Dataset owners can grant access to Domino users and groups. Only authorized users can import and access a dataset. Additionally, the actions that a user can perform on a dataset are determined by their Domino role.
When multiple users collaborate on a project, a data source used by one user might not be properly configured for another. Domino proactively alerts you about such problems on the project’s Data page and the Data tab in Domino workspaces.
Domino notifies you when you do not have permissions or when you have not configured your individual credentials. When you see this notification, request access from the data source owner.
You can change the permissions on a dataset to do the following:
-
Add new users or organizations.
-
Update roles for existing users or organizations.
-
Delete users or organizations.
Change who can access a Dataset
-
In the navigation pane, click Data.
-
Click Domino Datasets.
-
In the Your Domino Datasets area, go to the end of the row for the dataset whose permissions you want to change.
-
Click the three vertical dots and click Edit Permissions.
-
Enter the users or organizations to give them permission to the dataset.
NoteIf you want to give all project members access to the dataset, click the Add all project members link. -
Specify the user or organization’s role. Dataset roles are independent of Domino’s global user roles; see below for details about dataset roles.
-
Click Add.
NoteIn the Current Permissions area, you can modify the role as needed, or click the trash icon to delete permissions. -
Click Save Permissions.
NoteYou must restart executions to pick up permission changes.
Datasets have three roles: Owner, Editor, and Reader. These are independent of Domino’s global user roles. Roles determine the permissions that users have when they work with a dataset.
The table below describes the roles and access.
|
Note
| The Relates to Project Role column is only useful if you are migrating from versions of Domino earlier than 5.4 where datasets were integrated with projects. |
| Role | Relates to Project Role | Description |
|---|---|---|
Owner | Dataset Author |
|
Editor | Project Owner, Project Contributor |
|
Reader | ResultsConsumer, ProjectImporter, LauncherUser |
|
If you export and import project content to share data with other members of your team, the consumers of your project will receive the entire contents of your project files in their Runs and Workspaces. That works well if your project is small, simple, and narrowly scoped.
However, for large projects that produce many data artifacts, you might want to expose them to your consumers in smaller, curated subsets. You can do this with Domino datasets.
Consider the following project.
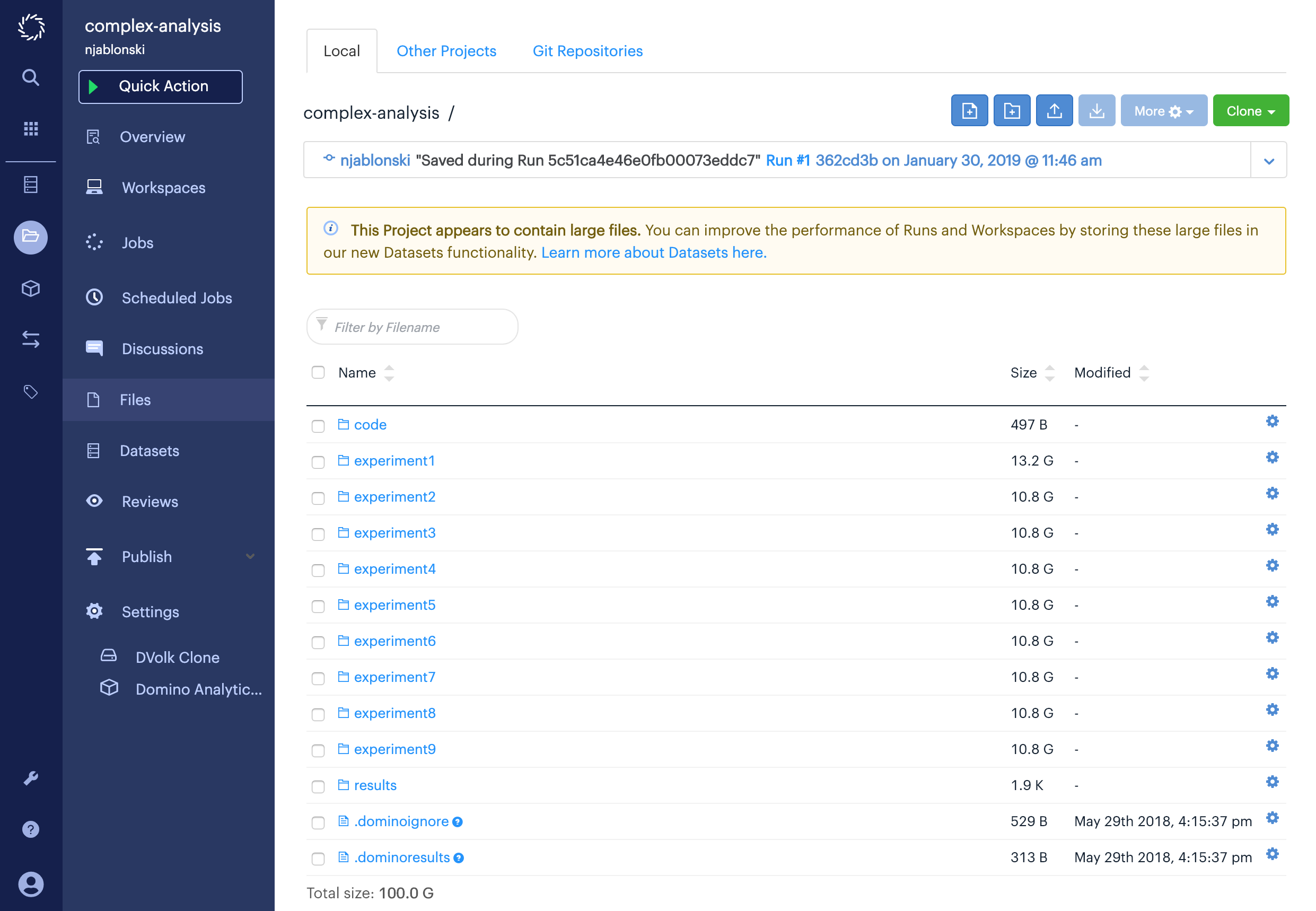
This project has a small folder full of code and nine folders with various kinds of output data. Each data folder is larger than 10GB, and the whole project is 100GB. It would be impractical to ask your data consumers to import this project, but you also don’t want to separate the data from the code that produced it by moving the data to a different project.
You can organize the data into datasets, with one dataset for each type of data in which your consumers are interested.
In this example, suppose you have two colleagues who want to consume your data.
One of them is only interested in the data from the experiment1 folder, and the other is only interested in the data from experiment9.
You can create and write two datasets with scripts like the following, where it’s assumed you have named the datasets experiment1-data and experiment9-data.
experiment1-populate-dataset.shcp -R $DOMINO_WORKING_DIR/experiment1/. /domino/datasets/experiment1-data/experiment9-populate-dataset.shcp -R $DOMINO_WORKING_DIR/experiment9/. /domino/datasets/experiment9-data/Your consumers can then mount only the datasets in which they are interested.
If you are working with data at this scale, write it to datasets whenever you produce it, instead of storing it in your project files.