Domino is distributed as a set of containerized, Kubernetes native applications. A set of accompanying Helm charts and an installer is used to manage Domino installation and upgrades. Domino is validated on major Kubernetes services in the public cloud (EKS, AKS, and GKE). It is also possible to run Domino in self-managed Kubernetes environments in your private data center.
The following diagram shows Domino’s conceptual architecture.
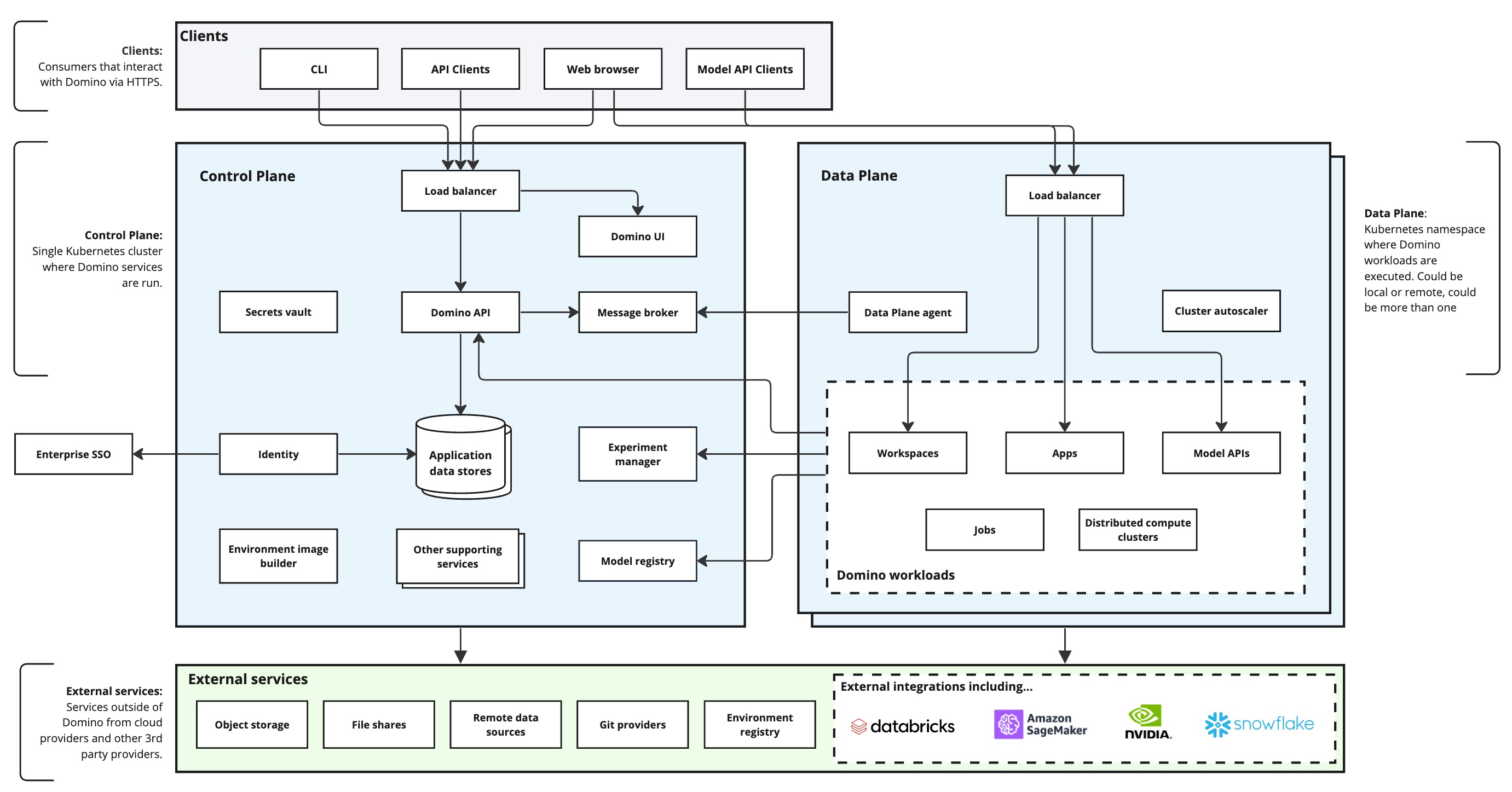
The Domino application is separated into three primary areas of concern:
- Clients
-
External clients interact with Domino via HTTPS. Clients can take the form of a command-line interface, web browsers, and programmatic API clients (including Domino endpoint clients).
- Control Plane (Platform)
-
The Domino control plane houses platform components including the Domino UI server, Domino API server, container orchestration, storage of metadata, and various supporting services.
- Data Plane (Compute)
-
The Domino data plane is where user workloads are run including machine learning and AI Jobs, models, Apps, and data science Workspaces.
The remainder of this page describes various services and the role they play.
The following services run in the Control Plane:
- Domino UI
-
A Node.js web server that serves a single-page React application to clients using web browsers. Primary users include data science practitioners and Domino admins.
- Secrets Vault
-
Storage for sensitive data including credentials, tokens, certificates, and API keys.
- Domino API
-
Exposes API endpoints that handle REST API requests from various clients (CLI, web browser, programmatic clients).
- Message Broker
-
A message broker (RabbitMQ) facilitating asynchronous communication between Domino services.
- Identity
-
Domino’s authentication service used for storing user identities and properties. Identity federation to SSO systems and third party identity providers is possible.
- Application Data Stores
-
Various application databases (e.g. MongoDB, PostgreSQL) store Domino metadata including Projects, users, and organizations. Application data stores can store references to blob storage stored in object storage systems (e.g. Amazon S3).
- Experiment Manager
-
Track and monitor data science experiments with logging, view and compare across experiments, and collaborate securely.
- Environment Image Builder
-
The Image Builder is capable of building Domino Environments, based on Docker containers. These Environments can include user-specified libraries needed to support data science work. It also builds Domino endpoint images.
- Model Registry
-
Discover and track models, record model metadata for auditability and reproducibility, and handle model versioning.
The following services run in the Data Plane cluster(s):
- Data plane agent
-
Applies resource changes to remote data planes. Responsible for running workloads on remote clusters.
- Cluster Autoscaler
-
Adds additional compute capacity to the cluster dynamically based on resource requirements (e.g. CPU, memory, GPU).
- Domino Workspaces
-
Used for housing interactive data science Environments (e.g. Jupyter Notebooks). Implemented as ephemeral pods that must be synced to long-term storage.
- Domino Apps
-
User-defined web applications able to serve user requests, hosted within Domino.
- Domino endpoints
-
Model inference endpoints hosted within Domino. Implemented as ephemeral pods.
- Domino Jobs
-
Short-lived batch Jobs run by Domino. Implemented as ephemeral pods.
- Distributed Compute Clusters
-
Use clustered compute environments to scale out compute-intensive workloads in Domino.
The following services execute outside of Domino clusters:
- Object Storage
-
Object (blob) storage, used for durably storing logs, container images, Domino backups, and various user data.
- File shares
-
File-based storage, used to store Domino entities like Datasets.
- Remote data sources
-
Pull data residing in remote data sources into data science environments.
- Git providers
-
Domino uses Git to revision projects and files. Git clients residing in the data plane can also be used to interact with external repositories to access code or data.
- Environment registry
-
Select from a catalog of predefined and user-defined Environments containing libraries needed to support data science.
-
Set up Domino on a Kubernetes cluster provided by:
-
Deploy workloads across multiple Kubernetes clusters with Domino’s Nexus Hybrid Architecture.
-
Find out more about Domino’s on-premises deployment service architecture.
-
Learn about how Domino uses Keycloak to manage user accounts.