This document will guide you to engineer the NOAA data into a form Snowflake finds palatable to digest, and then load the data from text/CSV files into Snowflake tables.
Before you can load the files into Snowflake, you need to download and adapt them to the format that would work for its data-loading functions.
This document will guide you on how to prepare your data through the following steps:
-
Download the dataset files.
-
Adapt them to a CSV or another character-delimited file (because commas don’t work in all situations).
-
Upload the file into Snowflake using the SnowSQL tool.
-
Use SnowSQL to load the files into database tables.
Big data in Domino: Domino Datasets
When you want to download a large file in the hundreds of megabyte size range or larger, or have a vast number of data files to process, Domino recommends that you use your project’s Dataset facility instead of files. Besides a clean separation between your code and data, Datasets also allow Domino to optimize file storage and file sharing, and create an easy way to load data into your Environment.
Since the first file is at least 11GB, use a Domino Dataset.
-
Log into Domino and create a new Project called
Snowflake-Quickstart. -
Open a new Workspace, normally the Domino default Environment with Python, and choose JupyterLab as your IDE.
-
Click Launch. A new browser tab will open and your Workspace will start loading. After a minute or two – depending on the availability of resources in your Domino Environment – the Workspace will open and display a Launcher page.
-
In the Other section, click on the Terminal shortcut to start a terminal. This will allow you to access and manipulate data files using Linux’s built-in file processing tools.
-
Since you are downloading large amounts of data, you need to store the data in a Domino Dataset. Domino’s Datasets reside in a special directory. Switch to that directory for the time being:
cd /domino/datasets/local/Snowflake-Quickstart/ -
Use the
wgetcommand to download the dataset files:wget https://www.ncei.noaa.gov/pub/data/ghcn/daily/ghcnd-stations.txt wget https://www.ncei.noaa.gov/pub/data/ghcn/daily/ghcnd-countries.txt wget https://www.ncei.noaa.gov/pub/data/ghcn/daily/ghcnd-states.txt wget https://www.ncei.noaa.gov/pub/data/ghcn/daily/ghcnd-inventory.txt wget https://www.ncei.noaa.gov/pub/data/ghcn/daily/superghcnd/superghcnd_full_<date of newest file>.csv.gz -
Unzip the large
superghcnd_full_*file using thegunzipcommand:gunzip superghcnd_full_<date>.csv.gzReplace
<date>with the specific date shown in the filename. Depending on the Domino instance you are using, this extraction can take a while. You can add an ampersand (&) to the end of the line to run the command in the background.
Format the file
While the main data file is a 'proper' CSV file, these metadata files use size-delimited fields (column width as measured in the number of characters). For example:
----------------------------------
Variable Columns Type
----------------------------------
ID 1-11 Character
LATITUDE 13-20 Real
LONGITUDE 22-30 Real
ELEMENT 32-35 Character
FIRSTYEAR 37-40 Integer
LASTYEAR 42-45 Integer
----------------------------------In practice, it looks something like this:
ACW00011647 17.1333 -61.7833 WT16 1961 1966
FM00040990 31.5000 65.8500 TAVG 1973 2020
AG000060390 36.7167 3.2500 TMAX 1940 2022It appears some data in the files contain commas, which can add 'columns' to the file unintentionally if a comma is used as a delimiter.
While it is suboptimal to use the vertical bar (|) as the delimiter (the vertical bar is a Unix operand), it will make do for this example Project.
Since Snowflake does not support field size-based data ingestion, you need to use regular expressions and classic Unix utilities, such as sed and tr, to modify this file to add a delimiter.
Sed is a stream editor, i.e. it reads chunks, normally lines, and can modify each line independent of the next.
In general, sed works in a nifty way when using (truly basic) regular expressions:
sed 's/<pattern to match>/<replacement text>/<location in the line or everywhere>' > <output file>While there is more than one way to do it, you can use sed as follows:
sed 's/./|/12;s/./|/21;s/./|/31;s/./|/38;s/./|/41;s/./|/72;s/./|/76;s/./|/80' ghcnd-stations.txt > ghcnd-stations.csvLook at the first replacement in the line to understand what’s happening:
s/./|/12That would mean that, for each line of the input, count twelve characters that match the regular expression . (any character), then replace the twelfth character with a vertical bar (|).
These directives are repeated throughout the line, separated by semicolons, to place vertical bar characters to delimit the fields based on the number of characters in the line. The outcome looks like this:
ACW00011647|17.1333|-61.7833|WT16|1961|1966
AFM00040990|31.5000|65.8500|TAVG|1973|2020
...
AG000060390|36.7167|3.2500|TMAX|1940|2022Similarly, you can also convert the inventory, country, and state files:
sed 's/./|/12;s/./|/21;s/./|/31;s/./|/36;s/./|/41' ghcnd-inventory.txt > ghcnd-inventory.csv
sed 's/./|/3' ghcnd-countries.txt > ghcnd-countries.csv
sed 's/./|/3' ghcnd-states.txt > ghcnd-states.csvCollect a data subset
Western Europe has consistently collected weather data over the last 70 years or so for Germany (mostly West Germany), Italy, France, Spain, United Kingdom, Portugal, The Netherlands, Belgium, Switzerland, and Austria. Therefore, datasets as big as 100GB are reasonable in the real world. However, you can extract a subset of this data (with weather information for Western Europe) of around 2GB to simplify matters.
Since each entry in the dataset represents one data item per weather station, it starts with the weather station’s ID. That ID starts with the country code, so you can filter the dataset to return only the information you need for these countries.
-
Use the
sedtool to find the identifying country codes then extract the data from the big dataset you unzipped.-
One way is to look for one country, get the country code, and extract its data from the full dataset into a file.
sed -n '/Neth.*/p'Which will return the code for The Netherlands:
NL Netherlands -
Alternatively, you can abbreviate it to this:
sed -n '/Neth.*/p;/Ita*/p;/Spa*/p;/.. United K.*/p;/Germany/p;/Switz*/p;/Portu*/p;/Belg.*/p;/.. France/p;/Austria/p' ghcnd-countries.txtThe result:
AU Austria BE Belgium FR France GM Germany IT Italy NL Netherlands PO Portugal SP Spain SZ Switzerland UK United Kingdom
-
-
Next, you can extract the data from the dataset for one country like this:
% sed -n '/^NL.*/p' superghcnd_full_20220907.csv > netherlands_data.csvTo break it down:
-
-n– Suppresses the output. -
/^NL.*– Returns lines starting with (^) NL, followed by any number of characters. -
/p– Prints the line. -
> netherlands_data.csv– Redirects the output to a new CSV file.
-
-
You can combine all these statements for all the countries in all the lines into one command using the codes you extracted:
sed -n '/^AU.*/p;/^BE.*/p;/^FR.*/p;/^GM.*/p;/^IT.*/p;/^NL.*/p;/^PO.*/p;/^SP.*/p;/^SZ.*/p;/^UK.*/p' superghcnd_full_<strong><your file date></strong>.csv > west_euro_data.csv -
Use an identical approach on the weather stations and inventory files:
sed -n '/^AU.*/p;/^BE.*/p;/^FR.*/p;/^GM.*/p;/^IT.*/p;/^NL.*/p;/^PO.*/p;/^SP.*/p;/^SZ.*/p;/^UK.*/p' ghcnd-stations.csv > ghcnd-stations-west-eu.csv sed -n '/^AU.*/p;/^BE.*/p;/^FR.*/p;/^GM.*/p;/^IT.*/p;/^NL.*/p;/^PO.*/p;/^SP.*/p;/^SZ.*/p;/^UK.*/p' ghcnd-inventory.csv > ghcnd-inventory-west-eu.csv
At this point, you are finally ready to go to Snowflake!
The data is loaded into Snowflake through staging, which refers to either uploading the data to a special area in your Snowflake account or having Snowflake pull your data from an AWS or Azure data store.
In this tutorial, you will follow the local file-to-stage route. To upload the data and work with Snowflake directly, Snowflake offers a powerful command-line tool, called SnowSQL.
Connect to the Environment
Domino offers a Snowflake-optimized Environment that has the tool preinstalled.
To connect to this Environment, you need your account ID, username, and password, along with the names of your warehouse, database, and schema (which is often PUBLIC).
Once connected, you will get an interface to your very own cloud database.
-
The fastest way to connect is via command-line options such as the following:
snowsql -a <account ID> -u <user name> -w <warehouse name> -d <database name> -s <schema name> -o log_file=~/.snowsql/logNote that in Domino, you may first need to delete the
.snowsql/logfile using:rm ~/.snowsql.log -
Once connected, enter your password when prompted.
Create the schema
|
Note
| Going forward, all steps are executed in SnowSQL. |
Before you can upload the data, you need to define tables to hold the data.
This is how it looks in an entity-relationship diagram:
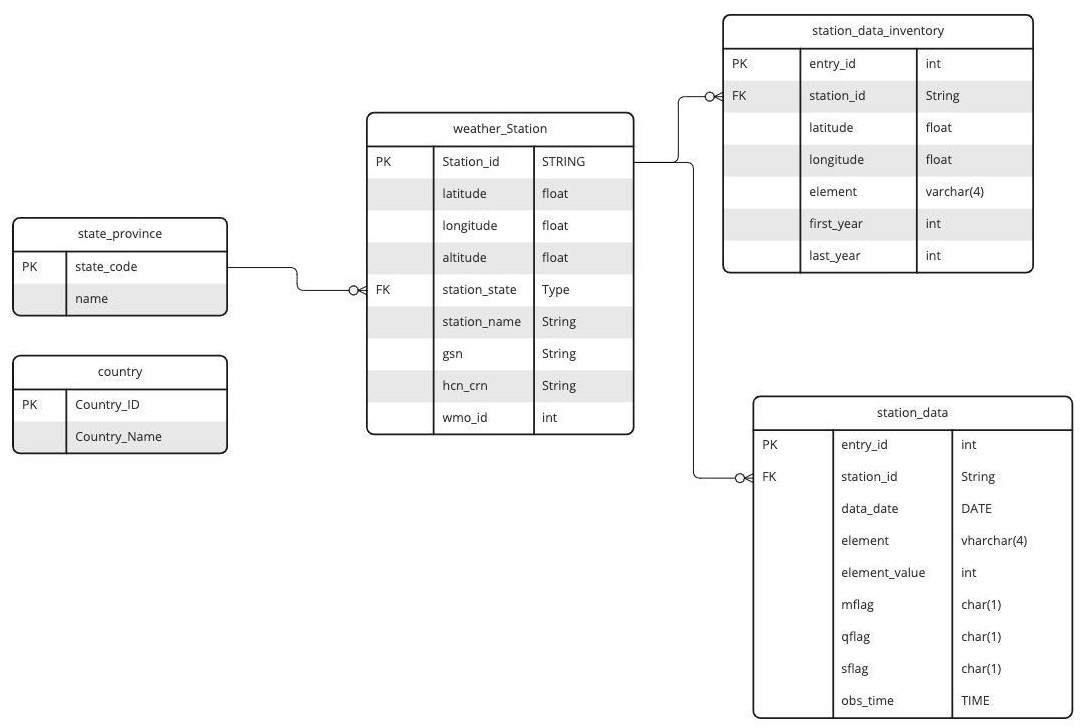
-
Below is the corresponding SQL code to create the tables. Run this script, command by command, in SnowSQL:
CREATE OR REPLACE TABLE country (country_id CHAR(2) PRIMARY KEY, country_name VARCHAR(100) NOT NULL); CREATE OR REPLACE TABLE state_province (state_code CHAR(2) PRIMARY KEY, NAME VARCHAR(50) NOT NULL); CREATE OR REPLACE TABLE weather_station(station_id CHAR(12) PRIMARY KEY, latitude float NOT NULL, longitude float NOT NULL, elevation FLOAT NOT NULL, station_state CHAR(2) FOREIGN KEY REFERENCES state_province (state_code) NULL, station_name VARCHAR (40) NOT NULL, gsn CHAR(5) NULL, hcn_crn CHAR(5) NULL, wmo_id CHAR(5) NULL); CREATE OR REPLACE TABLE station_data_inventory (entry_id INT IDENTITY PRIMARY KEY, station_id CHAR(12) FOREIGN KEY REFERENCES weather_station (station_id), latitude float NOT NULL, longitude float NOT NULL, element VARCHAR(4) NOT NULL, first_year INT, last_year INT); CREATE OR REPLACE TABLE station_data ( entry_id INT IDENTITY PRIMARY KEY, station_id CHAR(12) FOREIGN KEY REFERENCES weather_station (station_id), data_date DATE NOT NULL, element CHAR(4) NOT NULL, element_value INT NOT NULL, mflag CHAR(1), qflag CHAR(1), sflag CHAR(1), obs_time TIME); -
To see the tables, run the following command:
show tables;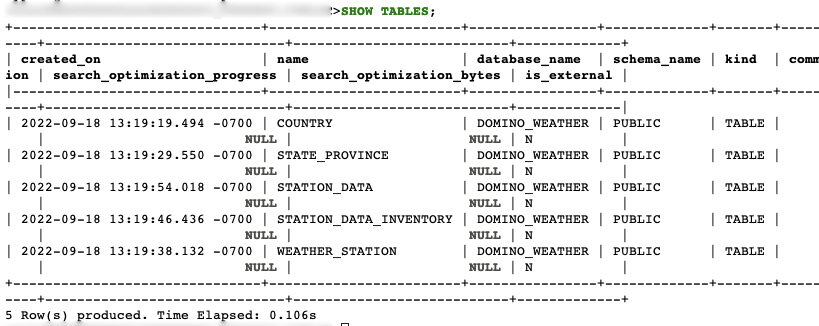
Create a file format object
The following steps are based on Snowflake’s own SnowSQL data loading tutorial.
To upload the data you wrangled in the previous steps:
-
Create a file format object – this helps guide Snowflake on how to read your file and map it into your database tables. Although the file type is still CSV (comma-separated values), remember to specify
|as the field delimiter. For example:create or replace file format bar_csv_format type = 'CSV' field_delimiter = '|' skip_header = 1; -
Create another file format for the main data file, which uses commas as delimiters:
CREATE OR REPLACE FILE FORMAT comma_csv_format type = 'CSV' field_delimiter = ',';
Create the staging area
Create the stage (i.e. the holding area for uploaded files) and add the file format specification to it (the other file format will be used later):
CREATE OR REPLACE STAGE weather_csv_stage
file_format = bar_csv_format;This creates a staging area called weather_csv_stage to hold your uploaded data.
Upload the data files
-
Upload the files from Domino. Make sure you adjust the command to the correct directory for your dataset:
put file:///domino/datasets/local/<project dataset directory>/ghcnd*.csv @weather_csv_stage auto_compress=true;The result should look like this:

-
You can also list the files you uploaded using the following command:
list @weather_csv_stage; -
Upload your Western European data file:
put file:///domino/datasets/local/<your project dataset directory>/west_euro_data.csv @weather_csv_stage auto_compress=true;This might take a while, but eventually, the result should look something like this:

-
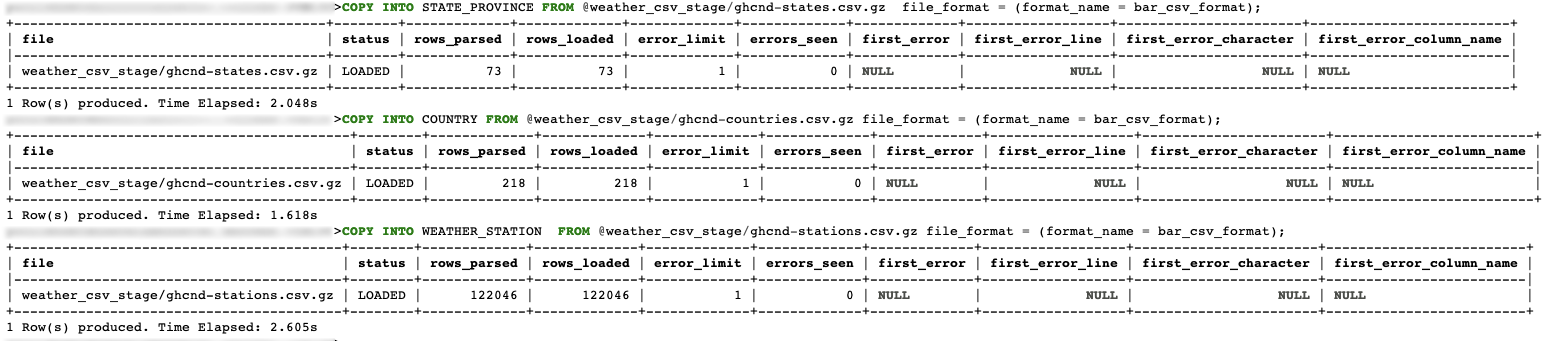
Use the
COPY INTOcommand to load the data into the Snowflake database tables. Start with the smaller files and ensure foreign key constraints are documented, as Snowflake does not enforce referential integrity:COPY INTO STATE_PROVINCE FROM @weather_csv_stage/ghcnd-states.csv.gz file_format = (format_name = bar_csv_format); COPY INTO COUNTRY FROM @weather_csv_stage/ghcnd-countries.csv.gz file_format = (format_name = bar_csv_format); COPY INTO WEATHER_STATION FROM @weather_csv_stage/ghcnd-stations-west-eu.csv.gz file_format = (format_name = bar_csv_format);These are relatively straight-forward and should result in something like this:
-
The station data inventory is slightly more complex. You are using an artificial identity field as the primary key, which requires that you load data from the CSV file into specific columns. This is done with a subquery, for example:
COPY INTO station_data_inventory (station_id, latitude, longitude, element, first_year, last_year) FROM (select t.$1, t.$2, t.$3, t.$4, t.$5, t.$6 from @weather_csv_stage (file_format => 'bar_csv_format', pattern => '.*ghcnd-inventory-west-eu.csv.gz') t) ON_ERROR = CONTINUE;The query will result in hundreds of thousands of rows being loaded. Snowflake will show you how many rows were ready in the result. Note the use of the
ON_ERROR = CONTINUEbehavior in the query - you can tolerate missing a small number of rows as these are very large data files that can result in errors. -
Finally, load the Western Europe dataset in a similar fashion:
COPY INTO STATION_DATA (STATION_ID, DATA_DATE, ELEMENT, ELEMENT_VALUE, MFLAG, QFLAG, SFLAG, OBS_TIME) FROM (SELECT t.$1, TO_DATE(t.$2, 'yyyymmdd'), t.$3, t.$4, t.$5, t.$6, t.$7, TO_TIME(t.$8, 'hhmm') FROM @weather_csv_stage (file_format => 'COMMA_CSV_FORMAT', pattern => '.*west_euro_data.csv.gz') t) ON_ERROR = CONTINUE;You should have approximately 120 million rows of data.
-
To demonstrate the speed at which Snowflake executes queries, try running the following query to count how many unique station IDs exist in this large table:
SELECT COUNT(DISTINCT STATION_ID) AS STATION_COUNT FROM STATION_DATA;
The next step will focus on whittling down the data, this time in Domino, with Snowflake code.