Ground truth data consists of known correct outputs for each input. Model quality monitoring compares the model’s predicted values against the actual results (or labels for the predictions) using ground truth data to generate quality metrics.
After you set up your model to capture prediction data, you can ingest the model’s ground truth data to monitor the quality of predictions made by the model. For this analysis, you must have declared a row_identifier column for the prediction data schema. This row_identifier column must also be present in the ground truth data to map a prediction uniquely to the ground truth.
When you apply a date filter, Domino uses the timestamp values in the prediction data to filter the results. Then, it matches the filtered predictions with the ground truth labels ingested in the last 90 days and calculates the model quality metrics for the matched predictions.
You can use the Domino application or a REST API to ingest ground truth data. See Model Monitoring APIs for details.
-
In the navigation pane, click Model Monitor.
-
Click the model for which you want to ingest ground truth data.
-
Click Model Quality.
NoteIf you want to do this from the Overview page, go to Add Data > Ground Truth Data. -
On the Model Quality page of the registered model, click Register Ground Truth > Upload Ground Truth Config.
In the Register Ground Truth window, you can upload a Ground Truth Config file or paste a JSON config. This JSON must capture all the information needed to register ground truth data.
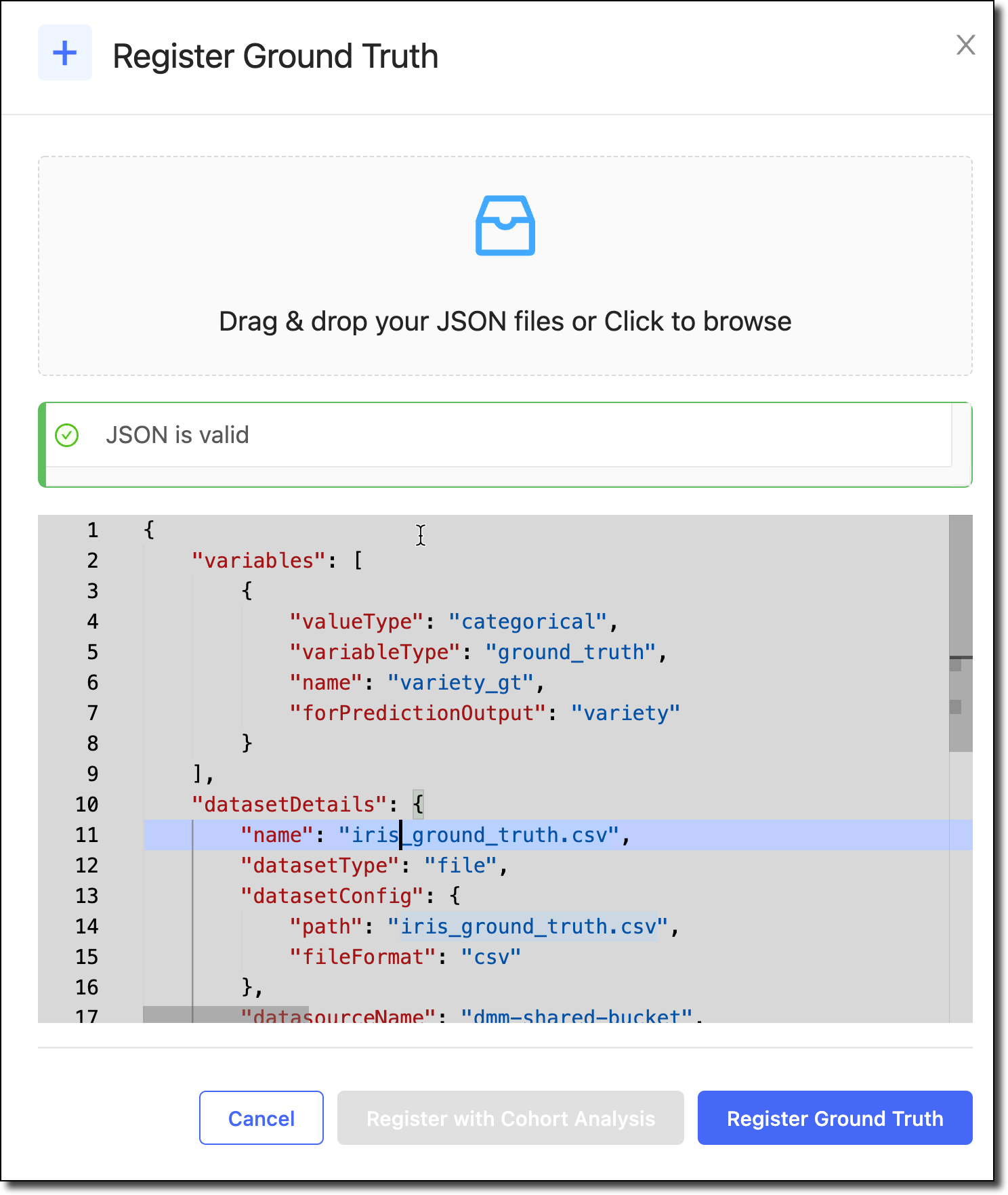
The following is a sample file. You must specify the target column, shown below as
y_gtand the row identifier that maps to a corresponding prediction record, shown below asgt_uuid. Note that your prediction dataset needs to have a column that contains unique row identifiers that match. When you registered your prediction dataset with Domino, you also supplied a variable that denotes therow_identifiersimilarly. The configuration must always include thedatasetDetailsandmodelMetadatainformation. See Monitoring Config JSON for details about each field in the JSON.{ "variables": [ { "name": "y_gt", "variableType": "ground_truth", "valueType": "categorical", "forPredictionOutput": "y" }, { "name": "gt_uuid", "variableType": "row_identifier", "valueType": "string" } ], "datasetDetails": { "name": "GT-labels.csv", "datasetType": "file", "datasetConfig": { "path": "GT-labels.csv", "fileFormat": "csv" }, "datasourceName": "abc-shared-bucket", "datasourceType": "s3" } } -
Click Register Ground Truth. On the Model Quality Analyze page, the Model Monitor starts to calculate model quality metrics for this dataset.
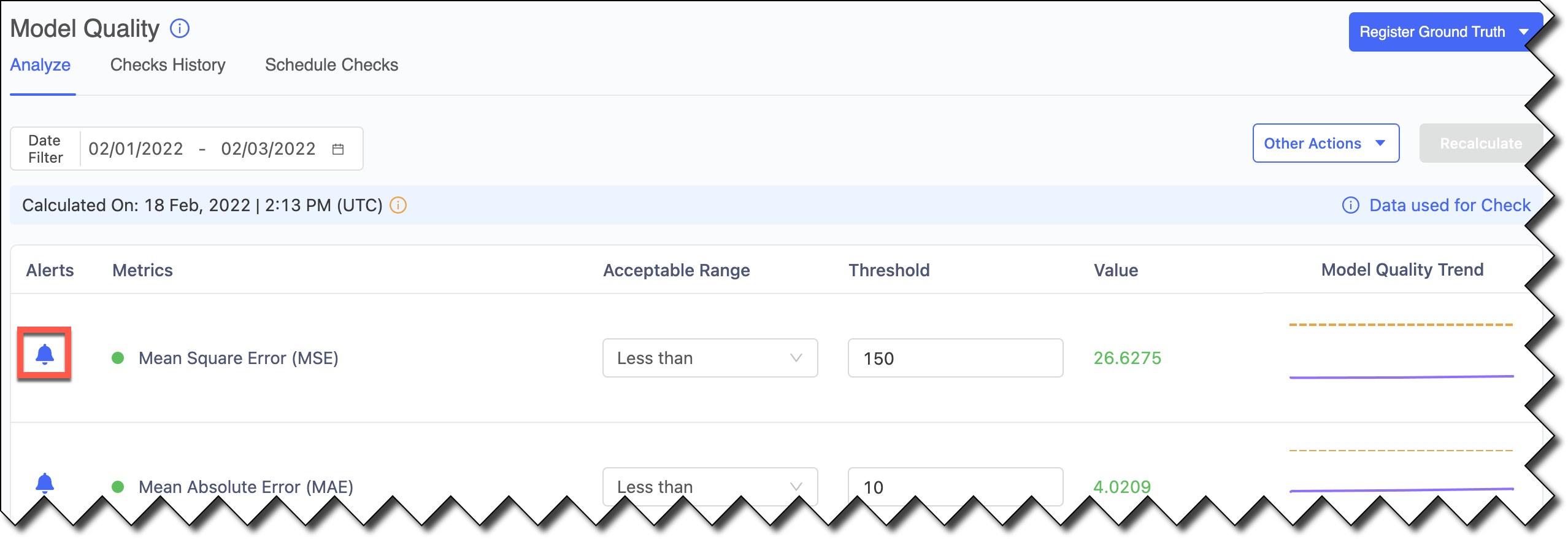
-
Click the bell icon to disable the alerts. Doing this reduces noise by controlling the metrics included in the Scheduled Checks.
Check the status of ground truth data
After you register the ground truth data for ingestion, you might want to check its status.
-
From the navigation pane, click Model Monitor.
-
Click the name of the model for which you set up ground truth data ingestion.
-
On the Overview page’s Data Traffic tab, you can see the history of the ingested data and review the model’s metadata and schema.
-
Click Ingest History to check to see if the status is
Done. The following are other statuses you might see:Completed with Warnings-
Click the three vertical dots at the end of the row and click View Details.
Failed-
Click the three vertical dots at the end of the row and click View Details.
If the ingestion failed, Domino stops the continuous ingestion. After you fix the issue, re-register the prediction data and Domino restarts continuous ingestion from this point.
NoteIf you re-register the same dataset, Domino processes the entire table again. This causes duplicate records which affects the drift and model quality calculations. Skipped-
The dataset had no rows to fetch.
You can click Status to select checkboxes to filter by status.
-
Click Refresh to see a graph of the Data Ingest Timeline.
After the data is ingested, you can perform an ad-hoc model quality analysis to validate your setup. Then, set up a schedule to perform model quality analysis automatically.