The following selection of dashboards are provided with Domino to help you monitor the health of the Domino platform and the underlying Kubernetes cluster and infrastructure. There are other useful dashboards available in Grafana that aren’t listed here. They can all be used as-is or modified to suit your specific requirements. Note that in some cases not all panels on the dashboards are shown in the examples below for brevity.
Example of the Domino / Views / Workloads dashboard
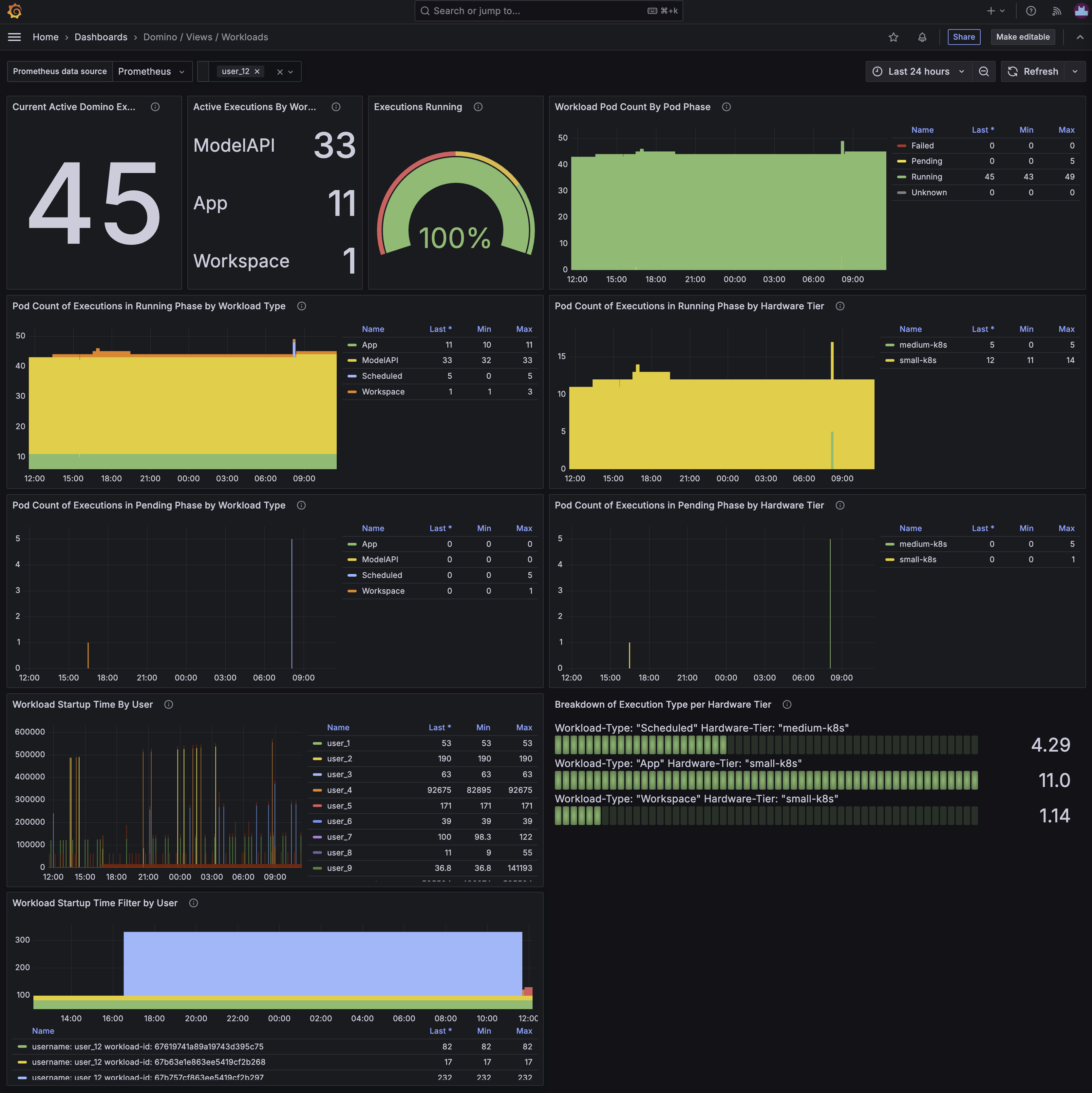
The Domino / Views / Workloads dashboard shows the status of all workloads running on the Domino platform. It includes information about the number of workloads in each state, the number of workloads that have failed, and the number of workloads that are currently running. You can use this dashboard to help understand the overall utilization of the Domino platform and to identify any workloads that may be stuck or failing.
Current Active Domino Executions | Active Executions By Workload Type | Executions Running
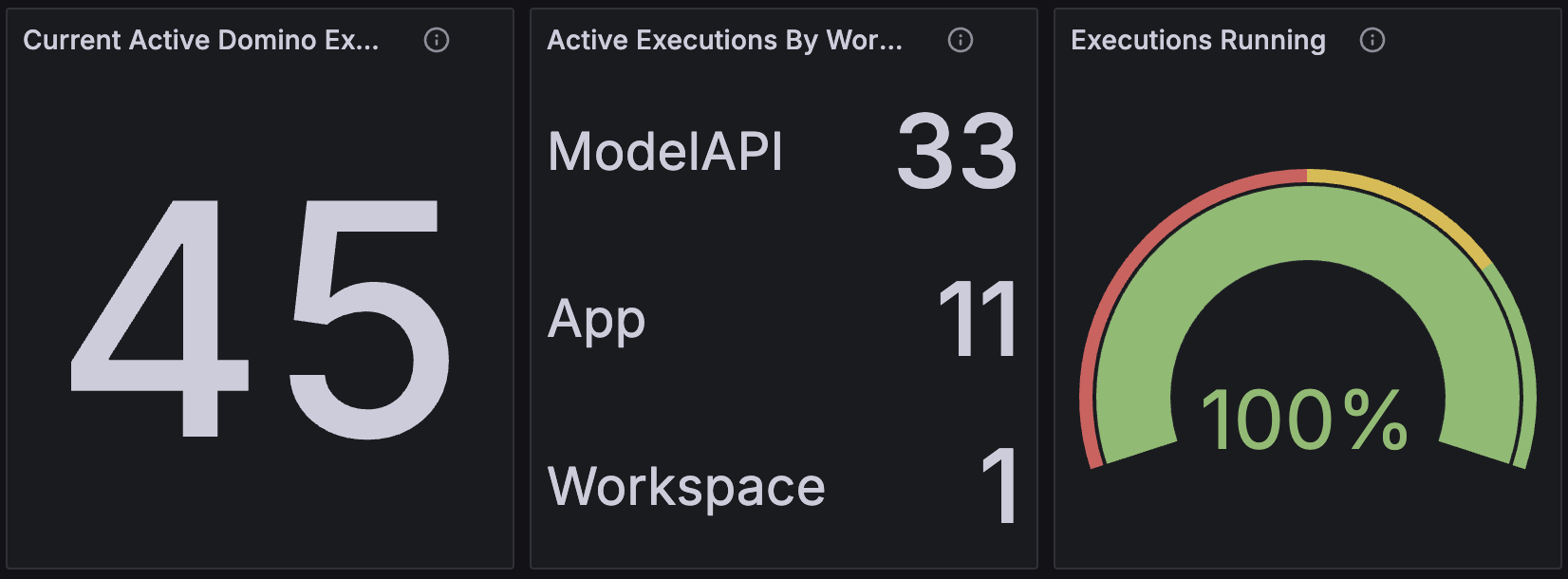
These three panels, in order, show:
-
The number of workloads of all types that are currently running on the Domino platform.
-
A breakdown of the workloads by type.
-
The ratio of workloads of all types in the running versus non-running state.
Workload Pod Count By Pod Phase
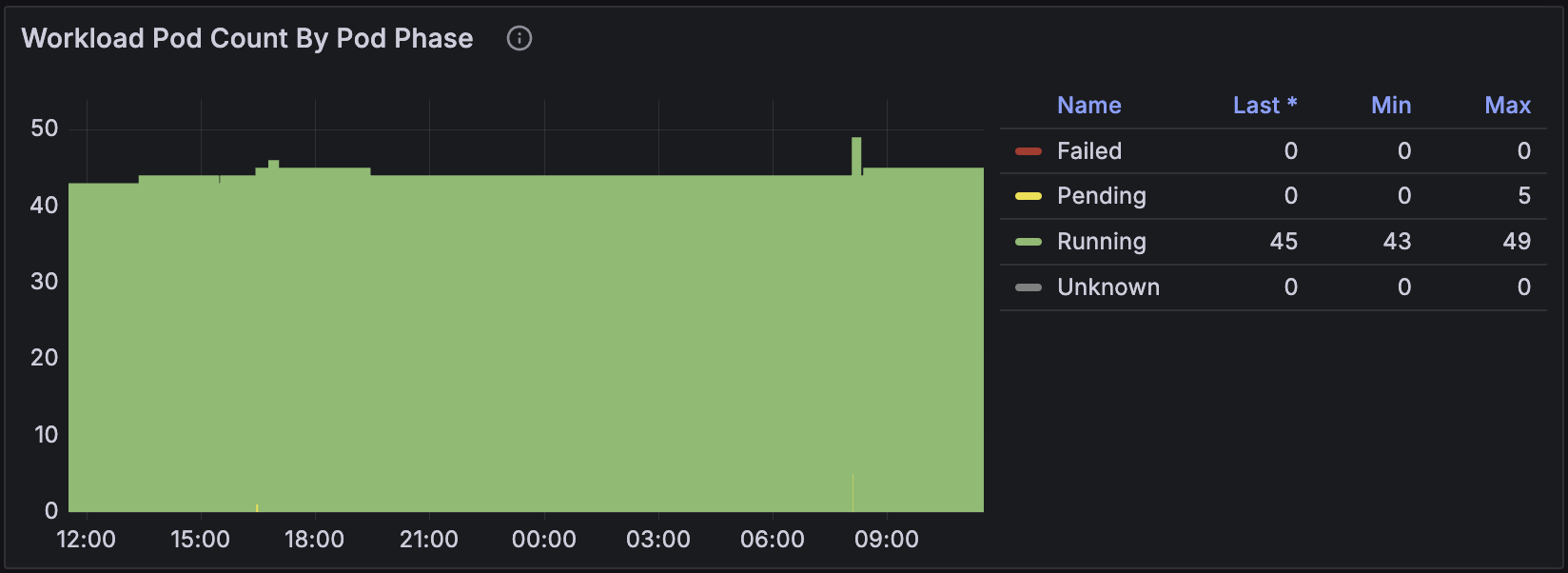
This panel shows the number of pods in each phase of the Kubernetes pod lifecycle for all workloads on the Domino platform. The phases are Pending, Running, Succeeded, and Failed. If many pods are in the Pending state, it might indicate that the Kubernetes cluster is under-provisioned. Lots of pods in the Failed state can indicate a problem with the workload itself or with the underlying infrastructure.
Pod Count of Executions in Running Phase by Workload Type | Pod Count of Executions in Running Phase by Hardware Tier

These two panels show the number of workload pods in the Running phase for each workload type and hardware tier. The first panel gives an indication of the distribution of workloads across different types, while the second panel shows how the workloads are distributed across different hardware tiers.
Pod Count of Executions in Pending Phase by Workload Type | Pod Count of Executions in Pending Phase by Hardware Tier

Similarly to the previous two panels showing workload pods in the Running phase, these two panels show the number of workload pods in the Pending phase for each workload type and hardware tier. This can help you understand the distribution of workloads that are waiting to be scheduled and detect problems with starting particular workload types, or issues with certain hardware tiers. On busy deployments a workload pod will need to wait for the cluster autoscaler to provision a node before it can be scheduled, so many pods in the Pending state can indicate that the cluster is under-provisioned.
Workload Startup Time By User | Workload Startup Time Filter by User
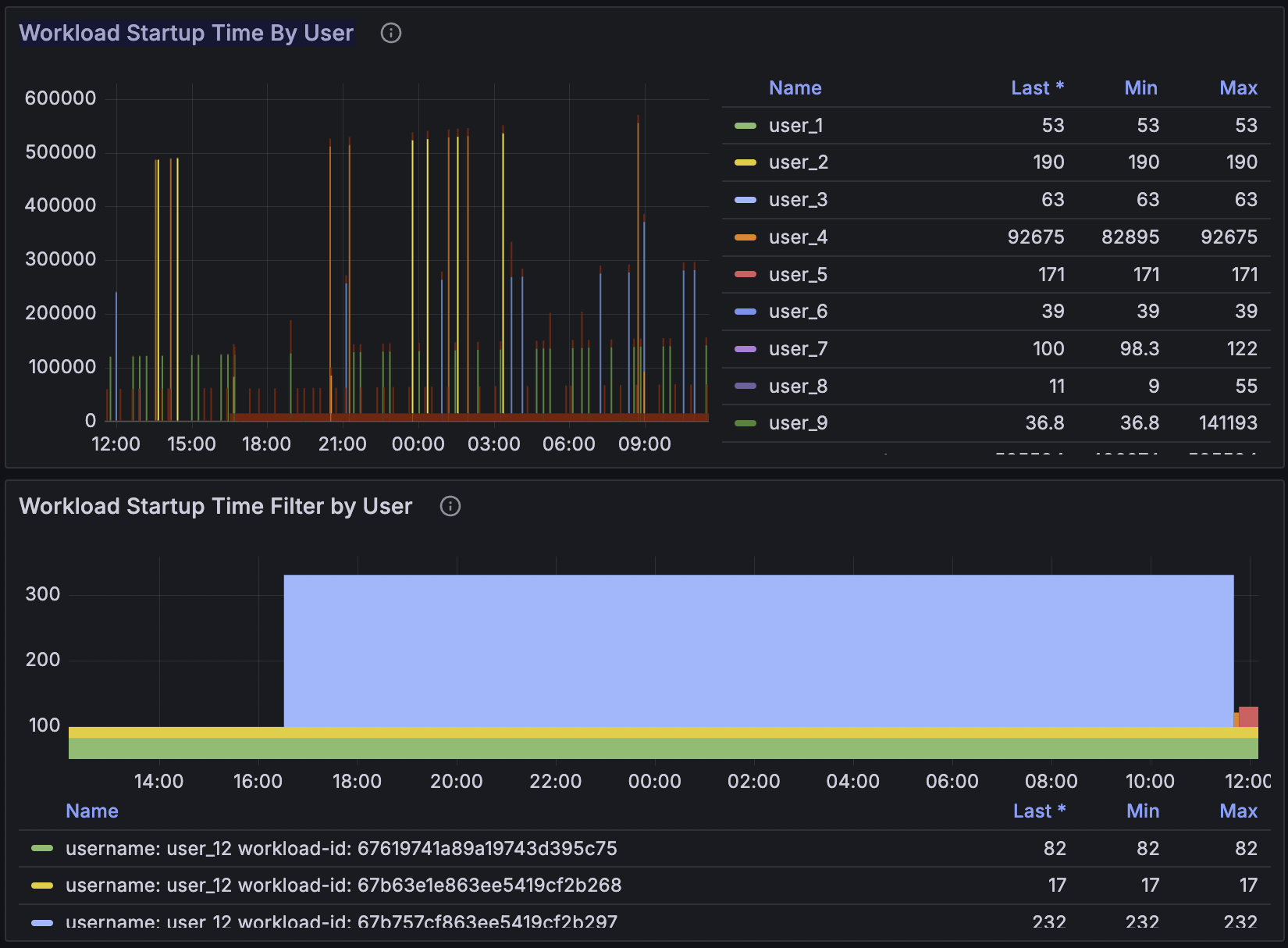
The next couple of panels show the average startup time of workloads on the Domino platform, broken down by user, and the start up times for all workload pods for a particular user as selected using the filter at the top of the dashboard.
This can help you identify if slow startup times are affecting a particular user or group of users, and whether it is a recent issue or a long-standing one.
Domino Execution Overview
Example of the Domino Execution Overview dashboard
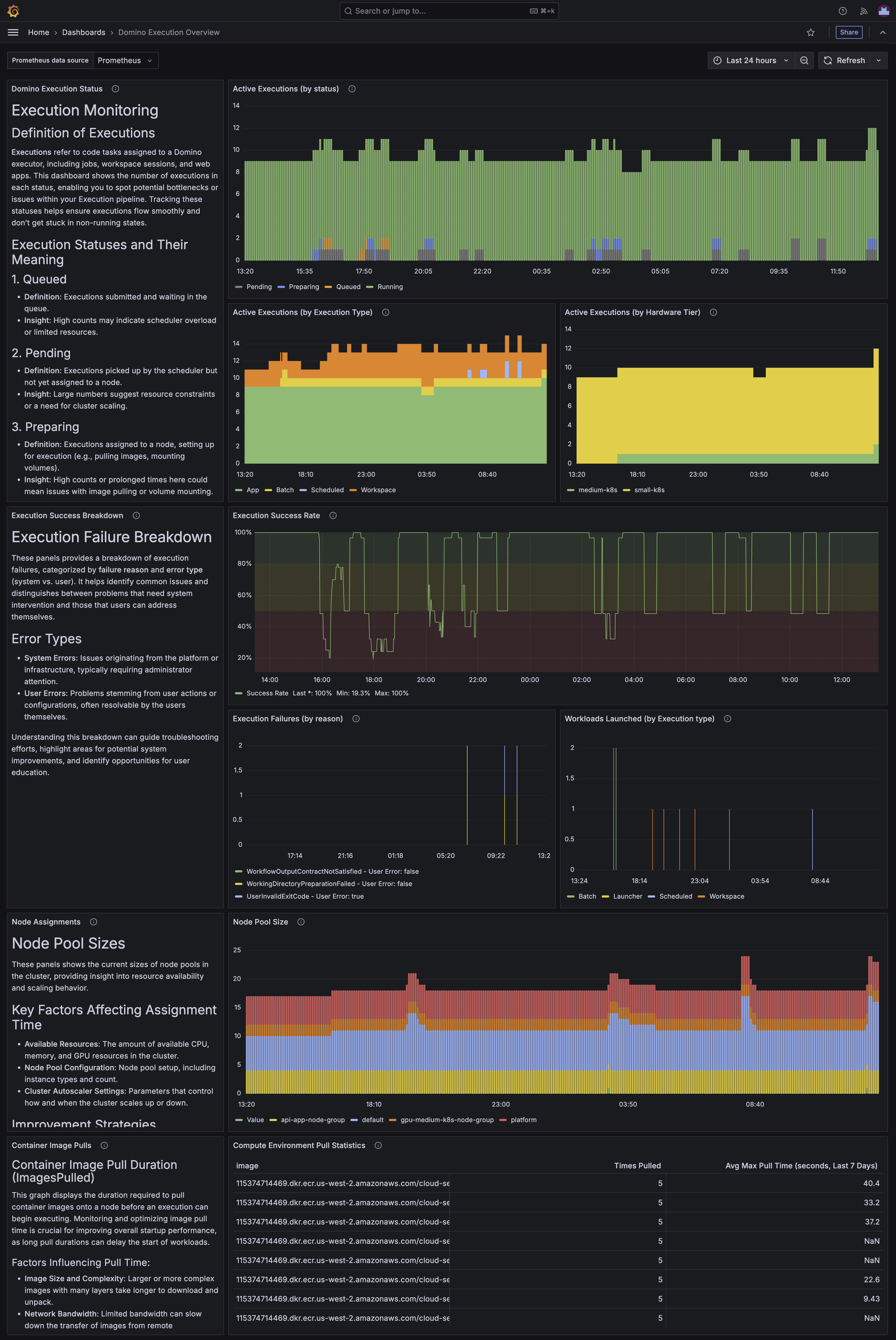
The Domino Execution Overview dashboard, like the Domino / Views / Workloads dashboard, provides an overview of the workloads running on the Domino platform. However, it provides more granular detail, including some new Domino metrics, rather than relying on Kubernetes metrics that don’t know anything about the application running on top of the cluster.
Active Executions (by status) | Active Executions (by Execution Type) | Active Executions (by Hardware Tier)
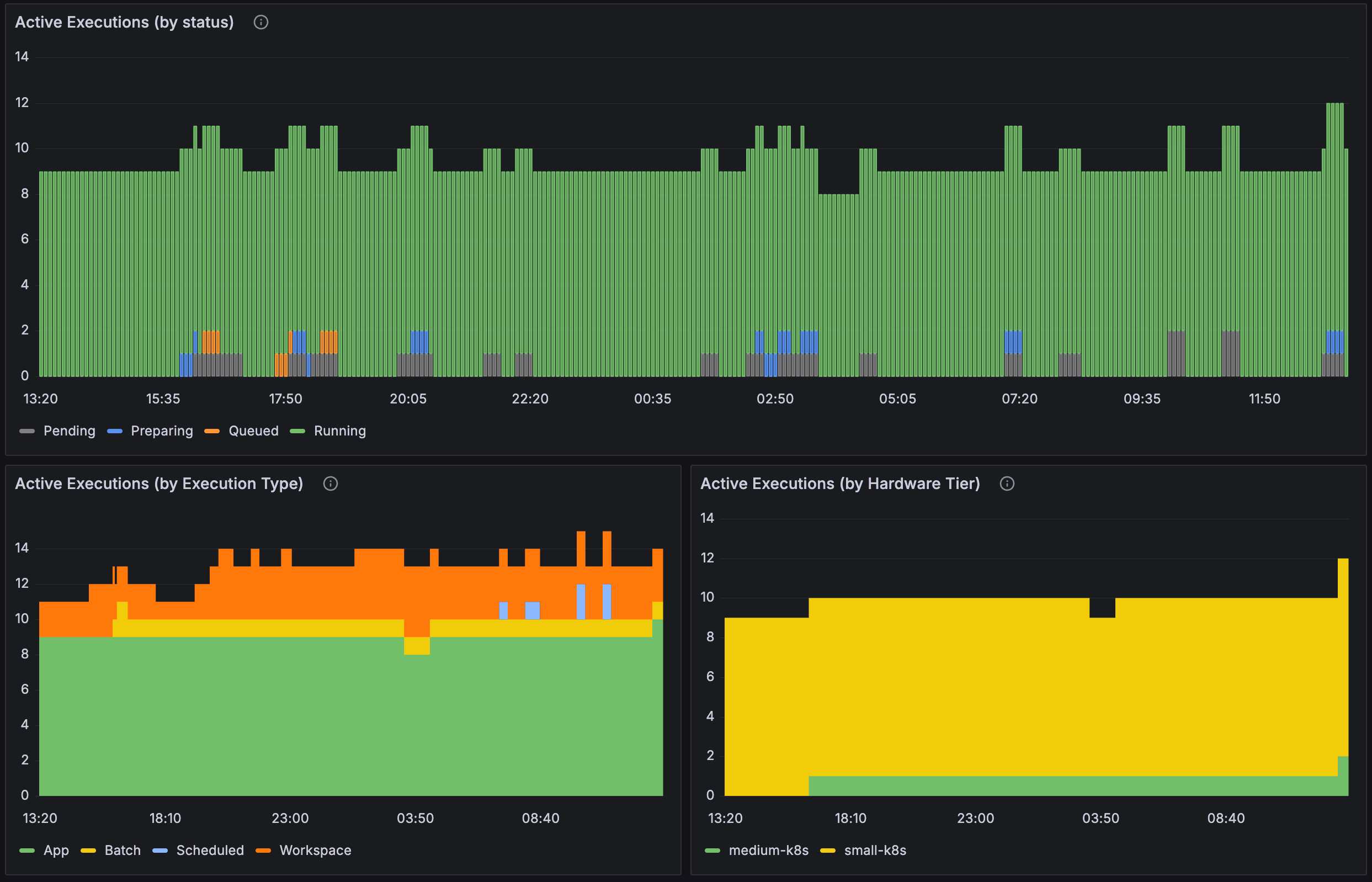
These three panels show the number of active executions on the Domino platform broken down by status, execution type, and hardware tier. This can help you understand the distribution of workloads across types and hardware tiers and spot potential bottlenecks or issues with particular types of workloads.
Execution Success Rate | Execution Failures (by reason) | Workloads Launched (by Execution type)
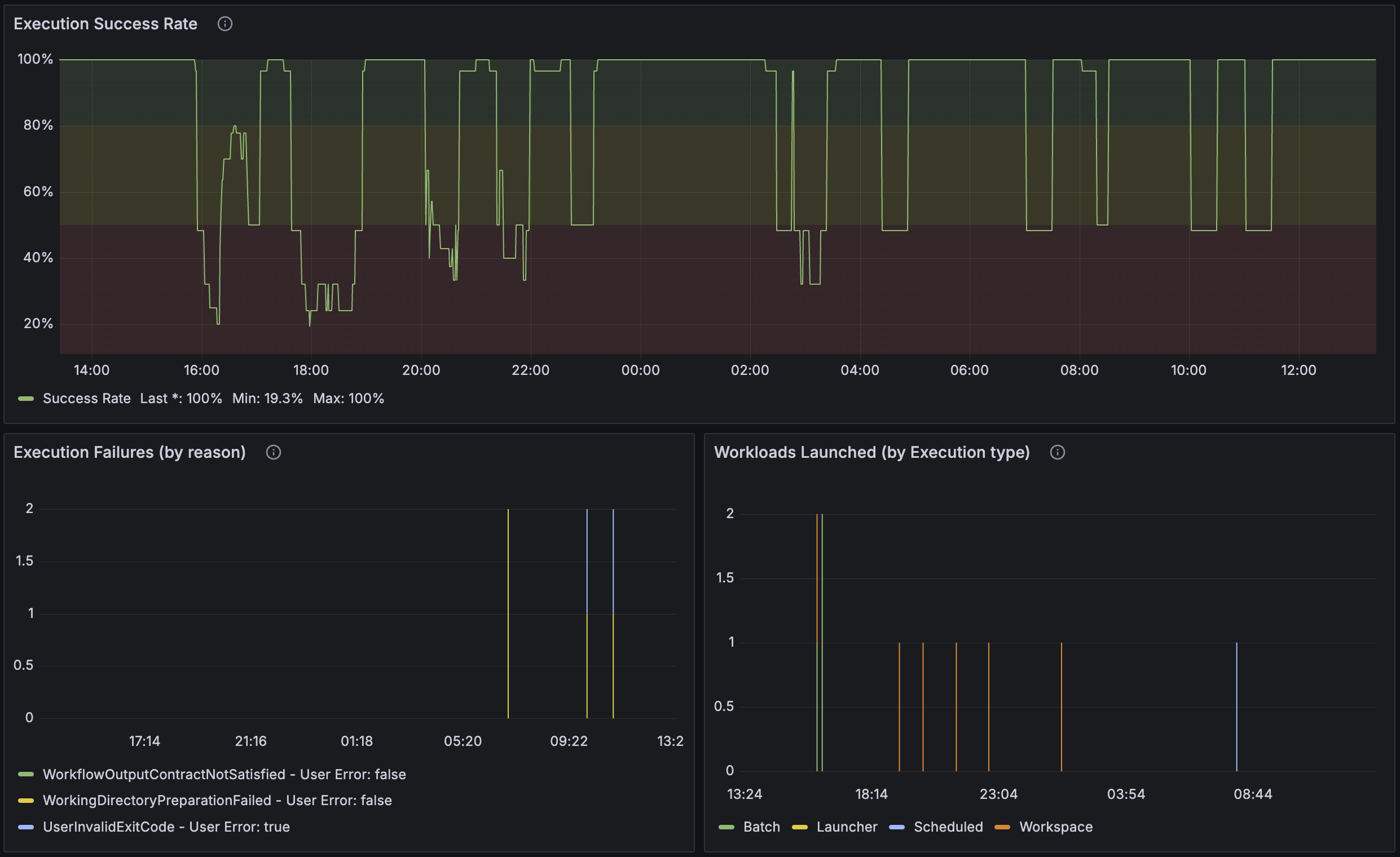
The Execution Success Rate panel shows the percentage of successful executions. An execution can fail for many reasons, not all of which are related to platform health. To determine which execution failures might be a platform issue, the Execution Failures (by reason) panel breaks down the failures by specific cause which boils down to whether or not the failure was a system error or a user error.
The Workloads Launched (by Execution type) panel shows the number of workloads launched by type over time.
Node Pool Size
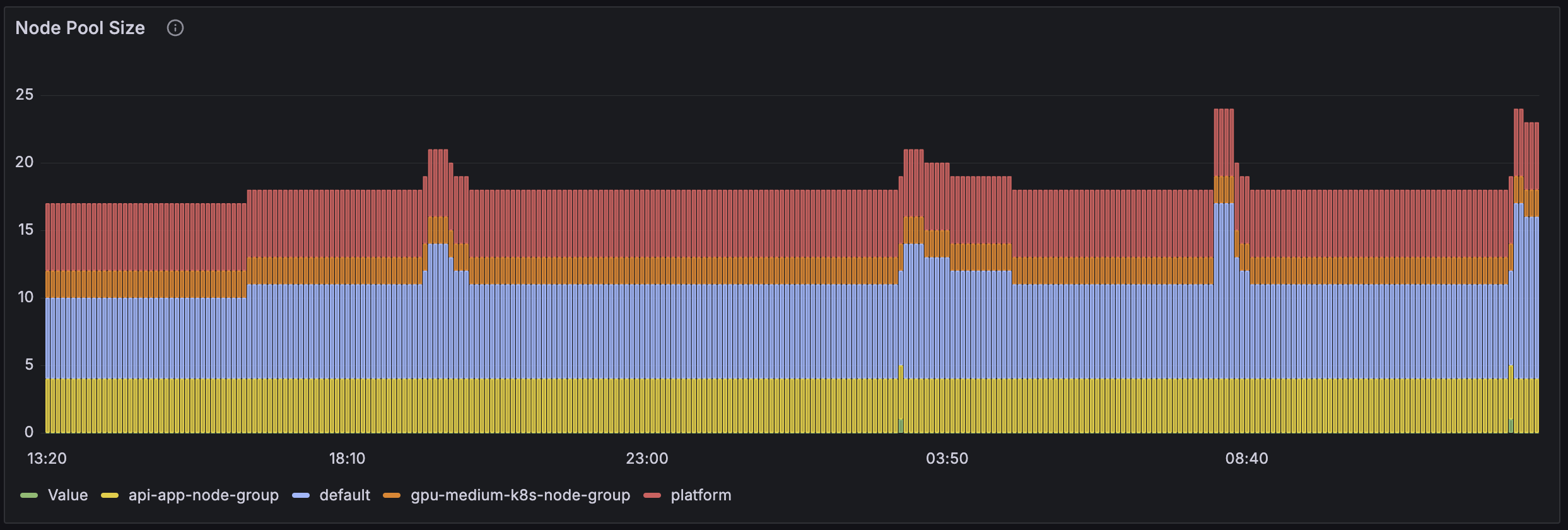
The Node Pool Size panel shows the number of nodes in each node pool over time. This panel helps you assess and adjust node pool configurations to improve job assignment times and overall cluster performance.
Compute Environment Pull Statistics
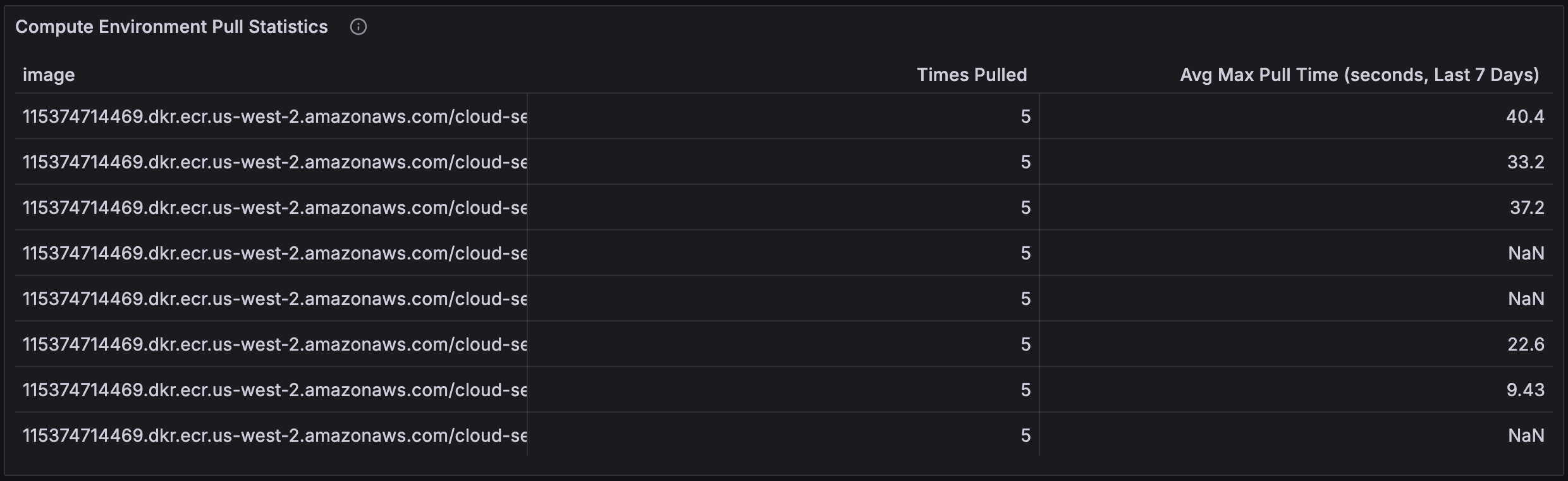
The Compute Environment Pull Statistics panel shows the number of times each compute environment image has been pulled and the average maximum time taken for the pulls. This can help you understand the performance of the image pull process and identify any images that are taking a long time to pull. Factors that can influence image pull time are the size of the image, the speed of the network connection, and whether the image is already cached on the node it is required on.
Example of the NGINX Ingress Controller dashboard
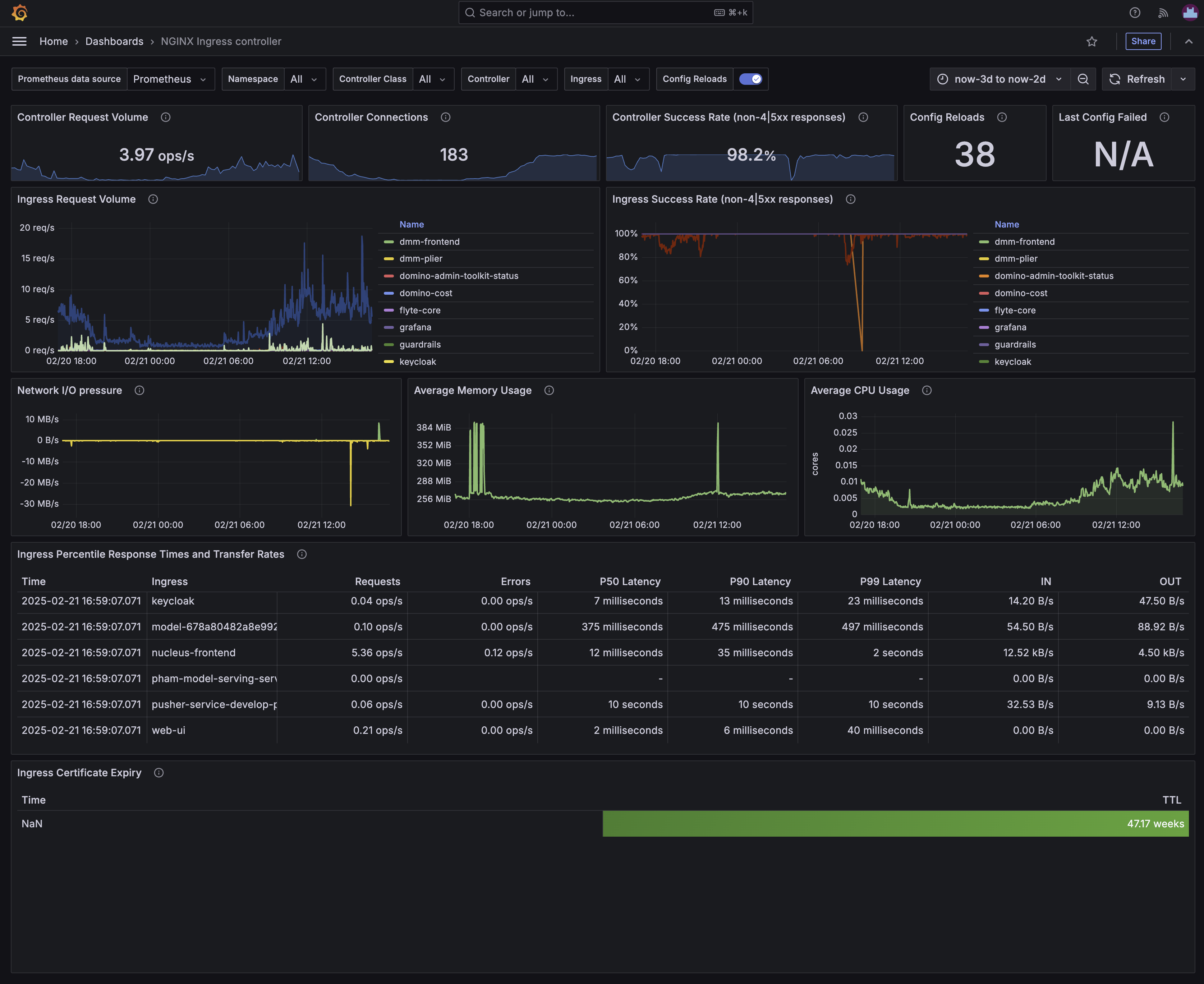
The NGINX Ingress Controller dashboard provides an overview of the NGINX Ingress Controller that is used to route traffic to the various services in the Domino platform. The dashboard is divided into several sections that provide information on the health of the NGINX Ingress Controller, the number of requests it is handling, the response times and status of those requests, and the latency of the various routes handled by the controller.
Dashboard filters

The dashboard includes a number of filters that let you select the namespace, ingress class, ingress name, and ingress route that you want to view metrics for. This can be useful if you have multiple ingresses in your deployment and want to focus on a specific one, or to inspect specific routes through the ingress controller.
The Config Reloads filter, when selected, displays metrics across all configuration changes for the selected controller. Deselecting this only shows metrics since the last configuration change.
Controller Request Volume | Controller Connections

These two panels show the number of requests and new connections that the NGINX Ingress Controller is handling over time. The Controller Request Volume panel shows the number of requests per second, while the Controller Connections panel shows the number of connections to the controller. These can be useful for understanding the load coming in to the Domino platform. If the number of requests is high, it might indicate that the platform is under heavy load, while a high number of connections might indicate that the platform is under attack. A breakdown of which routes are receiving the most traffic can be found in the Ingress Request Volume panel.
Ingress Request Volume
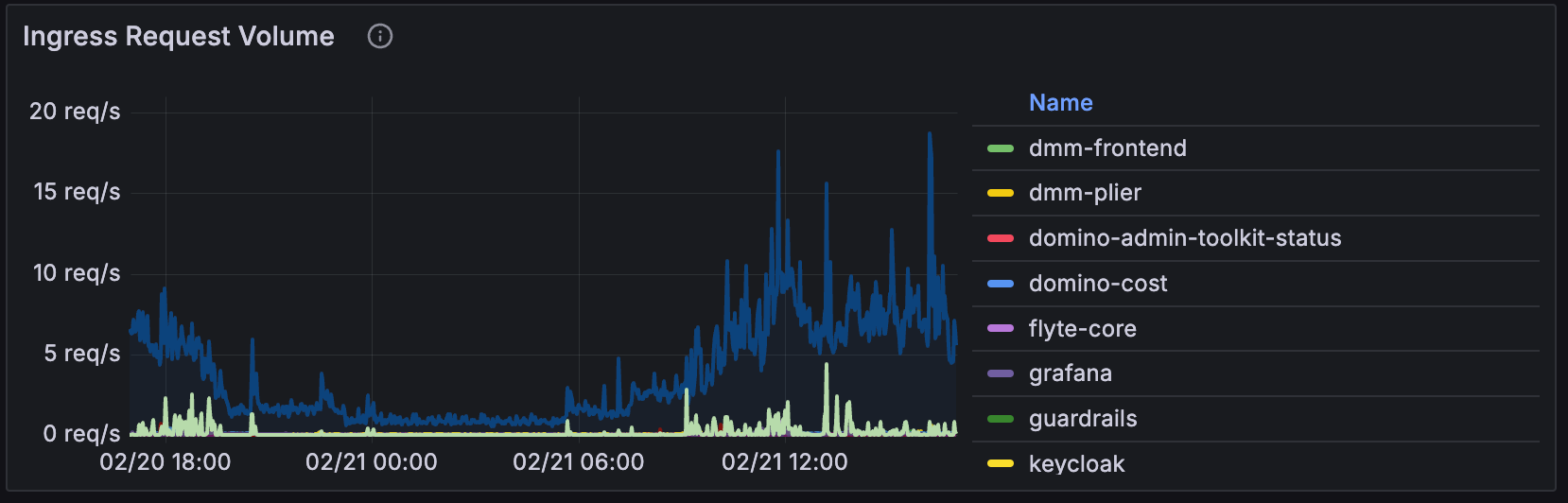
The Ingress Request Volume panel shows the number of requests that the NGINX Ingress Controller is handling for each route. This can help you understand which routes are receiving the most traffic and might need to be scaled up or down. If a particular route is receiving a lot of traffic, it might be a good idea to check the health of the service behind that route to ensure that it can handle the load.
Controller Success Rate
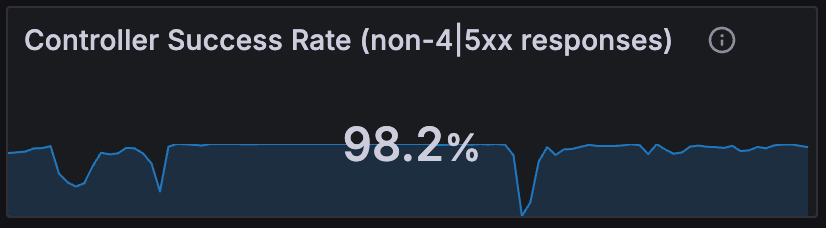
The percentage of successful requests that the NGINX Ingress Controller is handling is shown in the Controller Success Rate panel. A high success rate is generally a good sign, but a low success rate might indicate that there are problems with the services behind the controller, or that the controller itself is having issues. The Ingress Success Rate panel shows the success rate per route for more detailed investigation.
Ingress Success Rate
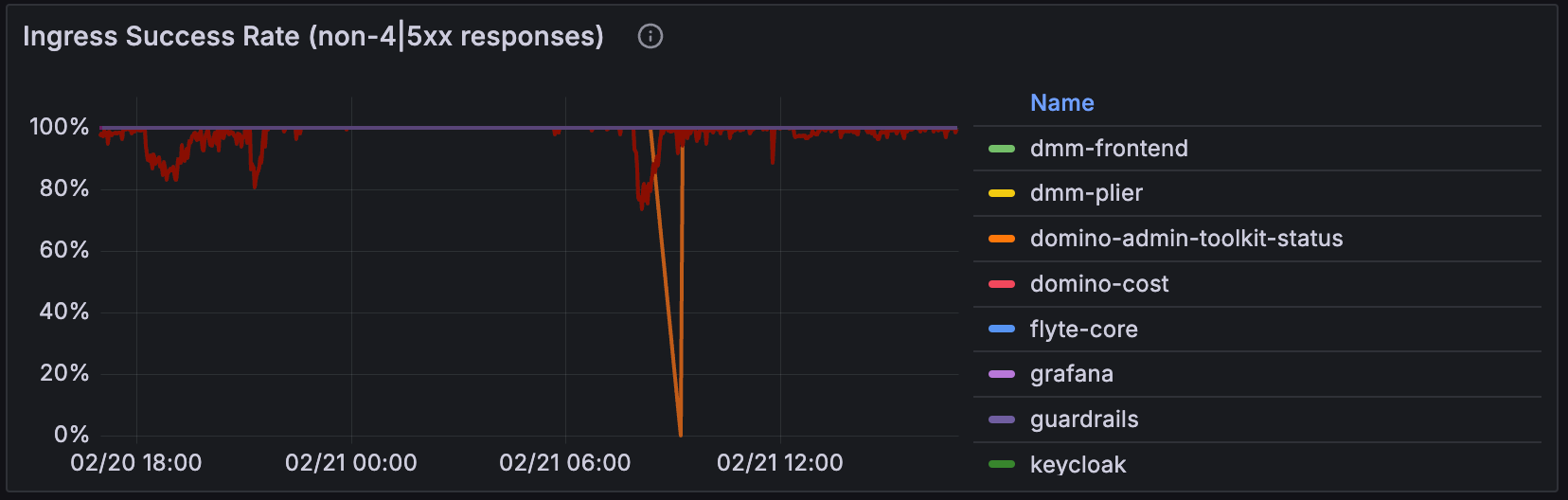
The Ingress Success Rate panel shows the success rate of requests for each route handled by the NGINX Ingress Controller. This can help you understand which routes are experiencing problems and might need to be investigated further.
Network I/O pressure | Average Memory Usage | Average CPU Usage

These three panels show the network I/O bandwidth usage, average memory usage, and average CPU usage (measured in CPU cores) of the NGINX Ingress Controller over time. These can be useful for understanding the resource usage of the controller and whether it is under-provisioned or over-provisioned. If the network I/O is high, it might indicate that the controller is under heavy load, while high memory or CPU usage might indicate that the controller is under-provisioned.
Ingress Percentile Response Times and Transfer Rates

The Ingress Percentile Response Times and Transfer Rates panel shows the 50th, 90th, and 99th percentile response times for requests to the NGINX Ingress Controller, as well as the transfer rate of data through the controller for each route. This can help you understand where the bottlenecks are in the Domino platform and which routes might need to be optimized for better performance.
Example of the Kubernetes / System / Cluster Autoscaler dashboard
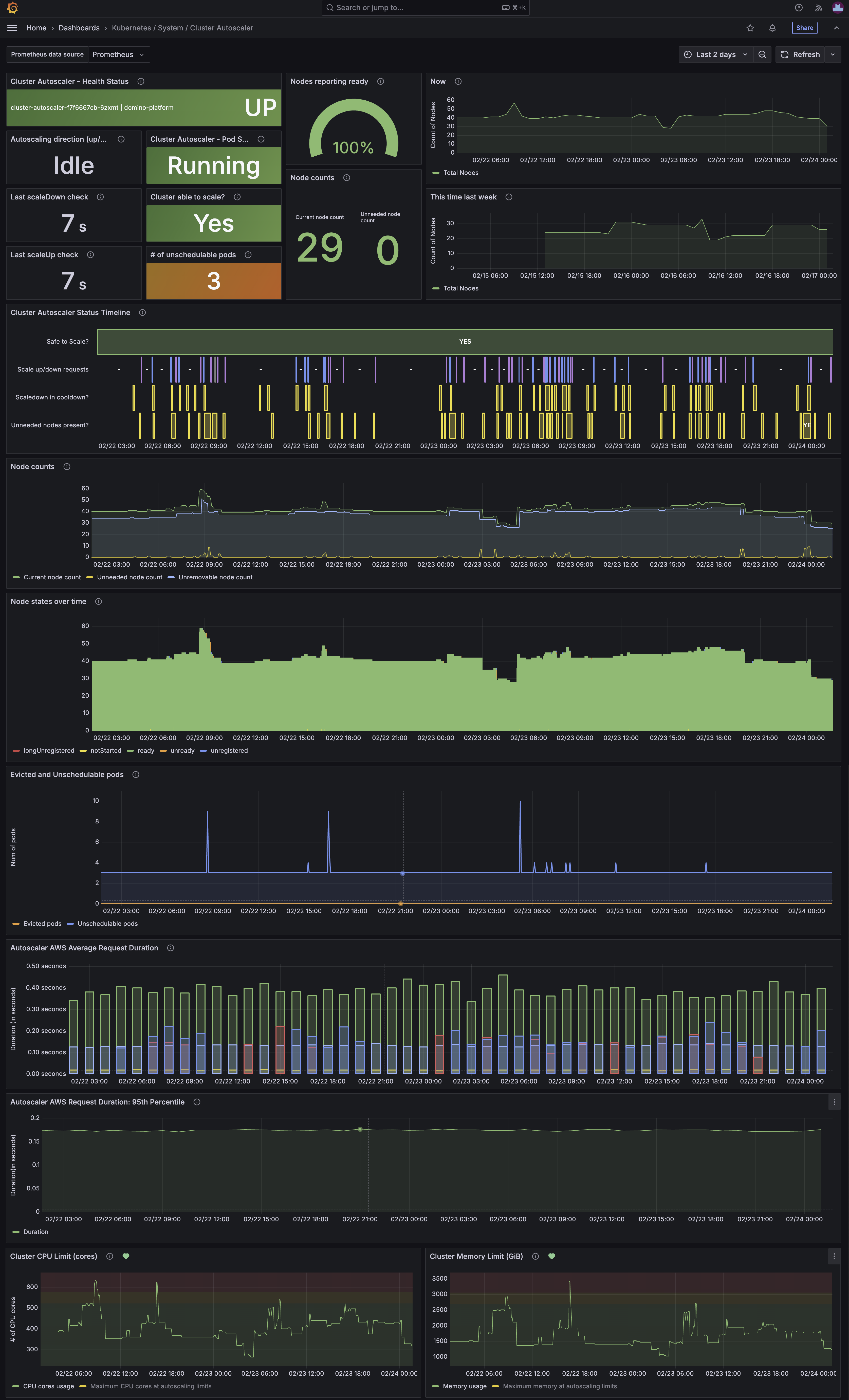
The Kubernetes / System / Cluster Autoscaler dashboard provides an overview of the Kubernetes Cluster Autoscaler that is used to automatically scale the number of nodes in a Kubernetes cluster based on the resource usage of the workloads running on the cluster. The dashboard is divided into several sections that provide information on:
-
The current health of the autoscaler.
-
The number of nodes in the cluster, including a comparison to the previous week.
-
A timeline of the scaling decisions made by the autoscaler.
-
The number of needed, unneeded, and unremovable nodes.
-
A histogram showing the number of nodes in different phases of the Kubernetes node life-cycle.
-
The number of evicted and unschedulable pods.
-
AWS autoscaling request durations.
-
Total CPU and memory usage of the total maximum available in the cluster.
A more detailed description of the workings of the Kubernetes Cluster Autoscaler can be found in the official Kubernetes documentation.
Cluster Autoscaler - Health Status | Autoscaling direction | Last scaleDown check | Last scaleUp check | Cluster Autoscaler - Pod Status | Cluster able to scale? | # of unschedulable pods
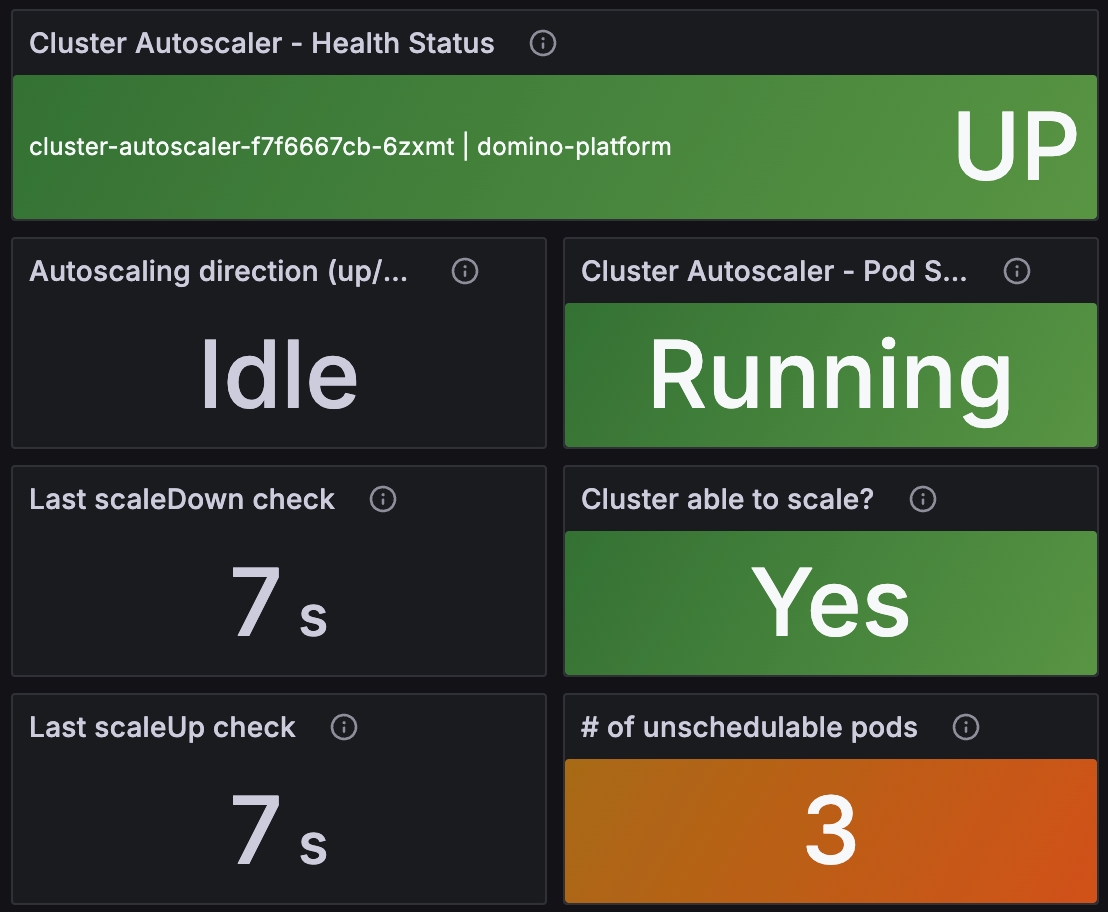
These panels show the current health of the Cluster Autoscaler:
Cluster Autoscaler - Health Status is a visual indication of whether the autoscaler pod in the deployment is UP.
Autoscaling direction shows the direction of the last autoscaling action (Up, Down, or Idle).
Last scaleDown check and Last scaleUp check show the time of the last check for scaling down and up, respectively. If the time is too long ago, it might indicate that the autoscaler is stuck.
Cluster Autoscaler - Pod Status shows the status of the autoscaler pod.
Cluster able to scale? shows whether the cluster is able to scale up or down. The autoscaler will not scale the cluster if it detects an issue with the autoscaling groups, or if it has recently scaled up; at which point it enters a cooldown state for a short period of time.
# of unschedulable pods shows the number of pods that are currently unschedulable. If this number starts to go up then it can indicate that the cluster is unable to scale up for some reason such as lack of instances in an autoscaling group, or problems with an AWS Availability Zone.
Nodes reporting ready | Node counts | Now | This time last week
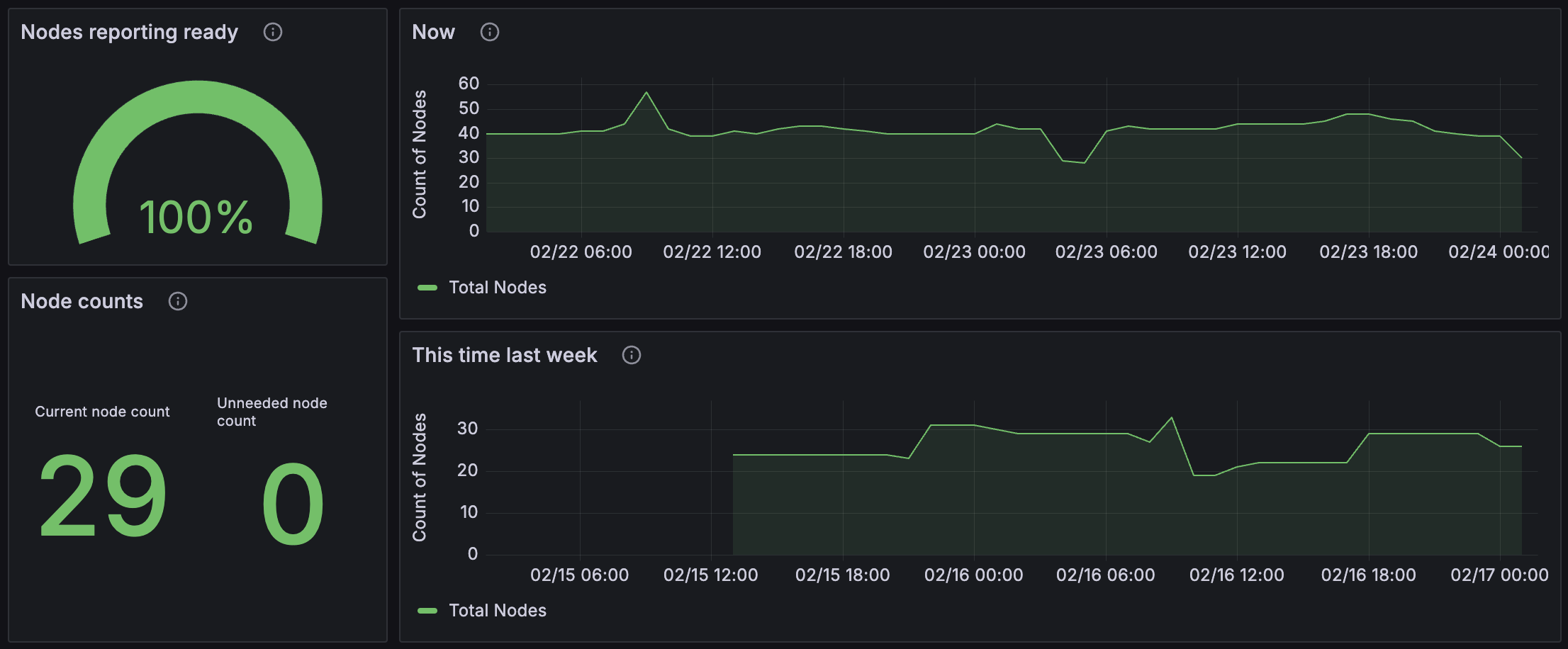
The Nodes reporting ready panel shows the ratio of nodes in the cluster that are currently reporting as ready versus not ready. This should generally be close to 100% most of the time except for short periods when a new node is spinning up as this operation may take some time.
The Node counts panel shows the current total number of nodes in the cluster and the current number of unneeded nodes. If the number of unneeded nodes is high, it might indicate that the cluster autoscaler is taking too long to scale down the cluster, or that a continuous stream of new workloads in one hardware tier is causing scale-ups, which then puts the autoscaler into a cooldown state, meaning it can’t scale down other hardware tiers.
The Now and This time last week panels show the number of nodes in the cluster over the requested period and a comparison to the same time period one week previously. This can be useful for understanding if the current cluster usage has grown or shrunk over time.
Cluster Autoscaler Status Timeline

This panel shows a timeline of the scaling decisions made by the autoscaler over time. This can be useful for understanding when the autoscaler has scaled the cluster up or down and why.
Green in the Safe to scale? line indicates that the autoscaler considers it safe to scale the cluster at that time. Red indicates that it is not safe to scale the cluster.
Scale up/down requests shows the scale up/down requests with blue indicating a scale-up and purple a scale-down event.
The Scaledown in cooldown? line shows when the autoscaler is in a cooldown state and unable to scale down the cluster. This usually occurs after a scale-up event.
Finally, the Unneeded nodes present? line shows when the autoscaler has detected that there are unneeded nodes in the cluster that can be removed by scaling down.
Node counts

This panel shows the total number of nodes in green, the number of nodes that the autoscaler thinks are not needed and could be scaled down in yellow, and the number of nodes that are unremovable in light blue.
Node states over time
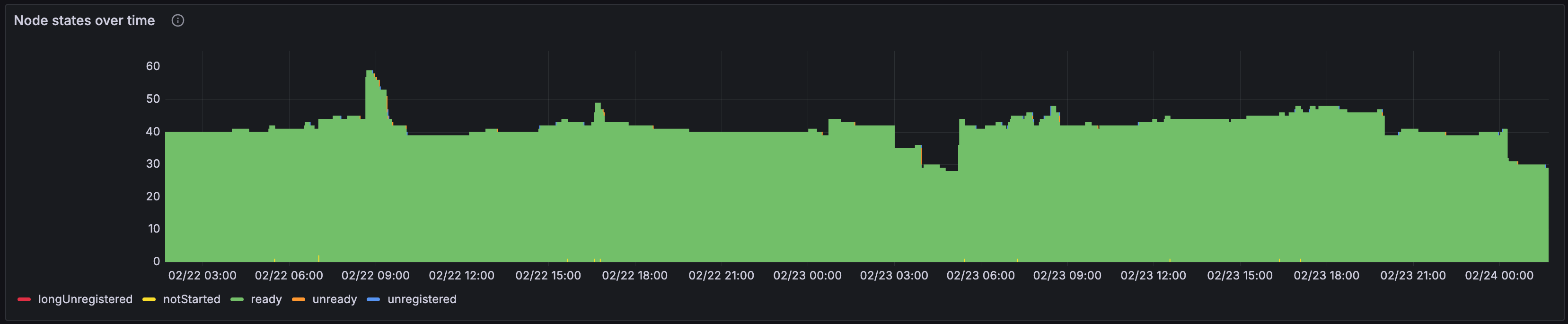
The Node states over time panel shows the number of nodes in the cluster in the various states of the Kubernetes node lifecycle, which are longUnregistered, notStarted, ready, unready, and unregistered. This can be useful for understanding the health of the nodes in the cluster and whether there are any issues with start-up or shutdown of nodes.
If there are many nodes in the longUnregistered state, it might indicate that there is a problem with the autoscaling group or the node itself not shutting down after it is unregistered. This can happen if it doesn’t properly release AWS resources assigned to it.
A large number of nodes in the unready state can indicate that there is a problem with the instance template used to create the node, or that the node is having trouble starting up.
Evicted and Unschedulable pods
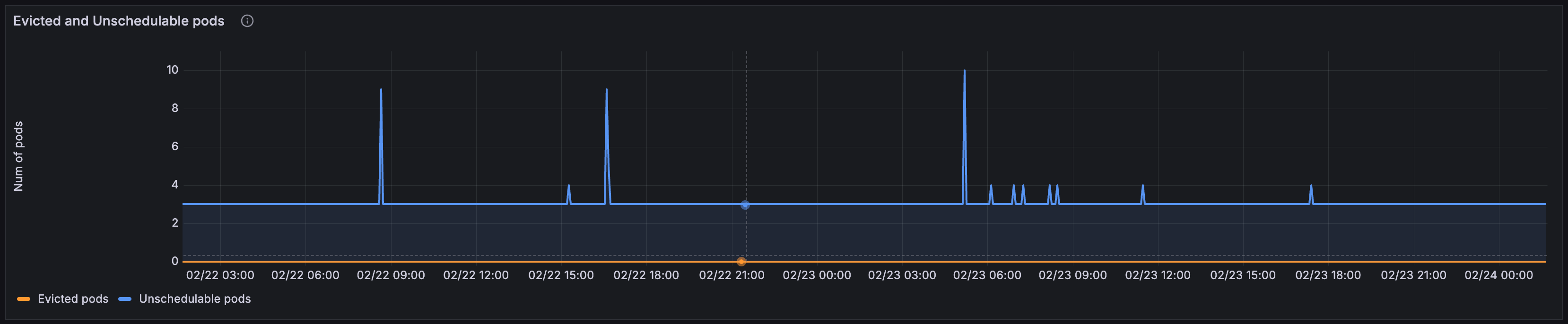
The Evicted and Unschedulable pods panel shows the number of pods that have been evicted from nodes in the cluster and the number of pods that are currently unschedulable.
If the number of evicted pods is high, it usually indicates that there is a problem with a pod consuming all the resources on a node.
It is normal for pods to be in the unschedulable state for a short period of time if there are no nodes available for them to fit on and the autoscaler needs to scale up a new node. This can take some time to start and register with the cluster. The pod should move to pending once the new node registers.
Autoscaler AWS Average Request Duration | Autoscaler AWS Request Duration: 95th Percentile
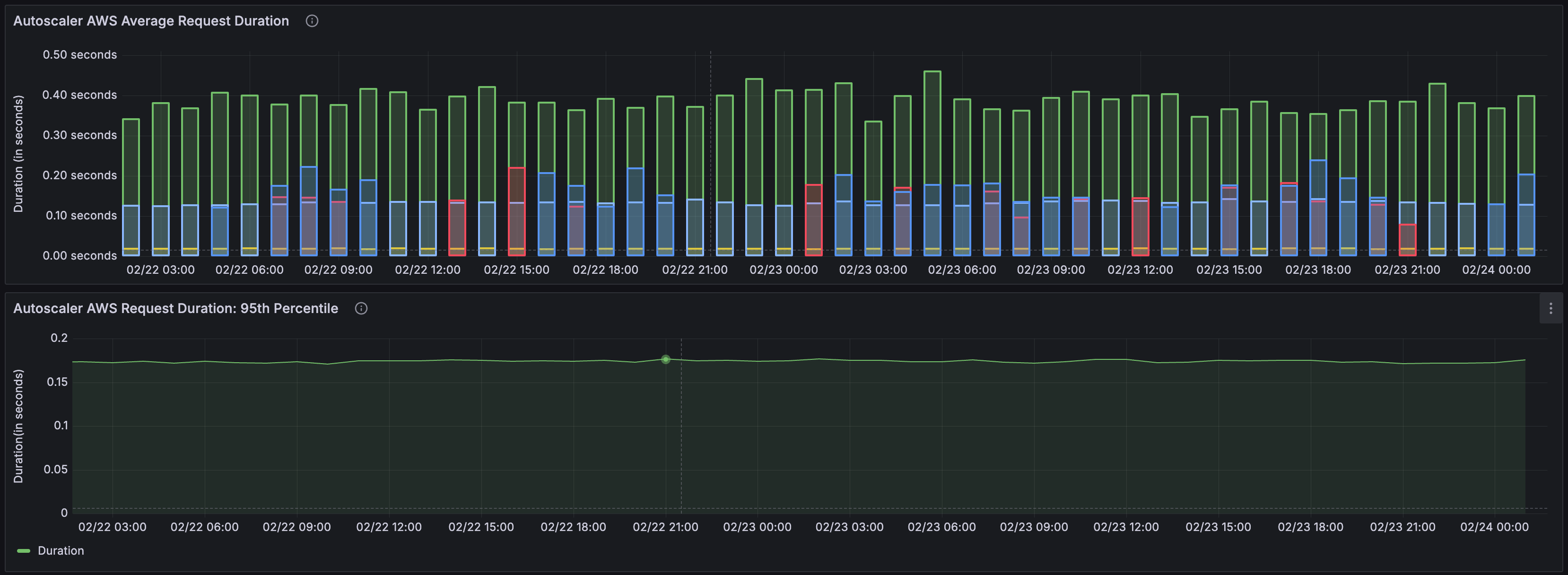
The Autoscaler AWS Average Request Duration and Autoscaler AWS Request Duration: 95th Percentile panels show the average and 95th percentile request duration for AWS autoscaling requests. This can be useful for understanding how long it takes AWS to respond to scaling requests. If the duration is high, it might indicate that there is a problem with the AWS Availability Zone that the cluster is in, or that there is a problem with the autoscaling group itself.
Cluster CPU Limit (cores) | Cluster Memory Limit (GiB)

The Cluster CPU Limit (cores) and Cluster Memory Limit (GiB) panels show the total CPU and memory usage of the cluster over time, compared to the total available according to the size of the nodes added to the cluster by the autoscaler. This can be useful for understanding the resource usage of the cluster and whether it is under-provisioned or over-provisioned.
If the CPU or memory usage keeps reaching the limit for extended periods of time, it might indicate that the cluster is under heavy load, while low usage might indicate that the cluster is over-provisioned.
The Kubernetes / Views / … and Kubernetes / System / … dashboards provide a detailed look at the state of various Kubernetes resources in the cluster. These dashboards can be useful for understanding which parts of the Domino deployment are consuming the most resources, which parts are under-provisioned, and which parts are over-provisioned. They can also be useful for understanding the health of the Kubernetes cluster itself and whether there are any issues with the underlying infrastructure.
Kubernetes / System / API Server shows the status of the Kubernetes API servers. The API servers are rarely a problem in most deployments, however, in a multi-tenant Kubernetes environment, you could have a 'noisy neighbor' which you would not know about if you do not have access to the monitoring for that application; monitoring the API Server could help with diagnosing this situation. The API server and related components are described fully in the official Kubernetes documentation.
Kubernetes / System / CoreDNS shows the status of the CoreDNS pods in the cluster. CoreDNS is the DNS server used by Kubernetes to resolve service names to IP addresses. If CoreDNS is having problems, it can cause issues with service discovery in the cluster. A detailed explanation of CoreDNS can be found in the official Kubernetes documentation.
Kubernetes / Views / Namespaces displays resource usage in the cluster by namespace. This allows you to easily separate resource usage of the Domino platform components from the Domino compute workloads.
Kubernetes / Views / Nodes shows the status of the nodes in the cluster, which is useful for understanding which nodes are under heavy load.
Kubernetes / Views / Pods shows the status of the pods in the cluster. This can be useful for understanding which pods are consuming the most resources or keep restarting.
Kubernetes / Views / Persistent Volumes shows the status of the persistent volumes in the cluster. There are a few services that require persistent storage and monitoring, so this is crucial to ensure that the services are running correctly.