Domino implements MLflow to track and monitor experiments in R and Python. If you already use MLflow, you don’t have to change your code to use it in Domino. However, unlike standalone MLflow, Domino provides role-based access controls (RBAC) to limit access to sensitive information that could be leaked through logging values.
Logs let you evaluate different ML approaches, keep track of your team’s work, and help you make informed decisions. Learn how to:
-
Track experiments with auto and manual logging.
-
View and compare experiment runs.
-
Collaborate securely.
Domino’s MLflow integration is scoped on a per-project basis. Every Domino project comes pre-configured with its own MLflow server and environment variables.
Use the environment variables MLFLOW_TRACKING_URI and MLFLOW_TRACKING_TOKEN in your Domino Workspace or Job to log into the MLflow server.
print('MLFLOW_TRACKING_URI: ' + os.environ['MLFLOW_TRACKING_URI'])
print('MLFLOW_TRACKING_TOKEN: ' + os.environ['MLFLOW_TRACKING_TOKEN'])|
Note
| Domino stores experiment artifacts, data, and results in your project for reproducibility. Setting custom artifact locations isn’t supported. |
Auto logging
MLflow auto-logging is the easiest way to log your experiments. With auto-logging, MLflow logs the most critical parameters, metrics, and artifacts for you. However, MLflow only supports auto-logging for some libraries. See MLflow’s documentation to see the libraries that support auto-logging and the metrics they log.
This snippet shows you how to auto-log a sci-kit learn experiment.
# import MLflow library
import mlflow
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
# create and set a new experiment
mlflow.set_experiment(experiment_name="Domino Experiment")
# enable auto-logging
mlflow.autolog()
# start the run
with mlflow.start_run():
db = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(db.data, db.target)
rf = RandomForestRegressor(n_estimators = 100, max_depth = 6, max_features = 3)
rf.fit(X_train, y_train)
rf.score(X_test, y_test)
# end the run
mlflow.end_run()Manual logging
You can also use MLflow’s manual logging to specify custom logs. The following code snippet shows you how to log run parameters and metrics manually:
# import MLflow library
import mlflow
# create a new experiment
mlflow.set_experiment(experiment_name="Domino Experiment")
# start a run and log parameter and metric
with mlflow.start_run():
mlflow.log_param("batch_size", 32)
mlflow.log_metric("accuracy", 0.75)
# end the run
mlflow.end_run()For more information and MLflow examples, see MLflow’s official documentation site.
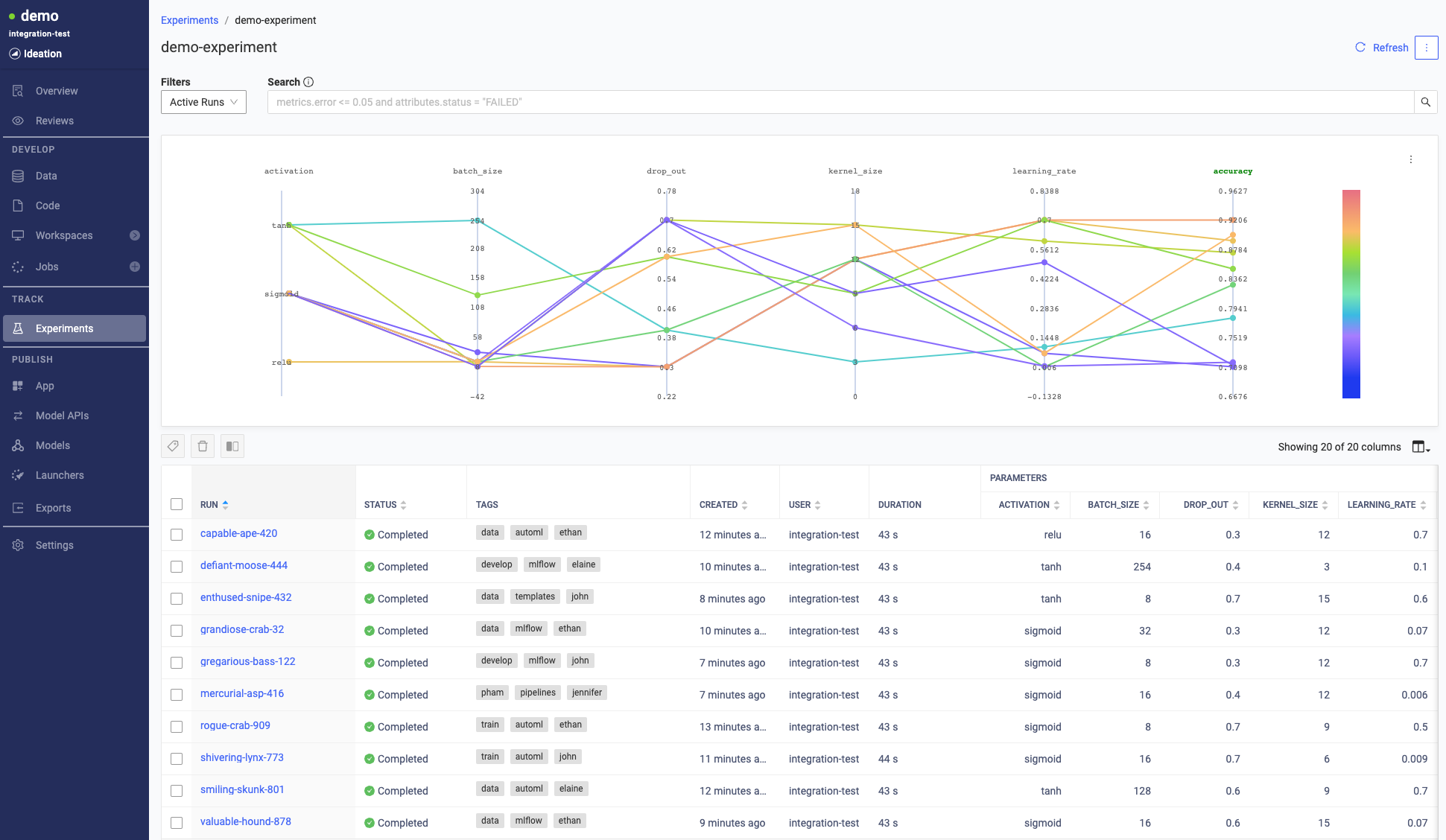
After you log your experiments, use Domino to view and evaluate the results.
-
To find your experiment, click Experiments in Domino’s left navigation pane.
TipYou can also tag experiments to make searches easier. -
Click an experiment to show all its associated runs.
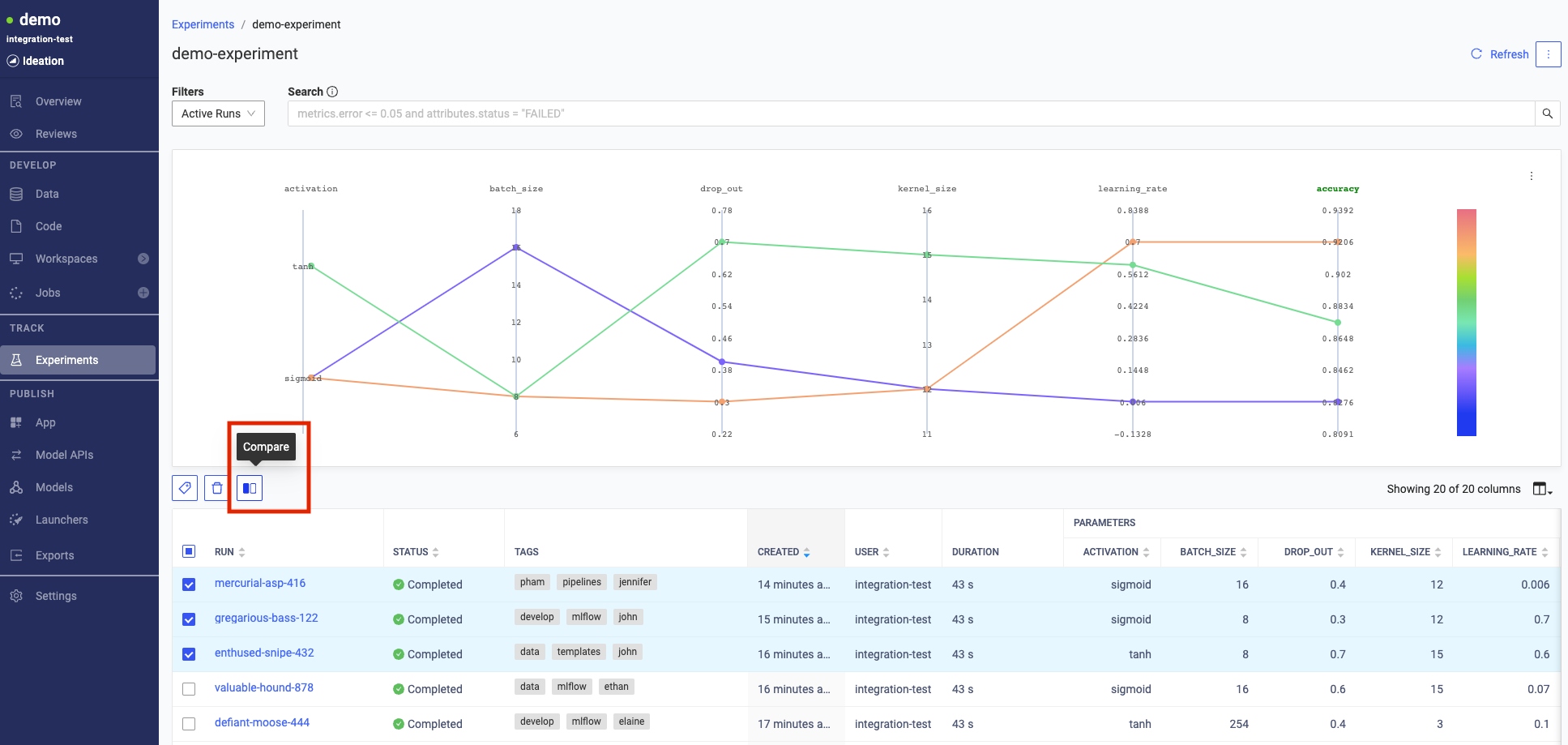
Compare runs to see how parameters affect important metrics like model accuracy or training speed. Use logs to inform your approach and select models.
-
Select up to 4 runs from the table view.
-
Click the compare button.
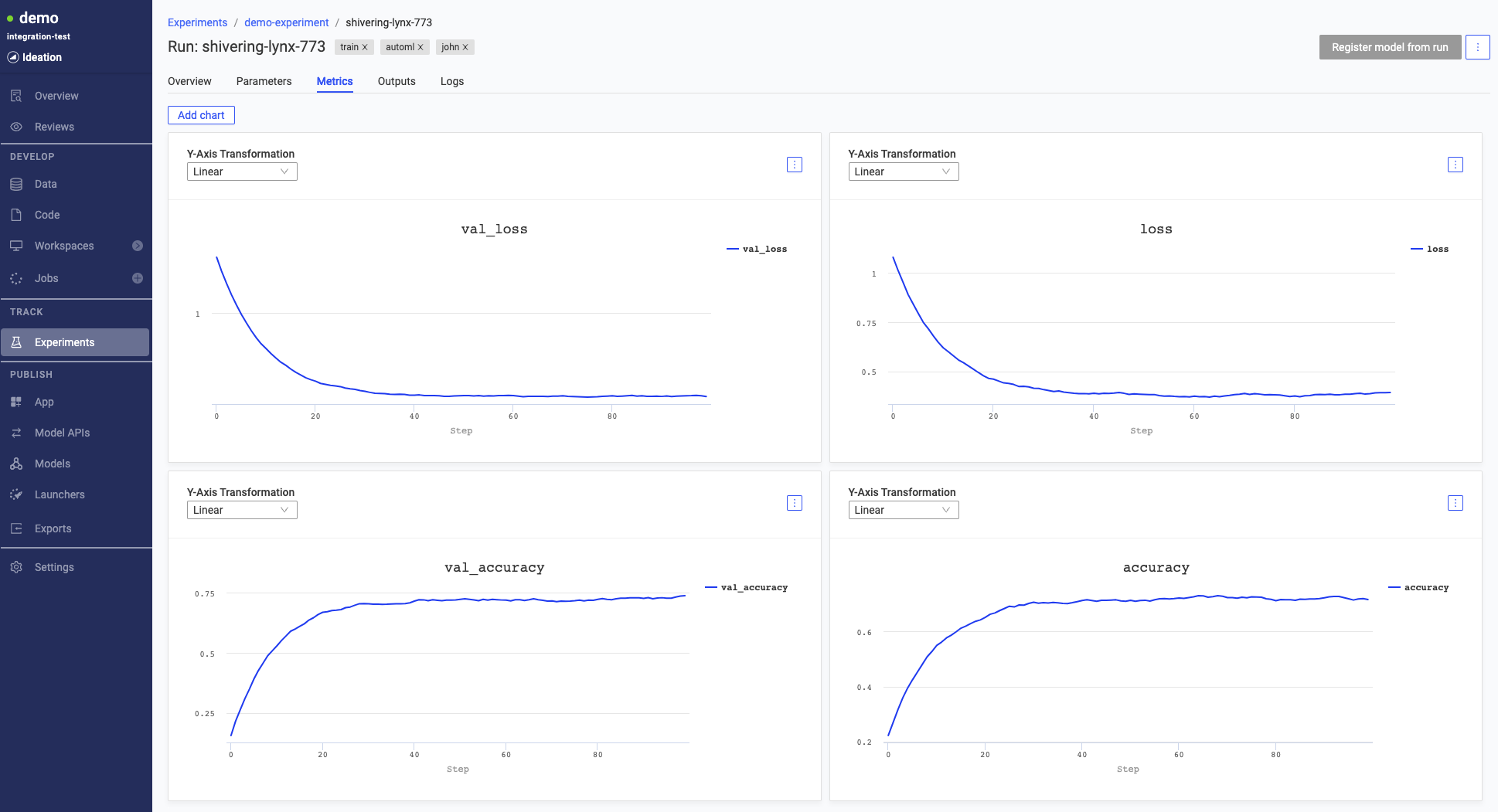
Click a run to analyze the results in detail and find reproducibility information.
Unlike standalone MLflow, Domino uses RBAC for added security. Use project-level access controls to set permissions for experiment assets including MLflow logs.
At the project level, use these methods to control access:
-
Set your project visibility to private, searchable, or public to define coarse-grain visibility controls for the entire project.
-
Invite collaborators and set their collaborator permissions with project roles for fine-grain of control over what project collaborators can access.
|
Note
| Domino stores experiment artifacts, data, and results alongside the project to ensure reproducibility. Users with project view access see the artifacts, data, results, and logs for all experiments within the project. |
Starting with Domino 5.11.1, you can now upload large artifact files directly to blob storage without needing to go through the MLflow proxy server. This is an experimental feature that must be enabled inside user notebook code by setting the environment variable MLFLOW_ENABLE_PROXY_MULTIPART_UPLOAD to true.
import os
os.environ['MLFLOW_ENABLE_PROXY_MULTIPART_UPLOAD'] = "true"This feature is useful for both log_artifact calls and registering large language models. It is currently supported only in AWS and GCP environments. There are 2 additional settings available for configuring this feature:
-
MLFLOW_MULTIPART_UPLOAD_MINIMUM_FILE_SIZE- the minimum file size required to initiate multipart uploads. -
MLFLOW_MULTIPART_UPLOAD_CHUNK_SIZE- the size of each chunk of the multipart upload. Note that a file may be divided into a maximum of 1000 chunks.
See the MLflow multipart upload for proxied artifact access documentation for further details.
-
Experiment names must be unique across all projects within the same Domino instance.
-
When you delete a run that has child runs, the child runs aren’t deleted. Delete the child runs separately.
-
You cannot stop a run from the UI. To stop a run, execute mlflow.end_run() from your workspace or job.
-
Get started with a detailed tutorial on workspaces, jobs, and deployment.
-
Scale-out training for larger datasets.