The Domino Reproducibility Engine automatically tracks data science work, making it easy to reconstruct or reproduce it later.
Reproducibility in data science is critical for three reasons:
-
Reproducibility is the foundation for collaboration and work reuse. Data science often involves resuming previous work (done by you or a colleague). You can only resume work if you can run the same inputs and produce the same results. That means having access to the exact code, data, and software packages as they were.
-
Reproducibility is critical for auditability, review, and compliance. Especially in regulated industries, internal or external stakeholders may need to reconstruct data science work — either to validate it for production or to answer questions down the road. These tasks require reconstructing the materials used during the development process.
-
Reproducibility is good science and hygiene in any research process. Much literature has been written about this, but one paper we recommend is Ten Simple Rules for Reproducible Computational Research in PLOS Computational Biology.
Because reproducibility is a complex topic, the DRE doesn’t live on a single screen or location in Domino. Rather, it is integrated deeply into the architecture of the platform and woven throughout many features.
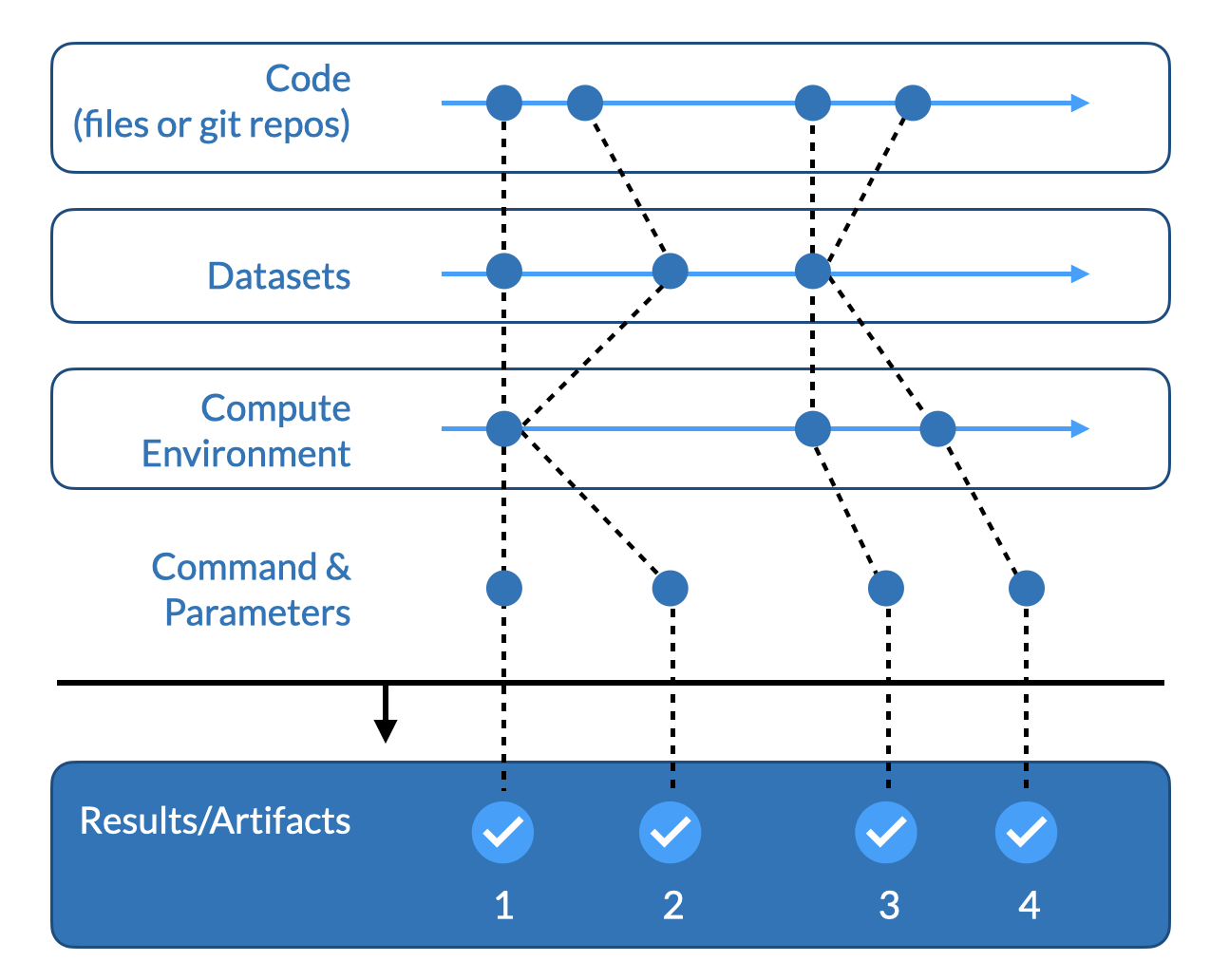
At its core, the DRE works by automatically tracking tuples, which are specific versions of input materials and results. Conceptually, a tuple contains the following components:

-
Code: the source code used, this could also include notebooks.
-
Data: data sources and data files used and manipulated by the code.
-
Software: the packages, drivers, and configuration in which your code runs.
-
Command: in the context of a batch job, the executed command.
-
Results: any outputs produced during the execution of your code. Typically these will be charts, additional data, serialized model files, and even rendered notebooks. These can also include statistics (e.g., RMSE, AUC) you want to track.
In Domino, there are several ways to materialize these components. Here is how the above conceptual materials are manifested in Domino.
| Concept | Domino implementation | |
|---|---|---|
DFS-backed Project | Git-backed Project | |
Code | Your code will be in your Project files directly. In this case, the DRE keeps a space-efficient snapshot of your Project files. | Your code will be in one or more externally-hosted Git repos. In this case, the DRE tracks the commit of each Git repo that was referenced when your code ran. |
Data | Your code can access data that is stored inside the Domino platform, or data that lives externally. The DRE only has direct awareness of data that is stored inside the Domino Platform. For data stored in your Domino project directly as files or Artifacts, the DRE will automatically track these in a space-efficient manner. For data stored in Datasets, the DRE will track which Snapshot was used by your code. For data in Data Sources, or data you access by connecting directly to databases or external sources, the DRE won’t be able to automatically track it. To track this type of external data, see Track external data. | |
Software | Domino tracks the version of the compute Environment used when your code executes. A revision of compute Environment is a revision of a Docker image along with some supplemental configuration scripts. | |
Results | Files in your Project that are created or modified when your code executes. | Files in the Artifacts section of your Project that are created or modified when your code executes. |
Statistics or results metadata | For stats that show up in Domino’s Jobs dashboard, Domino will extract them from a file named For our newer MLflow-based experiment tracking, use the MLfLow API to record your stats from your code. | |
Each of these materials can change independently in Domino. E.g., you may make multiple discrete edits to your code, re-running experiments after each one; and then later make a big change to update a package in your compute Environment.
At select operations — e.g., running a Job, syncing your work in Workspace, publishing a Domino endpoint — Domino records the state of your materials at that point.
Domino automatically tracks the active revision of each component at the time you execute your code. This diagram of how the DRE keeps track of each tuple as components are evolving separately.
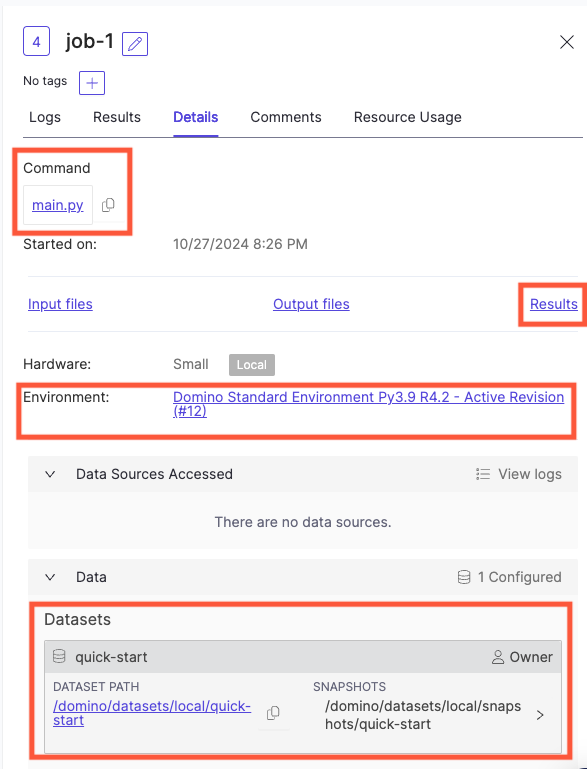
Below is an example of the details of a Job in Domino, highlighting some of the reproducible materials. Note that the Command is a link that takes you to a full snapshot of the code that was executed.
These topics in this section explain how you can make your workflows reproducible in Domino.
- Reproducibility use cases
-
Learn how to reproduce the results of a Job, Workspace, Model, App, or Launcher.
- Selectively revert past materials
-
Selectively restore a part of a Project, such as the package library version, while keeping your latest code and data.
- File syncing and persistence
-
Domino automatically tracks files in your Project and keeps previous versions in the blob store.
- Remove a file from the DRE: Permanent deletion
-
Purge a file completely and permanently from the blob store.
- Track external data
-
Materialize external data as a file in Domino to benefit from the automatic tracking that Domino provides.
- Compare results and Project states
-
Domino provides comparison tools to help you analyze changes in Files, Jobs, and Project states so you can manage Project artifact changes and audit those changes more effectively.
- Tips for reproducibility in Domino
-
Tips for maximizing the power of the Domino Reproducibility Engine.