The following section covers the basic troubleshooting steps for common Workspace and Job issue scenarios.
When node pools have used all compute nodes specific with node pool’s max-nodes, Workspaces, Jobs, Apps, and Model APIs may not start at all. The following is an example error from a user’s logs:
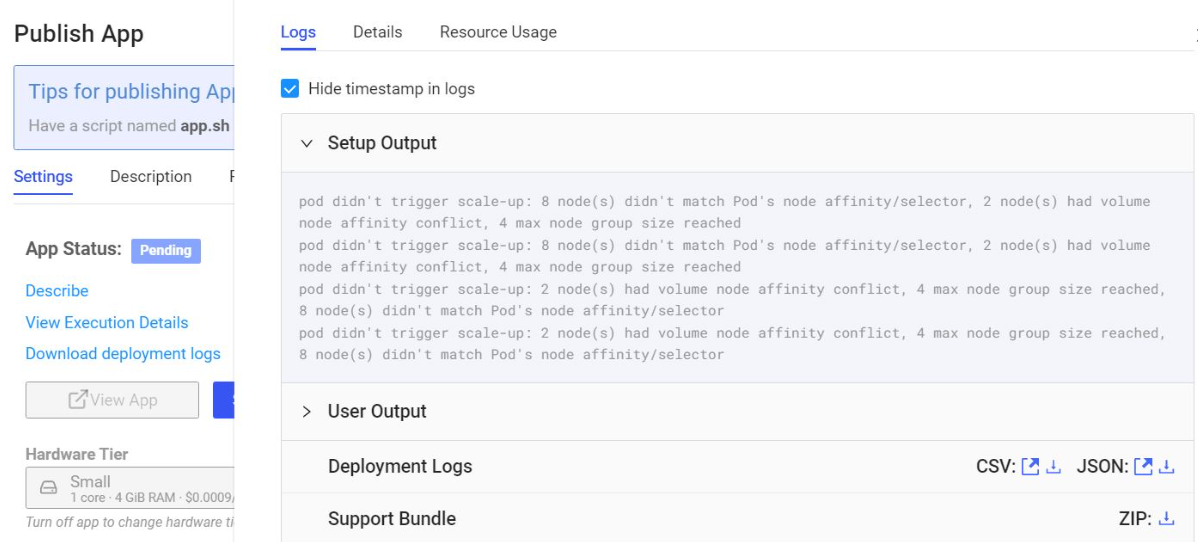
"description" : "pod didn't trigger scale-up: 8 node(s) didn't match Pod's node affinity/selector, 2 node(s) had volume node affinity conflict, 4 max node group size reached"The small-k8s hardware tier is mapped to the node pool with the nodeSelector: dominodatalab.com/node-pool: default. The message "8 node(s) didn’t match Pod’s node affinity/selector" means there are 8 nodes with room in terms of CPU/RAM, but they have different labels/selectors (for example they might be in a different node-pool than the one specified in the hardware tier chosen).
The message "2 node(s) had volume node affinity conflict" means the Autoscaling groups need to be set to one AZ per group. If they are not, this volume node affinity conflict will appear because the node (EC2 instance for example) and volume are in different availability zones.
The message "4 max node group size reached" means the scale-up cannot occur in four suitable (label-wise) node groups because they’re maxed out. Therefore the AWS ASG max-node size should be increased in this case.
Inspecting the Workspace and Job pod status from Kubernetes combined with Kubernetes events usually gives a good starting point for troubleshooting.
<user-id>$ prod-field % kubectl get pods -n domino-compute | egrep -v "Running"
NAME READY STATUS RESTARTS AGE
model-64484be8a7d82e39bb554a67-65fb5f9c48-7hlgd 3/4 CrashLoopBackOff 5755 (65s ago) 20d
<user-id>$ prod-field %Use the described pod commands to troubleshoot further root causes.
<user-id>$ prod-field % kubectl describe pod run-648b134573f8e83c8a3942ea-8m6bg -n domino-compute
Name: run-648b134573f8e83c8a3942ea-8m6bg
Namespace: domino-compute
Priority: 0
Node: ip-100-164-3-12.us-west-2.compute.internal/100.164.3.12
Start Time: Thu, 15 Jun 2023 09:33:59 -0400
<snip>
smarter-devices/fuse:NoSchedule op=Exists
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 64s default-scheduler Successfully assigned domino-compute/run-648b134573f8e83c8a3942ea-8m6bg to ip-100-164-3-12.us-west-2.compute.internal
Normal SuccessfulAttachVolume 61s attachdetach-controller AttachVolume.Attach succeeded for volume "pvc-40785798-8fc2-48a2-98b0-9ea64388dc82"
Normal Pulled 59s kubelet Container image "quay.io/domino/executor:5.6.0.2969129" already present on machine
Normal Pulled 58s kubelet Container image "172.20.87.71:5000/dominodatalab/environment:62bf7f682f6f27046aa8611d-11" already present on machine
Normal Started 58s kubelet Started container executor
Normal Pulled 58s kubelet Container image "quay.io/domino/openresty.openresty:1.21.4.1-6-buster-359055" already present on machine
Normal Created 58s kubelet Created container nginx
Normal Started 58s kubelet Started container nginx
Normal Created 58s kubelet Created container executor
Normal Created 58s kubelet Created container run
Normal Started 58s kubelet Started container run
Normal Pulled 58s kubelet Container image "quay.io/domino/credentials-propagator:v1.0.4-1277" already present on machine
Normal Created 58s kubelet Created container tooling-jwt
Normal Started 58s kubelet Started container tooling-jwt
Warning Unhealthy 56s kubelet Readiness probe failed: dial tcp 100.164.45.62:8888: i/o timeout
Warning Unhealthy 41s (x7 over 56s) kubelet Readiness probe failed: dial tcp 100.164.45.62:8888: connect: connection refusedMost of the troubleshooting requires Kubernetes and AWS dashboard access. However, there are cases where users or administrators might be able to gather information using the Domino UI.
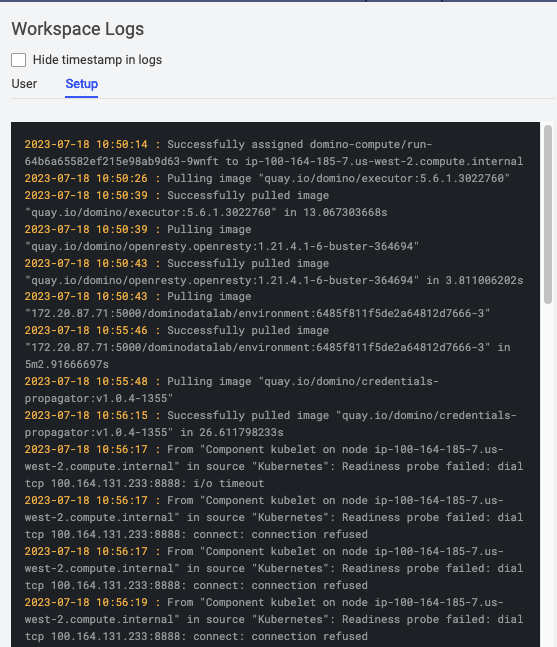
Workspace logs are an example of logs accessible to the users. There are two types of workspace logs:
-
Setup logs: Messages related to setting up the underlying compute infrastructure and pulling the compute environment images into Workspace Kubernetes pods.
-
User logs: Messages related to pre-run scripts, package install with a
requirements.txtfile, and other messages during the Workspace execution.
Support bundle
As an admin, there are additional logs available from the admin UI. The support bundle can also be downloaded from this section. The support bundle includes Workspace logs as well as logs from the Kubernetes resources.

The following sections provide useful steps to troubleshoot: