Domino’s monitoring feature uses the training data to calculate the probability distributions of all features and prediction columns to detect data drift for input features and output predictions of your model. It approximates these columns by creating bins, and then counting the frequency for each bin. This acts as the reference pattern.
The monitor feature uses prediction data to calculate the probability distribution, using the same bins, and then applies the specified statistical divergence or distance test to quantify the dissimilarity between the training and prediction distributions for each column.
By default, drift checks are scheduled to occur daily at 12 PM UTC.
|
Note
|
Prediction data is analyzed through 23:59 of the previous day. Data from the current day is not included. Domino reads the timestamps in the dataset if they are present; if not, it uses the ingestion timestamp. |
-
Model is registered for monitoring
-
Prediction data is available for Domino to monitor
Out-of-the-box, the Model Monitor supports several statistical tests. Each feature can have a different test. When a new model is registered, it inherits the global default test settings. However, you can change the test types and thresholds to values suitable for each model.
If you save these changes, they will be used for subsequent automated checks, such as when new predication data is uploaded or when Scheduled Checks run for the model.
Modify the test features
-
If you are using the monitoring feature for a Domino endpoint, go to Configure monitoring > Target Ranges to access the Configure Tests and Thresholds page.
-
If you are using the Model Monitor, in the navigation pane, click Model Monitor. Select the model that you want to monitor and then click Data Drift.
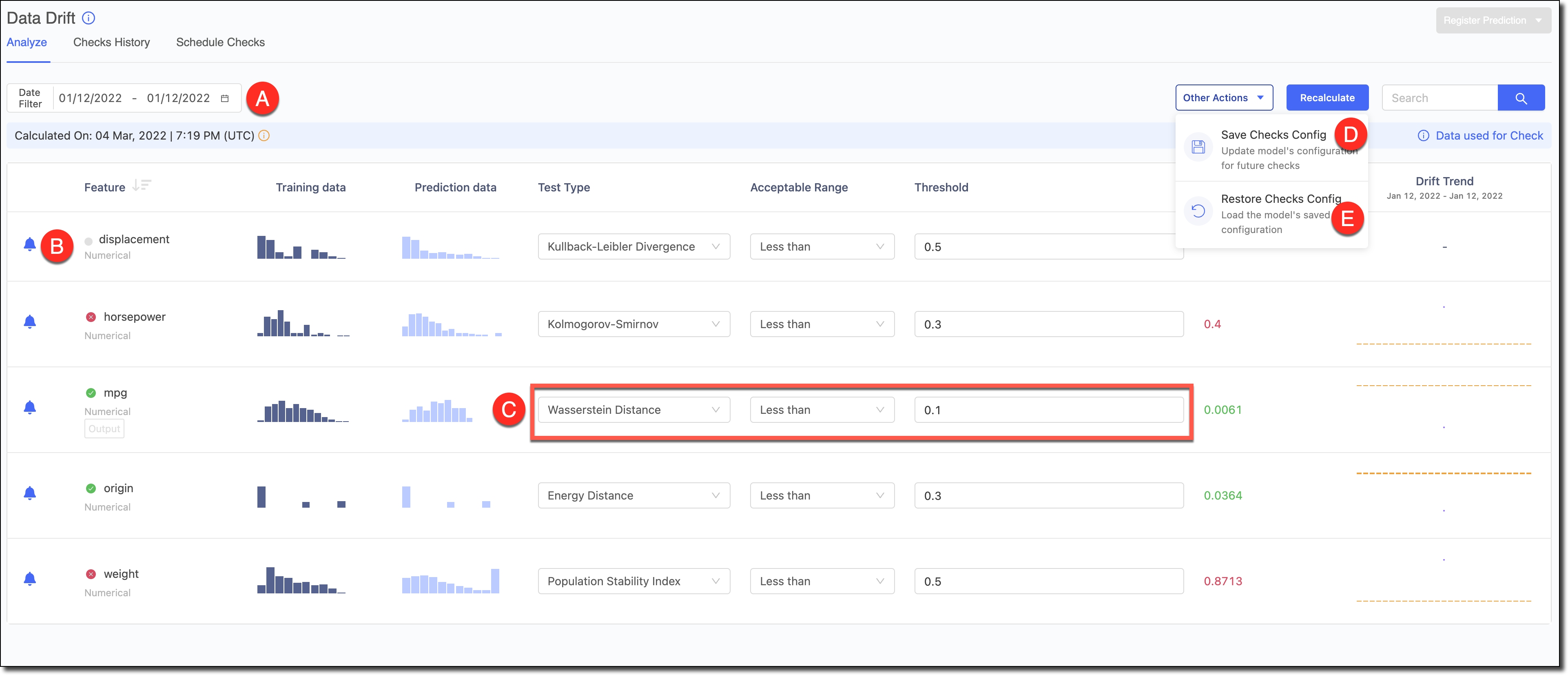
|
Note
|
If your model had a timestamp column declared, it’s used to get the timestamp of different predictions in the dataset. If the timestamp wasn’t declared, then the data’s ingestion time in the Model Monitor is used as its timestamp. |
A - Use the Date Filter to refine the date range and review the Drift and its trends for specific periods.
B - To reduce alert noise, click the bell icon next to features to disable alerts to exclude them from the Scheduled Checks.
C - Select the Test Type, the Acceptable Range, and the Threshold. See Data drift statistical tests for more information about test types.
Click Recalculate to see the results.
D - If you made changes to the tests and want to set them as the defaults for the model in subsequent automated checks, go to Other Actions > Save Checks Config to save the changes.
E - If you experimented with changes to the tests and wanted to load the model’s default configuration to reset the table, go to Other Actions > Restore Checks Config.
If you are using the monitoring feature for a Domino endpoint, click the X in the top right corner to close the page when you are finished.
Out-of-the-box, the Model Monitor supports several statistical tests.
|
Note
|
The lower the Population Stability Index (PSI) value, the better the prediction data matches the training data. If there is no difference between the data sets, the value is 0. Typically:
|
- Kullback–Leibler Divergence (Recommended)
-
Kullback–Leibler divergence (also called relative entropy) is a measure of how one probability distribution is different from a second, reference probability distribution.
The divergence can range from zero to infinity. A value of zero means there is no difference between the data sets.
This is a robust test that works for different distributions and therefore is most commonly used to detect drift.
- Chi-square Statistic
-
Chi-square test in another popular divergence test well-suited for categorical data.
The chi square statistic is a statistical hypothesis testing technique to test how two distributions of categorical variables are related to each other. Specifically, the chi-square statistic is a single number that quantifies the difference between the observed counts versus the counts that are expected if there was no relationship between the variables at all.
The divergence can range from zero to infinity. A value of zero means there is no difference between the data sets.
- Population Stability Index
-
Population Stability Index (PSI) is a popular metric in the finance industry to measure changes in distribution for two datasets. It produces less noise and has the advantage of a generally accepted threshold of 0.2-0.25.