You already downloaded a sizeable collection of historical weather data, but NOAA weather stations worldwide collect new data every day. NOAA also reviews the data that stations collect and corrects mistakes. Instead of downloading and storing the entire historical record every day, NOAA offers almost daily diff archives.
For example, the file superghcnd_diff_20170123_to_20170124.tar.gz contains updates and new data collected between January 23 and January 24, 2017.
Each diff file consists of three CSV files:
-
delete.csv- records to delete from station data. -
insert.csv- new data collected at stations during the period associated with the file. -
update.csv- changes to station data.
These files contain rows of records similar to the table below where the columns are the station ID, observation date, observation type (maximum temperature, precipitation, etc.), observation value, comments, observation flags to denote additional metadata, and the observation time.
USC00219072 | 20170120 | SNWD | 152 | H | 600 | ||
USC00471287 | 20170120 | SNWD | 0 | H | 730 | ||
USC00241127 | 20170120 | TMIN | -44 | H | 1700 | ||
RSM00031369 | 20170120 | TMAX | -233 | S | 1700 |
In this part of the tutorial, you will create a script that handles this data update task. The script will:
-
Download the relevant
difffiles since it was last run. -
Update the database - deleting, updating, and inserting records.
While the script can run manually, it is much more reliable to pull the data from NOAA using an automated scheduled (cron) job.
Given that NOAA releases these files daily, we will schedule the script to execute daily.
Domino makes that part very simple.
Domino Jobs execute scripts in your preferred programming language in a headless fashion, meaning that they run without a graphical user interface. Each job runs using an individual container (or cluster of containers) that starts up, runs, and shuts down automatically. The job will only consume resources during its execution.
You can use any of your existing Domino Environments with your jobs, ensuring consistency and helping with reproducibility. You can learn more about jobs in the Domino documentation, but we will cover the basics here.
As you might imagine, the data update operation will need to perform diverse operations such as delete, update, and insert. For this reason, you should switch to using the Snowflake Python Connector instead of the Domino Data Source you used previously.
While the Domino Data Source can handle virtually all operations, it’s optimized for data exploration and lightweight read operations. On the other hand, the Python Connector offers access to many of the highly optimized capabilities and workflows Snowflake offers, which you will be taking advantage of.
While Snowflake works great with SQL commands, it has especially fast data loading and staging capabilities. Snowflake performs large-scale data operations rapidly using the following workflow:
-
Uploads your CSV (or another delimited text format) data into your Snowflake staging area. The staging area is a temporary storage space used for data prep and is part of your Snowflake cloud space.
-
Loads your data from the staged CSV file into a temporary (or permanent) table using the
COPY INTOSnowflake command. -
Performs database operations (e.g.
DELETE,UPDATE,INSERT) using normal SQL notations. The code below follows this pattern.
The script consists of a main function that orchestrates calls to individual functions responsible for specific operations.
The main function, update_weather_data(), calls these functions in the following order:
-
Initialize_connection- obtains a database connection object using the credentials you stored securely in Domino. -
Get_update_start_date- checks the database to see what is the date of the latest weather records. This is used to identify how many files you will need to download to stay up to date with NOAA’s weather data. Note that this is not a failsafe approach to ensuring no duplicate records exist. -
Get_diff_file_urls- reaches out to the NOAA website to find the files you need to download and process. If none are found, the script will exit. -
Perform_updates- handles downloading the files, dispatching them to dedicated functions to delete (do_delete), update (do_update), and insert (do_insert) records, and finally clean up the downloads from your file system. -
A
mainblock - as the job will only call the script by name and not specify a function.
Create the script
To get started, go ahead and create a Python file in a Domino Workspace, as you have done for the Domino Launcher file.
Name the file DataUpdaterJob.py and save it into the project’s root folder.
What follows is the code with highlights of notable items that you can add to the script:
The constants
import snowflake.connector
import os
import pandas as pd
import numpy as np
import requests
import shutil
import tarfile
import json
noaa_url = "https://www.ncei.noaa.gov/pub/data/ghcn/daily/superghcnd/"
# Make sure to point at a dataset directory as the file sizes are occasionally large
download_path = '/domino/datasets/local/Snowflake-Quickstart/downloads/'
# Save the countries you need for later operations
country_prefixes = ['AU', 'BE', 'FR', 'GM', 'IT', 'NL', 'PO', 'SP', 'SZ', 'UK']
# How many rows to process at once, to avoid running out of memory
chunksize = 10 ** 6
# The name you will use for the downloaded diff files
download_file_name = 'cur_diff.tar.gz'
# Columns used in your dataframe and temporary database table
column_names = ['station_id', 'data_date', 'element', 'element_value', 'mflag', 'qflag', 'sflag', 'obs_time', 'operation']Note that the script limits the number of rows you read from the diff file to avoid memory problems. It will perform multiple reads until the entire file is read.
The main function
def update_weather_data():
try:
conn = initialize_connection()
except:
print("ERROR: Failed to connect to database. Exiting.")
return 1
else:
print("Connected successfully to Snowflake...")
update_start_date = get_update_start_date(conn)
diff_df = get_diff_file_urls(update_start_date)
if len(diff_df) == 0:
print("Nothing to update. Exiting.")
return 0
result_list = perform_updates(diff_df, conn)
with open('dominostats.json', 'w') as f:
f.write(json.dumps({"Deletes": result_list[0], "Updates": result_list[1], "Inserts": result_list[2]}))
finally:
conn.close()
returnThe main function orchestrates the script’s execution.
-
You try to connect to the database, call the functions that perform individual steps, and close the connection when the execution ends.
-
The call to
perform_updatesreturns an array containing the number of database records that were changed. -
Those numbers are used to populate Domino’s job visualization capability—custom job metrics.
To help you visualize how your job executions performed over time, Domino provides a line chart to accompany the job execution listing view. In this example, you control what the chart displays by saving a simple JSON file (
dominostats.json) to the project’s root folder. You then track how many row delete, update, and insert operations the job performs in each run by saving a JSON object that maps the counts as values to the keysDeletes,Updates, andInserts. Domino then takes the file and uses the keys and values to populate the visualization for the job. Domino collects the data over time to create the chart.
|
Note
|
|
Initialize the connection to Snowflake
#-----------------------------------------------------
# Returns: connection object
#-----------------------------------------------------
def initialize_connection():
conn = snowflake.connector.connect(
user = os.environ['username'],
password = os.environ['password'],
account = os.environ['accountname'],
warehouse = os.environ['warehousename'],
schema = os.environ['schemaname'],
database = os.environ['dbname'])
return connThis function aims to obtain a connection to the database.
It pulls the credentials from the secure store in Domino and calls the Snowflake Python Connector’s connect method.
It then returns the connection object for use in the rest of the script.
If the connection fails, the main function handles the exception and exits.
Find the latest date
#----------------------------------------------------------------
# Argument(s): The connection object
# Returns: The date of the newest data record in the database
#----------------------------------------------------------------
def get_update_start_date(conn):
cursor = conn.cursor()
# Get the most recent date for which we have data
cursor.execute("SELECT DATA_DATE FROM STATION_DATA ORDER BY DATA_DATE DESC LIMIT 1;")
df = cursor.fetch_pandas_all()
cursor.close()
last_update_date = df['DATA_DATE'][0]
print(f"Most recent record in database is from {last_update_date}")
return last_update_dateThis function queries the database to find the date of the latest weather data available and returns it to the main function. You need this date to perform the data update.
Get a list of the files to download
#------------------------------------------------------------------
# Argument(s): The date of the most recent record in the database
# Returns: Dataframe with list of files to read for the data update
#------------------------------------------------------------------
def get_diff_file_urls(last_update_date):
print("Checking updates from NOAA...")
page = pd.read_html(noaa_url)
df = page[0]
df['Last modified'] = pd.to_datetime(df['Last modified'])
df = df.astype({'Name':'string'})
# Keep diff files only
diff_df = df[df['Name'].str.contains('diff')].sort_values(by=['Last modified'], ascending=False)
# Limit to only the diff files that are relevant to you - files newer than your last update date
diff_df=diff_df[diff_df['Last modified'].dt.date > last_update_date]
# Sort the files so the oldest file is first
diff_df = diff_df.sort_values('Last modified')
# Remove files with gigabyte-sized updates (normally an NOAA error)
diff_df = diff_df[diff_df['Size'].str.find('G') == -1]
print(f"Need to retrieve {len(diff_df)} update files")
return diff_dfGiven the date of the latest data in the database, this function downloads the list of available files from the NOAA website. It then filters down the dataframe containing the file list to the ones newer than your last update date. It also excludes files that are larger than 1GB to avoid memory issues (due to your job hardware limitations - you can choose to provide higher-capacity hardware and storage space).
The main function will then check to see if the dataframe is empty. If it is, the script will exit as no updates are available.
Perform delete, update, and insert operations
#------------------------------------------------------------------
# Argument(s):
# 1. Dataframe containing diff file URLs in oldest to newest order
# 2. Database connection object
# Returns: List containing number of updates
#------------------------------------------------------------------
def perform_updates(diff_df, conn):
cursor = conn.cursor()
delete_count = 0
update_count = 0
insert_count = 0
# Iterate over all diff files
for index, row in diff_df.iterrows():
# Define the size of data chunks for us to read at a time
chunksize = 10 ** 6
oldest_file = getattr(row, 'Name')
oldest_file_url = noaa_url + oldest_file
print(f"Now dowloading {oldest_file}...")
# Download the file
response = requests.get(oldest_file_url, stream=True)
if response.status_code == 200:
with open(download_path+download_file_name, 'wb') as f:
f.write(response.raw.read())
else:
print(f"Failed to download {oldest_file}. SKIPPING!")
continue
print("Done. Extracting...")
# Extract the file
file = tarfile.open(download_path+download_file_name)
file.extractall(download_path)
file.close()
print("Done. Processing...")
# Get the directory name by removing the .tar.gz
dir_name = oldest_file.split('.', 1)[0]
# Perform updates
delete_count += do_delete(cursor, dir_name)
update_count += do_update(cursor, dir_name)
insert_count += do_insert(cursor, dir_name)
# Clean up
shutil.rmtree(download_path+dir_name)
cursor.close()
result_list = [delete_count, update_count, insert_count]
return result_listThis function receives the database connection and the list of files as its arguments. It uses the connection to obtain a Snowflake database cursor object. The cursor will help you handle database changes as transactions.
Next, the function iterates over the file list - downloading the files, oldest to newest, one by one. After downloading a file, it extracts it. If the download fails, it will try to download the next file on the list.
Once extracted, it passes the file path and the cursor to each of the functions that handle delete, update, and insert operations. Each function will return the number of rows it processed in the database. When the operations conclude, it deletes the files and closes the cursor.
Finally, it creates an array to hold the number of processed rows and returns it to the main function.
Let’s now have a look at each of the three database update execution functions that were used in the code above. Since all three functions are similar, we will examine the first (delete) more thoroughly and then offer insights into the unique aspects of the others (update and insert). Note that you can easily refactor these three functions - we chose to include this explicit approach for clarity.
The do_delete function
#------------------------------------------------------------------
# Argument(s):
# 1. Database connection cursor
# 2. File path
# Returns: Number of rows deleted
#------------------------------------------------------------------
def do_delete(cursor, dir_name):
print(">>> Starting delete operation <<<")
chunkcount = 0
west_eu_df = pd.DataFrame(columns = column_names)
for del_df in pd.read_csv(download_path+dir_name+'/delete.csv', names = column_names,
dtype={'station_id': 'str', 'data_date': 'str', 'element': 'str', 'element_value': 'int',
'mflag': 'str', 'qflag':'str', 'sflag':'str', 'obs_time': 'str'},
chunksize = chunksize):
chunkcount = chunkcount + 1
print(f"Reading chunk {chunkcount} of delete data")
del_df['data_date'] = pd.to_datetime(del_df['data_date'], yearfirst=True)
# Filter the file for Western European stations
for cur_country in country_prefixes:
country_df = del_df[del_df['station_id'].str.startswith(cur_country)]
west_eu_df = pd.concat([west_eu_df, country_df], ignore_index=True)
print(f"Read data in {chunkcount} chunks. Deleting {len(west_eu_df)} records")
# Output file
west_eu_df.to_csv(download_path+dir_name+'/diff-data.csv', index=False, sep="|")
sfQuery = """CREATE OR REPLACE TEMPORARY TABLE TEMP_DIFF_DATA
(station_id TEXT,
data_date DATE,
element TEXT,
element_value INT,
mflag char(1),
qflag char(1),
sflag char(1),
obs_time TIME,
operation char(1))"""
cursor.execute(sfQuery)
print("table created")
sfQuery = 'PUT file://' + download_path+dir_name+'/diff-data.csv @%TEMP_DIFF_DATA'
cursor.execute(sfQuery)
print("file uploaded")
cursor.execute("COPY INTO TEMP_DIFF_DATA file_format = (type = csv field_delimiter = '|' skip_header = 1)")
print("data copied from file to table")
cursor.execute("BEGIN TRANSACTION")
sfQuery = """DELETE FROM STATION_DATA sd USING TEMP_DIFF_DATA tdd
WHERE sd.station_id = tdd.station_id
AND sd.element = tdd.element
AND sd.data_date = tdd.data_date""";
try:
print("Executing deletion...")
cursor.execute(sfQuery)
except:
cursor.execute("ROLLBACK")
print("Transaction failed")
return 0
else:
cursor.execute("COMMIT")
print("Delete transaction successful")
os.remove(download_path+dir_name+'/diff-data.csv')
return len(west_eu_df)The do_delete function will read a chunk of rows from the delete.csv file at the specified location, dedicated to rows to delete from the database.
It will load the rows into a dataframe and remove rows with data about stations not in countries that are part of the West European region.
The resulting dataframe will be output into a CSV file.
Next, the function will create a temporary table in Snowflake and upload the CSV file you created to the Snowflake staging area.
It will then copy the data from the CSV into the temporary table.
The function will then create a transaction to contain the delete operation.
The deletion itself will be done using a SQL statement that compares files in your station_data table to the contents of the temporary table.
If the operation is successful, the function will commit the transaction; otherwise, it will roll it back.
The function will return the number of deleted rows.
The do_update function
#------------------------------------------------------------------
# Argument(s):
# 1. Database connection cursor
# 2. File path
# Returns: Number of rows updated
#------------------------------------------------------------------
def do_update(cursor, dir_name):
print(">>> Starting update operation <<<")
west_eu_df = pd.DataFrame(columns = column_names)
chunkcount = 0
with pd.read_csv(download_path+dir_name+'/update.csv', names = column_names,
dtype={'station_id': 'str', 'data_date': 'str', 'element': 'str', 'element_value': 'int',
'mflag': 'str', 'qflag':'str', 'sflag':'str', 'obs_time': 'str'},
chunksize = chunksize) as reader:
for update_df in reader:
chunkcount = chunkcount + 1
update_df['data_date'] = pd.to_datetime(update_df['data_date'], yearfirst=True)
for cur_country in country_prefixes:
country_df = update_df[update_df['station_id'].str.startswith(cur_country)]
west_eu_df = pd.concat([west_eu_df, country_df], ignore_index=True)
print(f"Read data in {chunkcount} chunks. Updating {len(west_eu_df)} records")
# Output file
west_eu_df.to_csv(download_path+dir_name+'/diff-data.csv', index=False, sep="|")
sfQuery = """CREATE OR REPLACE TEMPORARY TABLE TEMP_DIFF_DATA
(station_id TEXT,
data_date DATE,
element TEXT,
element_value INT,
mflag char(1),
qflag char(1),
sflag char(1),
obs_time TIME,
operation char(1))"""
cursor.execute(sfQuery)
print("table created")
sfQuery = 'PUT file://' + download_path+dir_name+'/diff-data.csv @%TEMP_DIFF_DATA'
cursor.execute(sfQuery)
print("file uploaded")
cursor.execute("COPY INTO TEMP_DIFF_DATA file_format = (type = csv field_delimiter = '|' skip_header = 1)")
print("data copied")
cursor.execute("BEGIN TRANSACTION")
sfQuery = """UPDATE STATION_DATA sd
SET sd.element_value = tdd.element_value
FROM TEMP_DIFF_DATA tdd
WHERE sd.station_id = tdd.station_id
AND sd.element = tdd.element
AND sd.data_date = tdd.data_date""";
try:
print("Executing update...")
cursor.execute(sfQuery)
except:
cursor.execute("ROLLBACK")
print("Transaction failed")
return 0
else:
cursor.execute("COMMIT")
print("Update transaction successful")
os.remove(download_path+dir_name+'/diff-data.csv')
return len(west_eu_df)The do_update function is similar to the do_delete function, except for the second SQL query that contains a SQL UPDATE statement.
The do_insert function
#------------------------------------------------------------------
# Argument(s):
# 1. Database connection cursor
# 2. File path
# Returns: Number of rows inserted
#------------------------------------------------------------------
def do_insert(cursor, dir_name):
print(">>> Starting insert operation <<<")
west_eu_df = pd.DataFrame(columns = column_names)
chunkcount = 0
with pd.read_csv(download_path+dir_name+'/insert.csv', names = column_names,
dtype={'station_id': 'str', 'data_date': 'str', 'element': 'str', 'element_value': 'int',
'mflag': 'str', 'qflag':'str', 'sflag':'str', 'obs_time': 'str'},
chunksize = chunksize) as reader:
for insert_df in reader:
chunkcount = chunkcount + 1
insert_df['data_date'] = pd.to_datetime(insert_df['data_date'], yearfirst=True)
for cur_country in country_prefixes:
country_df = insert_df[insert_df['station_id'].str.startswith(cur_country)]
west_eu_df = pd.concat([west_eu_df, country_df], ignore_index=True)
print(f"Read data in {chunkcount} chunks. Inserting {len(west_eu_df)} records")
west_eu_df.to_csv(download_path+dir_name+'/diff-data.csv', index=False, sep="|")
sfQuery = """CREATE OR REPLACE TEMPORARY TABLE TEMP_DIFF_DATA
(station_id TEXT,
data_date DATE,
element TEXT,
element_value INT,
mflag char(1),
qflag char(1),
sflag char(1),
obs_time TIME,
operation char(1))"""
cursor.execute(sfQuery)
print("table created")
sfQuery = 'PUT file://' + download_path+dir_name+'/diff-data.csv @%TEMP_DIFF_DATA'
cursor.execute(sfQuery)
print("file uploaded")
cursor.execute("COPY INTO TEMP_DIFF_DATA file_format = (type = csv field_delimiter = '|' skip_header = 1)")
print("data copied")
cursor.execute("BEGIN TRANSACTION")
sfQuery = """INSERT INTO STATION_DATA
(station_id, data_date, element, element_value, mflag, qflag, sflag, obs_time)
SELECT station_id, data_date, element, element_value, mflag, qflag, sflag, obs_time
FROM TEMP_DIFF_DATA""";
try:
print("Executing insert...")
cursor.execute(sfQuery)
except:
cursor.execute("ROLLBACK")
print("Transaction failed")
return 0
else:
cursor.execute("COMMIT")
print("Transaction successful")
return len(west_eu_df)The do_insert function is similar to the do_delete function, except for the second SQL query that contains a SQL INSERT statement.
Test the script
-
To verify that the script runs successfully, open a Terminal from the Jupyter Launcher.
-
In the terminal tab that will open, enter the following call:
python -c "from DataUpdaterJob import *; update_weather_data()" -
Script execution may require up to several minutes and the messages on the screen will offer updates on its progress.
-
Ideally, the script will run without an error, and you will see an output similar to that in the image below. Note that the dates and values will differ from that in the image when you execute the script.
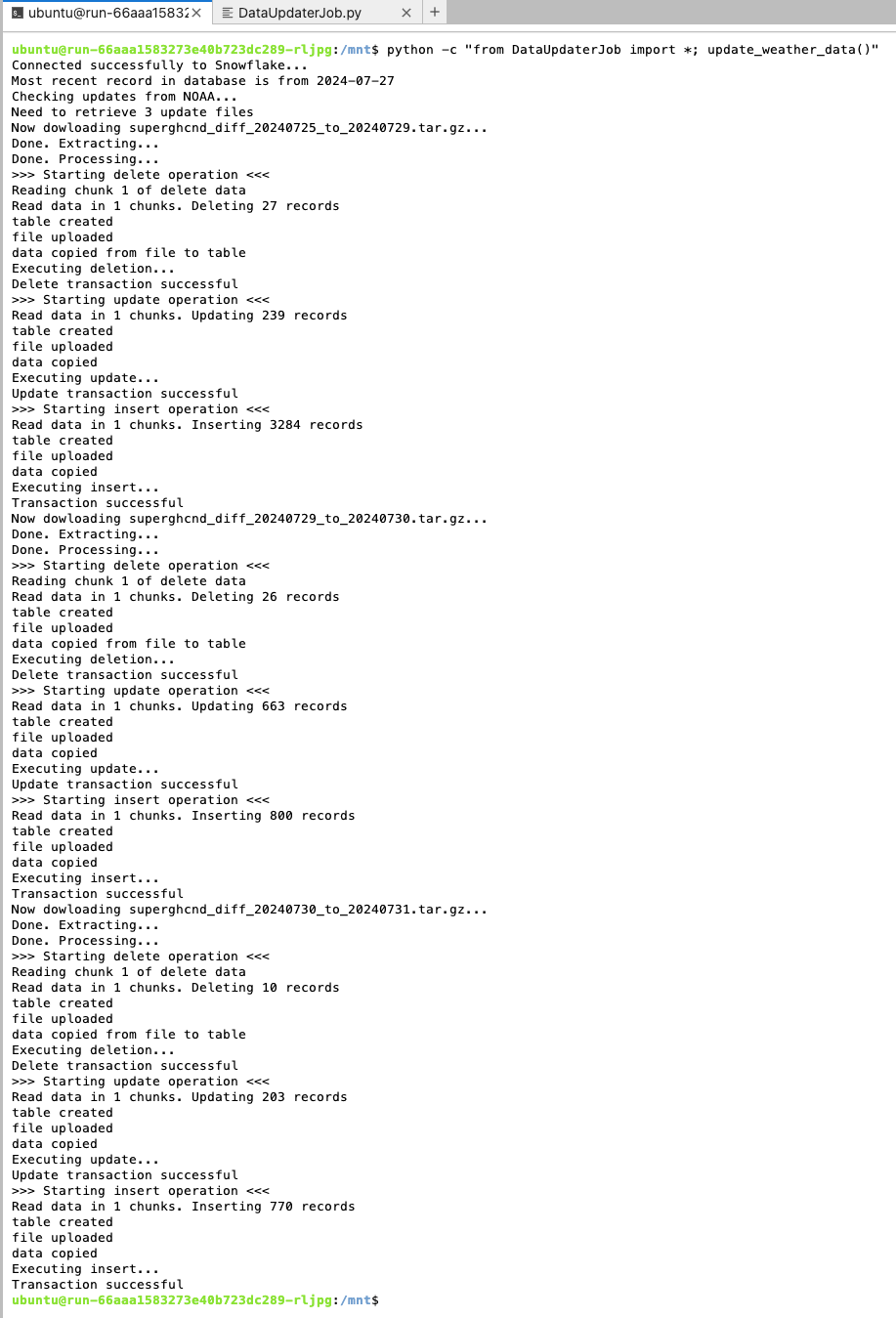
To set up your script as a job, follow these steps:
-
Click Jobs in Domino’s main navigation menu.
-
Jobs can run once or on schedule, with automated setup and teardown. That makes them especially valuable for periodical model training and when using high-cost hardware like GPUs. To ensure your script successfully runs as a job, click the Run button.
-
The job setup menu will open. Now, fill out the form:
-
Add a Job Title (e.g.
Weather Data Update). -
Enter the File Name (
DataUpdaterJob.py). -
Choose an execution Environment and Hardware Tier.
-
-
Since you are not using a cluster for the job and will connect directly to the database, you can click the Start button. Your job will start to execute and will appear in the list of Active jobs.
-
Once the job execution is completed, it will appear in the Completed run tab. Click on the job you have just run.
-
You will see that the job was completed successfully and the number of updates, deletes and inserts that the script performed. Like with the Domino Launcher, you can click on the job to see the detailed execution results view.
Schedule the Job
-
To schedule the job to run, click the Schedules tab at the top of the screen.
-
Click the Schedule a Job button. A form will appear. Similar to the previous job form, enter the details on the first step of the form.
-
Click Next. As you are not using a cluster for your job, click Next again.
-
Now, set a schedule for the job and click Next.
-
You can now add your email address so that Domino can notify you when the job completes successfully or fails.
-
Optional: If this job re-trains a model, you can also use it to update the model used in a Domino endpoint. You don’t need that at this time.
-
Click Create. The job will now appear in the Schedules job listings where you can edit and update the job configuration in the future.
-
Domino will trigger the execution at the scheduled time. When Domino executes the job, it will send you a confirmation email.