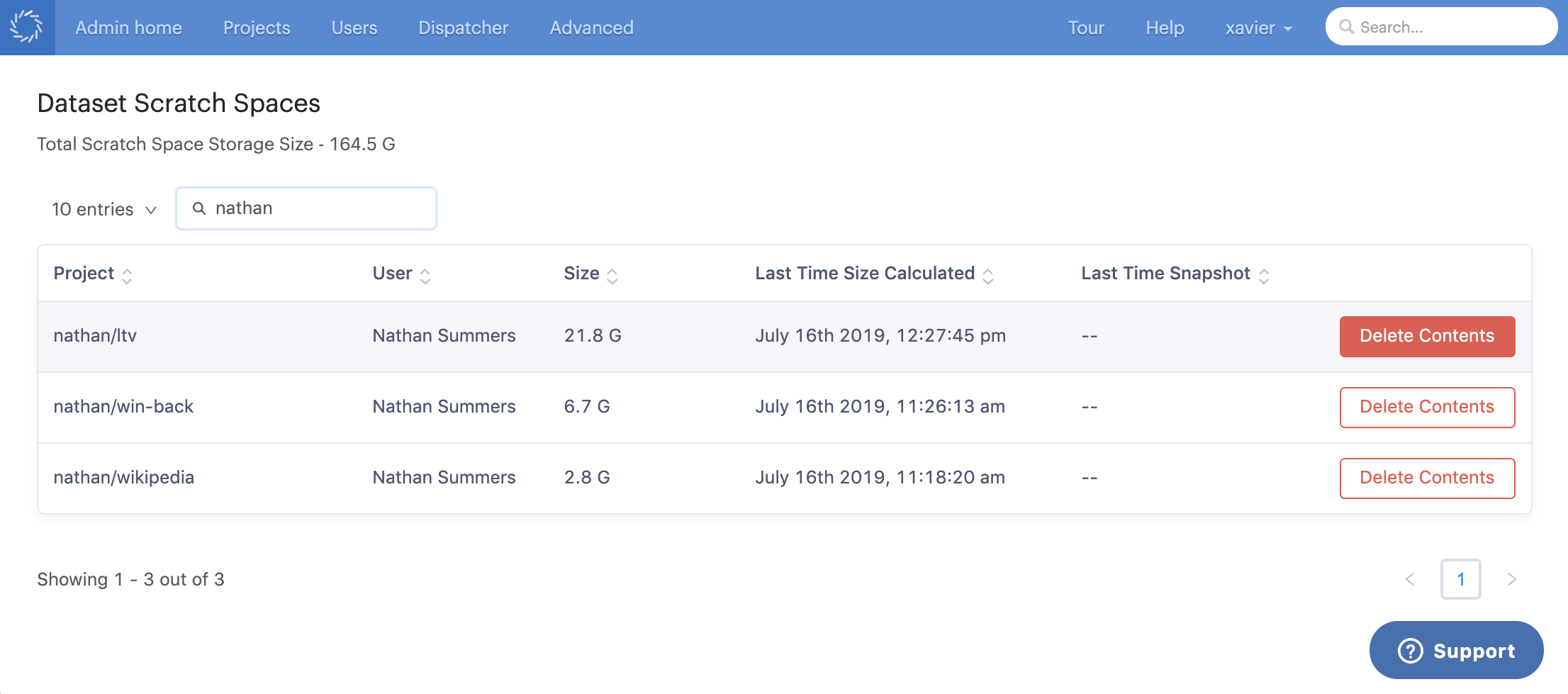
-
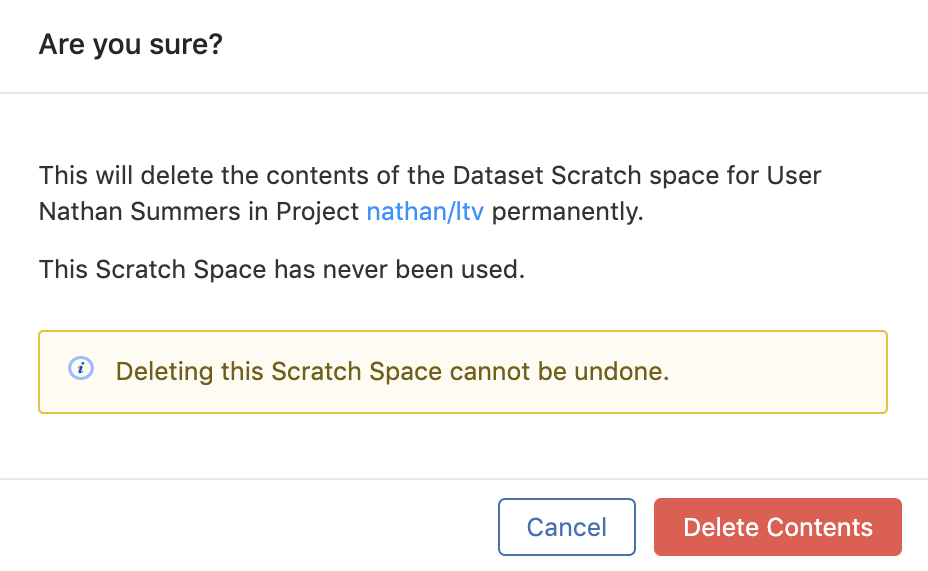
This will bring up a confirmation modal. If you are sure you want to delete the contents, press Delete Contents. Deleting the contents of a scratch space cannot be undone.
-
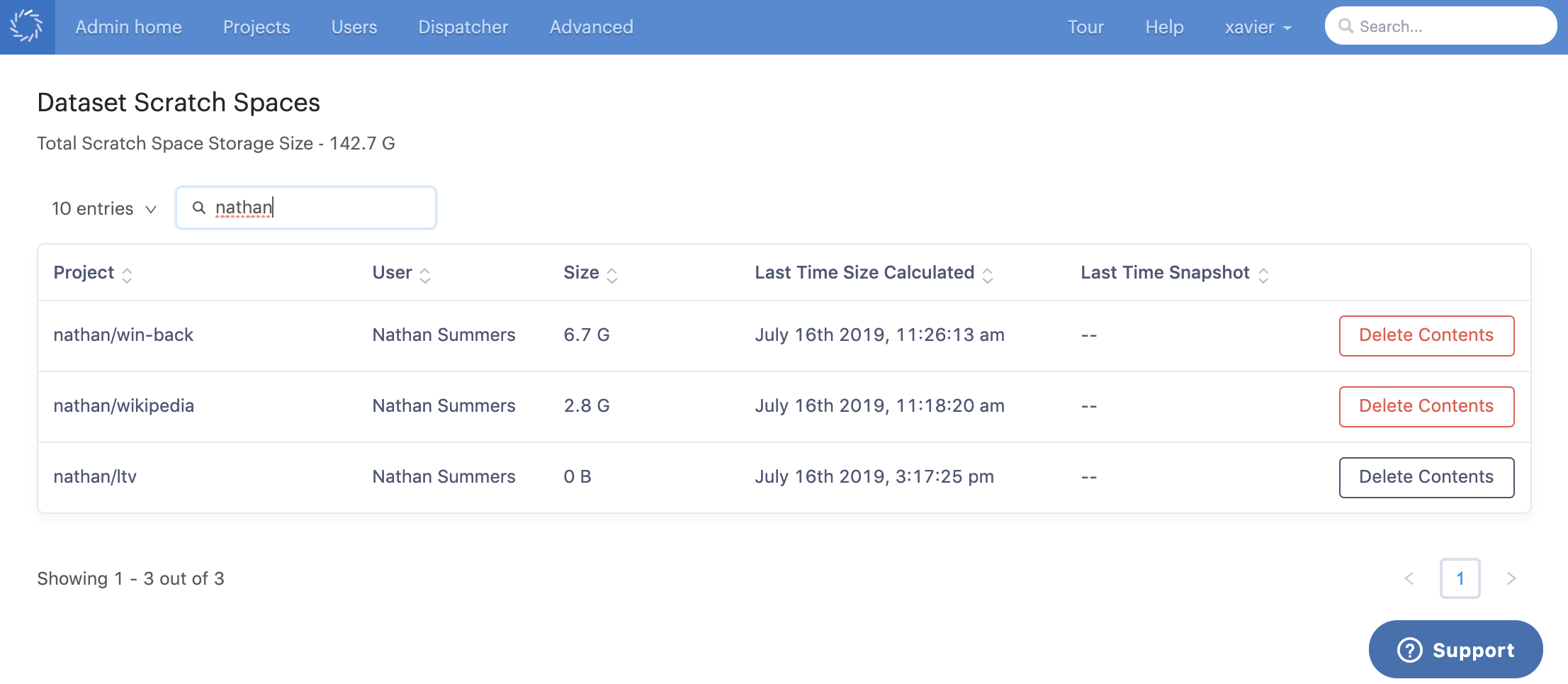
The administration table will be refreshed and you can confirm that the contents of your selected datasets scratch space are deleted.
The length of time used to notify the user is specifically the time the scratch space has been non-empty. Recall the following:
-
The storage size of the datasets scratch space contents is computed after the stopping of any workspace.
-
There are three cases the scratch space becomes empty.
-
Initial state
-
User clears it (e.g.
rm -rf *) -
Promote to snapshot
-
Consider the following figure, which illustrates the state of a datasets scratch space over time. The horizontal axis is time. Portions where the datasets scratch space is non-empty is shown in orange. A non-empty scratch space is one where there exists at least one file (of any size). At times t_2 and t_4, the scratch space is cleared (emptied) by the User and through a promotion to a Snapshot, respectively.
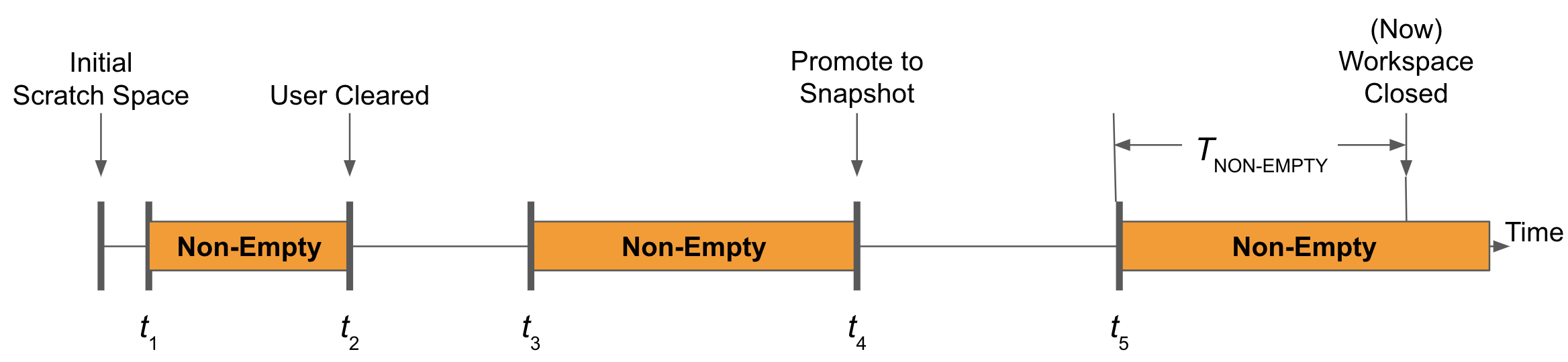
Assume we are at the moment in time marked “Now” and we’ve closed a workspace, and hence, the scratch space storage size is computed.
The non-empty time we report will be that moment in time back to t5, the most recent point scratch space storage was calculated to be non-empty coming from the empty state.
This non-empty time is specified as T_NON-EMPTY.
-
I tried to write to a datasets scratch space in a job and it failed?
A datasets scratch space is only available in workspace sessions.
-
Why is the stated “Used Scratch Space Size” in the datasets scratch space file browser different from what i expected based on the files that are currently in my datasets scratch space?
The “Used Scratch Space Size” (size calculation) is not updated in a real-time fashion. Instead, it is calculated every time a workspace is closed. Notice that with every stated “Used Scratch Space Size”, a note is presented on when the last time the value was calculated. See "Why is the size calculation in the file browser only updated when a workspace is closed?".
-
Why is the size calculation in the file browser only updated when a workspace is closed?
Constantly having a process periodically calculating a file system size for open workspaces can be taxing on the system. Remember, the scratch space is designed to have all the performance properties of datasets: it can handle large data (i.e. TBs) and many number of individual files (i.e. millions of files). Also, if workspaces are already open, users can inspect the filesystem and sizes directly. Finally, the convenience of the file browser really comes into play when no Workspaces are running, which at that time, everything is static and up-to-date.
-
Why is “Create a Dataset Snapshot from Scratch Space” button disabled sometimes?
You can only snapshot a Datasets Scratch Space when no Workspaces are running.
-
Why are the contents of the datasets scratch space deleted upon promotion to a dataset snapshot?
This is for performance reasons. Like datasets, scratch spaces can potentially contain large sized files and a large number of individual files. In order to create a dataset snapshot and preserve the contents of the scratch spaces, we would need to perform an expensive and robust copy operation (i.e. long time and computation resources). By allowing the scratch space to be cleared upon promoting its contents to a datasets snapshot, we are able to cleverly perform the operation instantly. Both the scratch space and newly created dataset snapshot are available for use after promotion.
-
I want to promote my scratch space to a dataset that doesn’t exist yet. How do I create a dataset?
See Create a Dataset and Datasets Best Practices for advice and instructions.
-
What if I want to take the contents of my dataset scratch space and make it into a snapshot of a dataset not in my current project?
You would have to do this manually and just treat the scratch space like a directory you’d like to copy or move into new snapshot directory.
First, you must have access to create a new snapshot to a project (see Share and Collaborate).
Assuming you have permission, you would need to create a configuration in your
domino.yamlfile where you mount an output directory for your desired dataset. Because the dataset is not in your project, you will have to refer to the dataset in a fully-qualified way:{project_owner_username}/{project_name}/{dataset_set}.So, for example, if I wanted to mount an output directory so that i could create a new snapshot to a dataset called
irisin a project calleddatascienceowned byjohn_smith, I should have a YAML entry that looks something like:datasetConfigurations: - name: “new iris snapshot” outputs: - path: “new_iris” dataset: “john_smith/datascience/iris”Here, I called the configuration
new iris snapshotand I chose a mount point ofnew_iris; both this are up to you.Once you’ve properly mounted the output directory for your new snapshot, you can simply launch a run and copy or move the contents of your scratch space to the output directory.
-
What dataset scratch spaces are shown in the administration table?
All dataset scratch spaces are shown in administration table for dataset scratch spaces. A dataset scratch spaces becomes “active” any time a user starts a workspace in a project. Hence, there is a dataset scratch space for any project that a user starts a workspace.
-
Why am I allowed to delete the contents of a datasets scratch space that uses zero bytes?
Scratch spaces with any files are eligible to be deleted; this is the case even if the files are zero bytes.