This topic describes how to convert legacy data sets workflows to use Domino datasets. This involves moving your data into a new Domino dataset, and then updating all projects and artifacts that consume the data to retrieve it from the new location.
Legacy Data Sets are semantically similar to projects. If your deployment is running a version of Domino with the new Domino datasets feature, you can create Domino datasets inside legacy data sets. This allow sfor a very simple migration path for a legacy data set, where all of the existing data is added to a single Domino dataset owned by the legacy data set, and the entire file structure is preserved.
The long term deprecation plan for legacy data sets is to transform them into ordinary Domino projects, which will continue to contain and share any Domino datasets you created in them.
To get started, you need to add a script to the contents of your legacy data set that can transfer all of your data into a Domino dataset output mount. From the Files page of your legacy Data Set, click Add File:
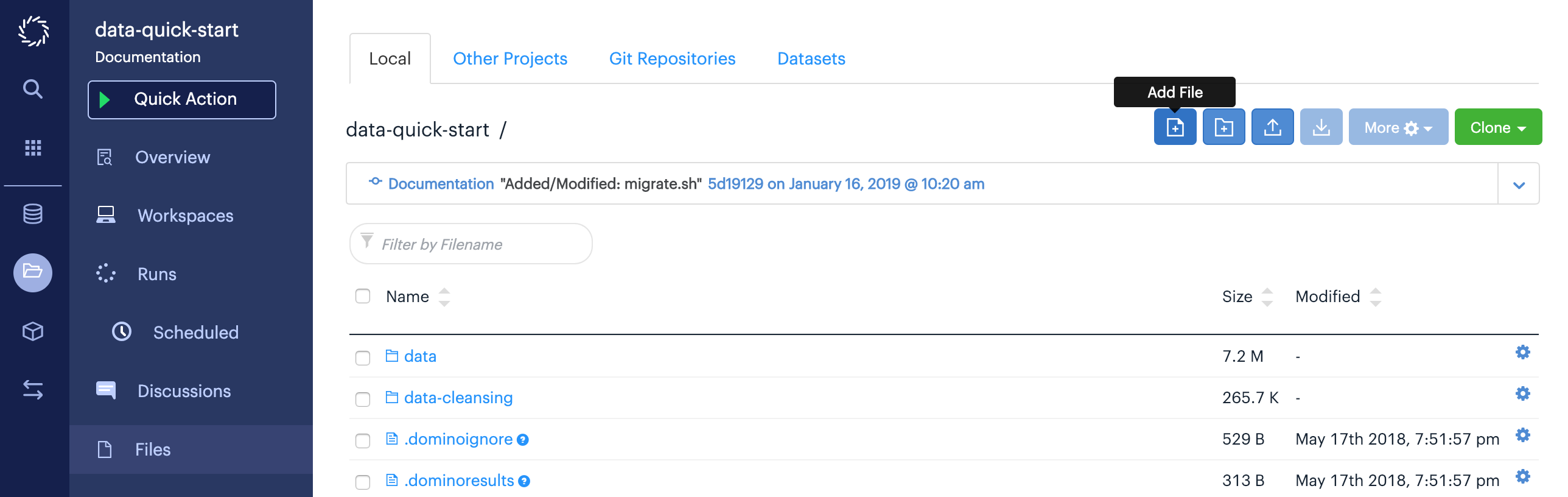
Name the file migrate.sh, and paste in the example command provided below.
cp -R $DOMINO_WORKING_DIR/. /domino/datasets/output/mainThis example migration script copies the contents of $DOMINO_WORKING_DIR to a Domino dataset output mount path.
$DOMINO_WORKING_DIR is a default Domino environment variable that always points to the root of your project.
The directory named main in the path below is derived from the name of the Domino dataset that will be created to store the files from this legacy Data Set.
Click Save when finished. Your script should look like this:

Next, click Datasets from the project menu, then click Create New Dataset.
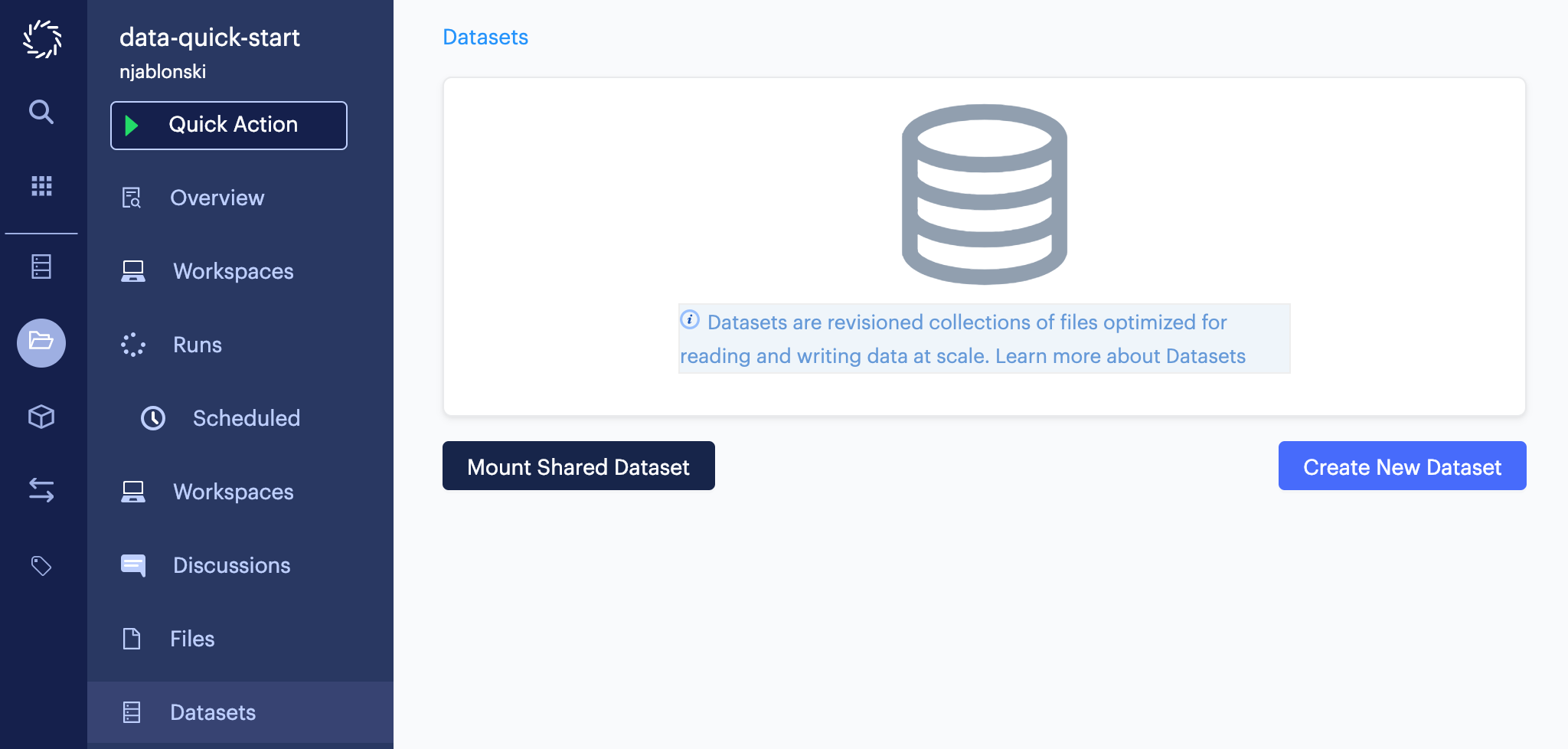
Be sure to name this dataset to match the path to the output mount in the migration script.
If you copied the command above and added it to your script without modification, you should name this dataset main.
You can supply an optional description, then click Upload Contents.
On the upload page, click to expand the Create by Running Script section.
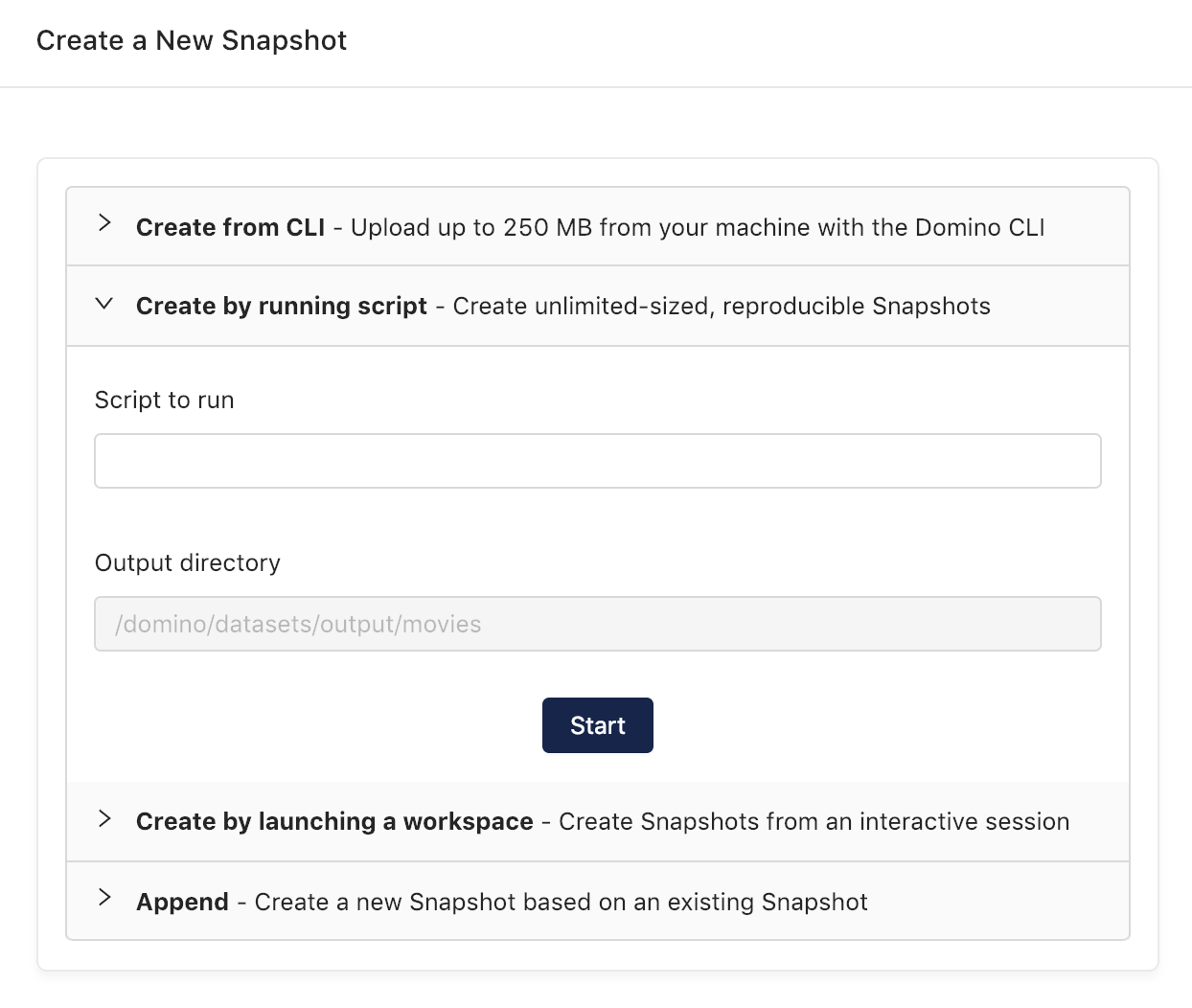
Double-check to make sure the listed Output Directory matches the path from your migration script, then enter the name of your script and click Start. A Job will be launched that mounts the new dataset for output and executes your script. If the job finishes successfully, you can return to the datasets page from the project menu and click the name of your new dataset to see its contents.
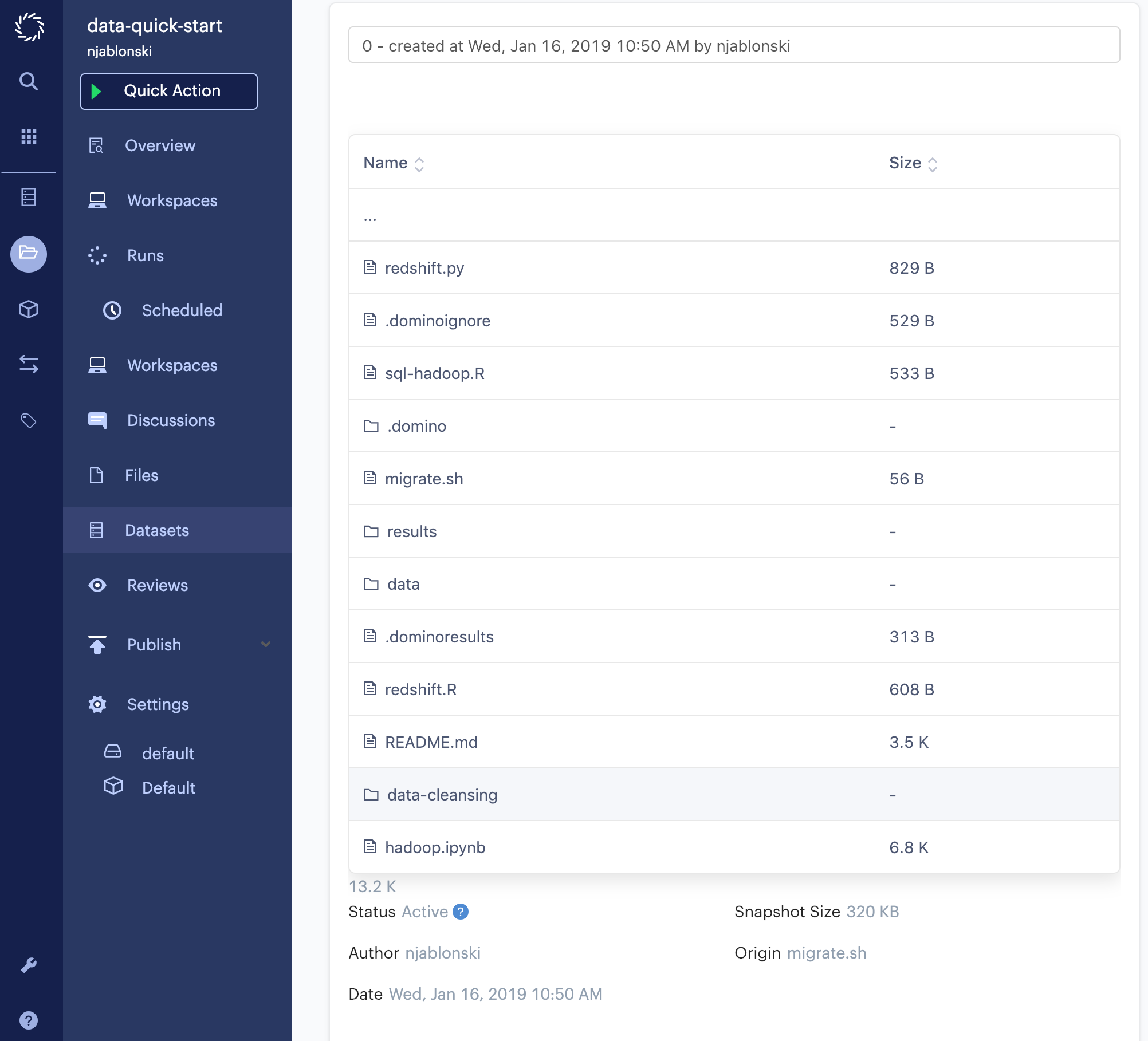
You now have all of the data from your legacy data set loaded into a Domino dataset. This method preserves the file structure of the legacy Data Set, which is useful for the next step: updating consumers to use the new dataset.
Potential consumers of your legacy Data Set are those users to whom you granted Project Importer, Results Consumer, or Contributor permissions. As the project Owner, you also may have other projects consuming the contents of your legacy Data Set. This same set of permissions will grant access to your new Domino dataset.
A project consuming data from your legacy Data Set will import it as a project dependency, and it will be visible on the Other Projects tab of the Files page.
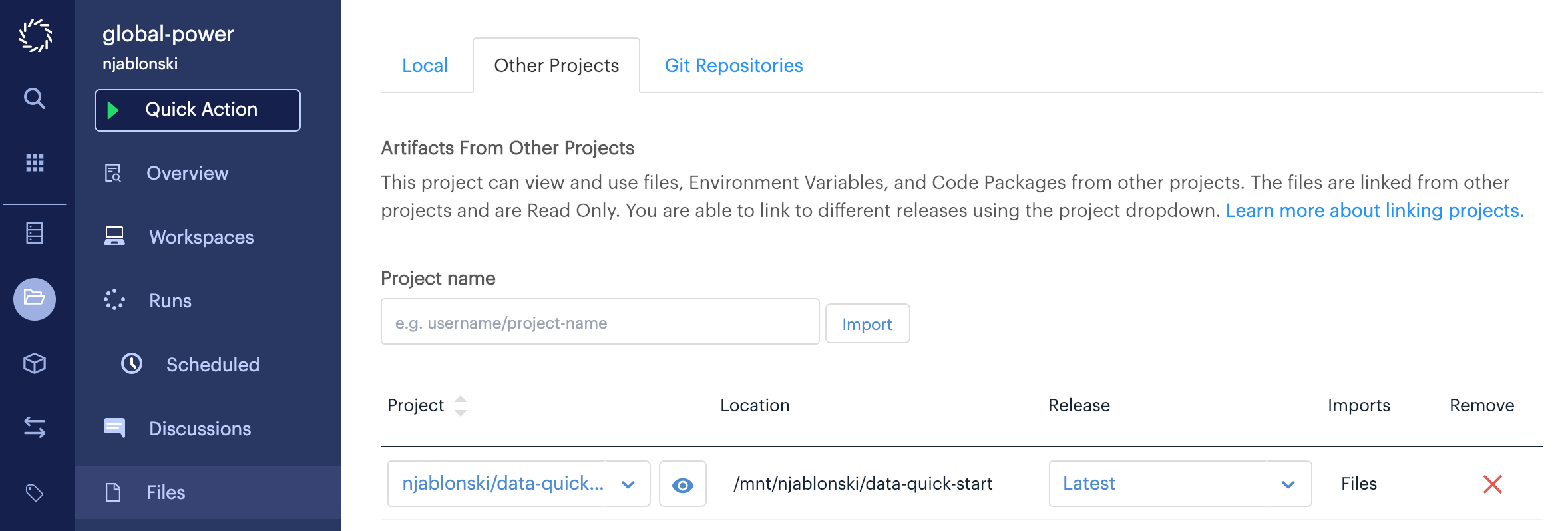
In the example above, the global-power project imports the data-quick-start legacy Data Set.
The contents of data-quick-start are then available in global-power Runs and Workspaces at the path shown in the Location column.
Anywhere your code for batch runs, scheduled runs, or apps refers to that path will need to be updated to point to the new Domino dataset.
To determine the new path and set up access to the Domino dataset, you need to mount the dataset.
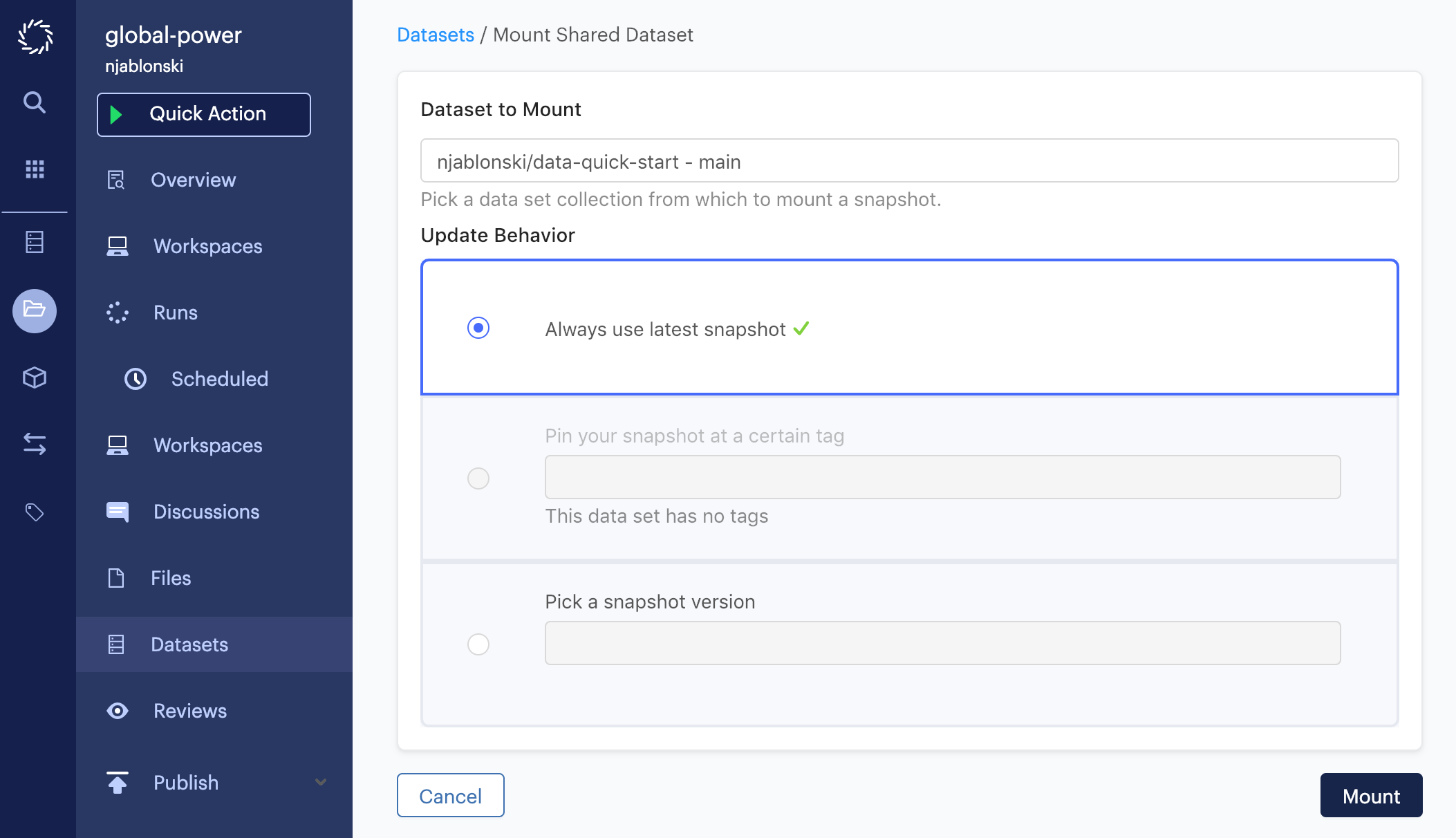
With the consuming project open, click Datasets from the project menu, then click Mount Shared Dataset.
The Dataset to Mount field is a dropdown menu that will show shared datasets you have access to.
In the above example, the main dataset from the data-quick-start project will be mounted at the latest snapshot.
Select the dataset that you migrated your data into earlier, then click Mount.
When finished, you will see the dataset you added listed under Shared Datasets. The Path column shows the path where the contents of the dataset will be mounted in this project’s runs and workspaces.
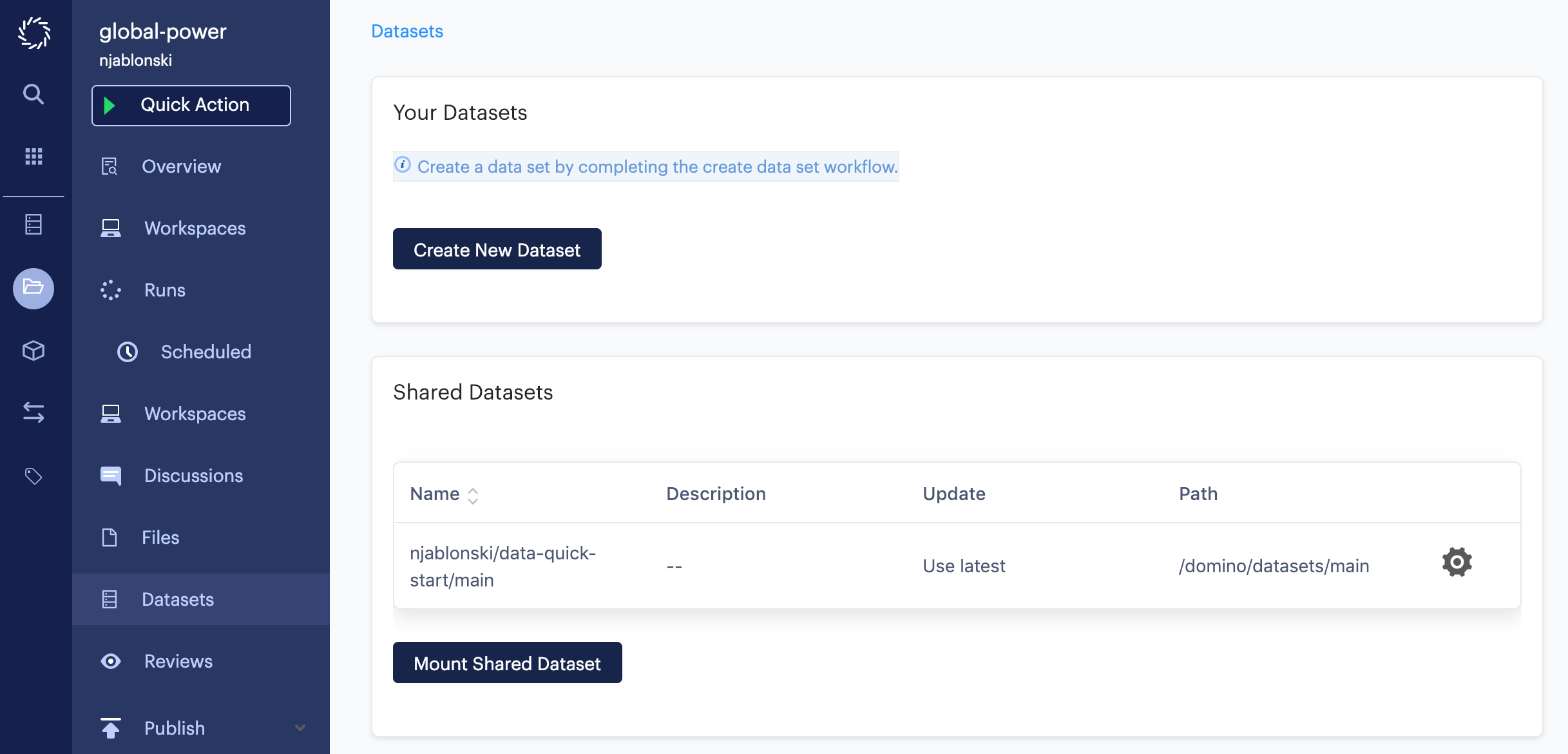
Remember that if you used the migration script shown earlier, the file structure at that path will be identical to the file structure of the imported legacy data set location. All you need to do to access the same data is change the path to this new Domino dataset mount.
Be sure to contact other users who are consuming your legacy data set and provide them with information about the new Domino dataset.