Snowflake is one of the most prominent data storage services. When you move large volumes of data to the model, it increases costs and involves security risks. As a result, many shift to an approach where the model comes to the data, also known as in-database scoring. Domino pushes models down to Snowflake via Snowpark integration and connects the data back to the Domino platform to monitor those models for drift and accuracy.
After you train your model in Domino and write the necessary inference logic that you want to execute from within Snowflake, Domino lets you push model artifacts and associated Project Files necessary to execute the inference code in Snowflake as a Snowpark UDF.
|
Note
|
Snowpark is a library that lets users build applications (with a high level language like Scala) that run in Snowflake compute environments where the data resides. The core abstraction in Snowpark is the DataFrame. In addition to built-in capabilities in the Snowpark library, users create user-defined functions (UDFs) for custom operations. Both the DataFrame and UDFs are optimized to execute lazily on the Snowflake server. |
The model that you create in Domino must meet these requirements to be hosted in Snowflake:
-
Create your model in Python 3.8.
-
Create a file named
requirements.txtin the root folders (for example, therootfolder of the main Git-based project, an imported repository, or imported projects)This file defines the list of required packages for the model. See https://github.com/binder-examples/requirements/blob/master/requirements.txt for an example and Add Packages to Environments for more details.
-
These packages must be in the Snowflake Anaconda list: https://repo.anaconda.com/pkgs/snowflake/.
-
If you use external packages, your Snowflake instance must enable the usage of Anaconda packages.
-
-
Create Python-type hints for the model function input and return variables.
For the model to be monitored, you must meet these requirements:
-
A
timestampcolumn in your prediction dataset -
The name of the table that contains the prediction data
Domino looks for entries in the table with new timestamps to continuously ingest new data in batches.
-
Train a model with Domino Workbench to produce a model artifact and associated Project Files needed to invoke an inference with the model.
-
Instrument the inference function in the form of a Snowpark UDF with Snowflake packages. (See example below)
-
The prediction UDF typically accepts a DataFrame as an input to a prediction.
-
The result of the prediction (also typically a DataFrame) is returned as a response to the caller of the UDF
-
-
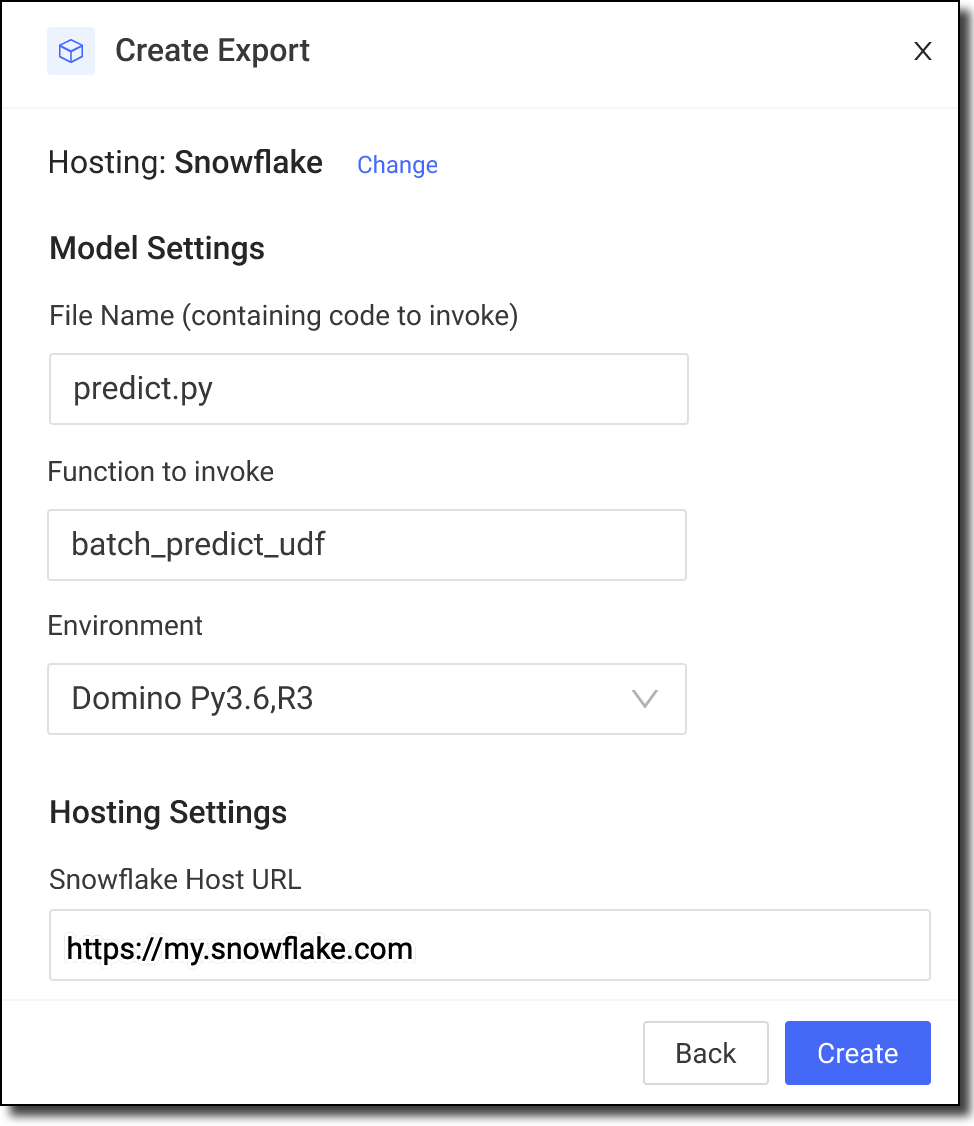
With a Domino publish flow (via the Domino web application), deploy the model as a Snowpark UDF to a Snowflake endpoint. The presented dialog prompts you to enter the necessary information to create a session with Snowflake and upload the custom function and necessary artifacts to create a Snowpark UDF.
 Tip
TipIn Snowflake URL, enter the URL that uniquely identifies the Snowflake account in your organization in the form https://<account-id>.snowflakecomputing.com.-
Information to create a Snowflake session includes key identifiers for the account (URL, role, credentials via username, and password) and JDBC settings (stage, warehouse, DB, and schema).
-
Domino adds the model artifacts (model file, UDF contained python file, and dependent python modules) to the Snowflake session.
-
Domino registers the UDF with Snowflake.
-
-
(Optional) If you make changes, deploy a new version. This action packages the current state of the project (also known as the HEAD commit on the main branch) as a new version of the exported model. Then, Snowflake overwrites the published UDF.
-
From the Exports page, click the name of the model for which you want to create a new version.
-
Go to Actions > Push new version.
-
Enter the name of the file that contains the predict function and the name of the predict function to call from the external provider.
-
If necessary, select a different Environment in which to run the model.
-
On the Next page, enter your Snowflake Username, enter you Snowflake Password, and select a User Role for the external provider. Then, click Authenticate & Export.
-
-
(Optional) After your exported model has been used for inference and it has saved model inputs and predictions to a supported data store, configure the model to monitor for data drift and model quality in Domino. See Model Requirements and Set up Model Monitor.
-
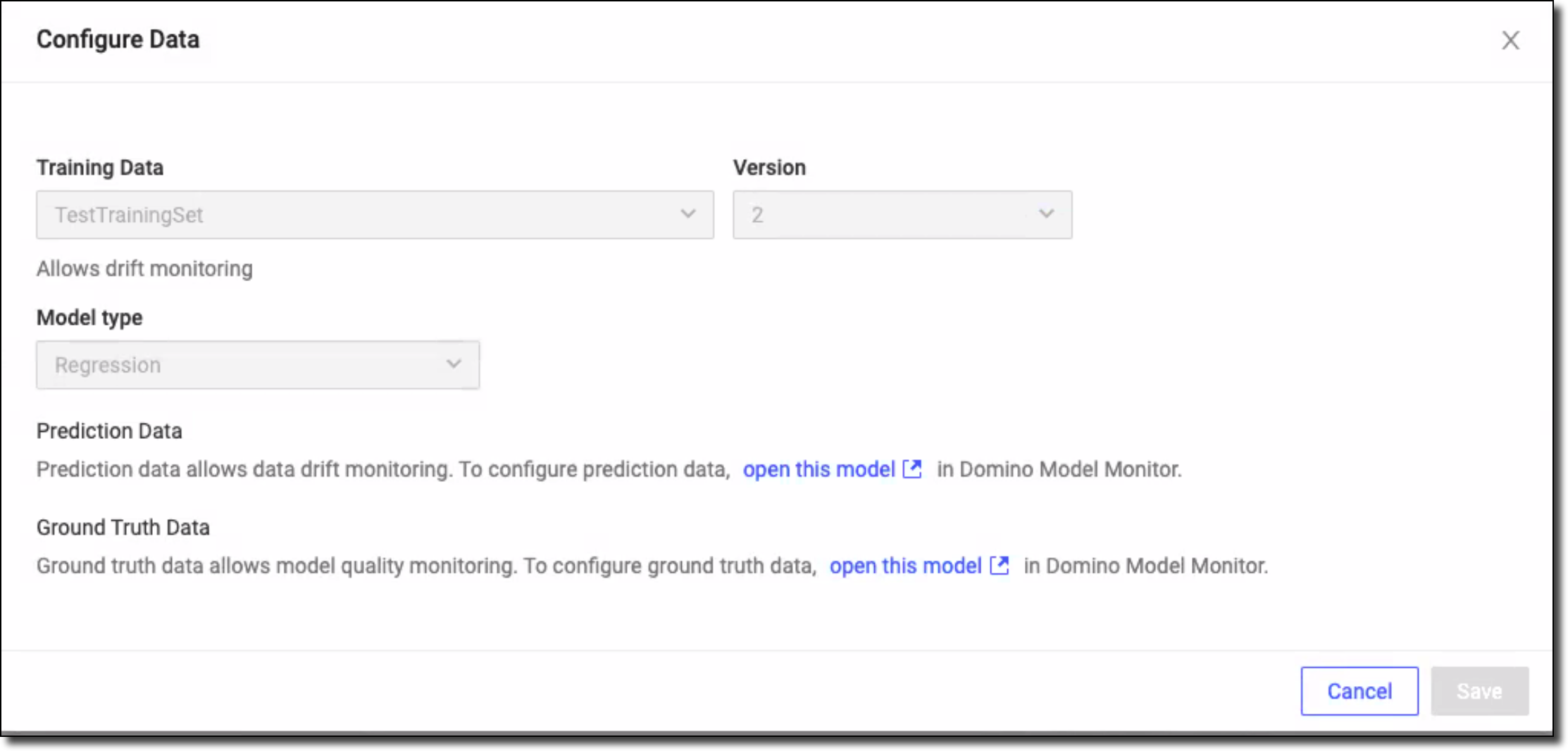
Go to Monitoring > Configure Monitoring > Data.
-
From the Configure Data window, select the Training Data and the Version for the Domino training set on which the model was trained. See Domino Training Sets.
-
From Model type, select Classification or Regression depending on your model type. If your Training Set code includes prediction data defined in target_columns, select the model type that matches your Training Set:
-
If target_columns is a categorical column, select Classification.
-
If target_columns is a numerical column, select Regression.
-
-
After the model is registered, the system shows options to add Prediction Data and Ground Truth Data.
NoteYou must wait until Training Data is ingested to add this information. After the data is ingested, click the open this model link for the data to add.
-
Click Save.
-
See Test defaults to set the targets for your data drift and model quality metrics and click Next when you’re done.
-
See Set Scheduled Checks to define the schedule for when monitoring results are calculated and updated and click Next when you’re done.
-
To send email notifications if thresholds are breached based on the Scheduled checks, in Send alerts to these email addresses, type or paste a comma- or semicolon-separated list of email addresses.
-
Click Save & Test.
-
-
(Optional) Use the Exports page to monitor your externally hosted data science models. The model monitoring feature detects and tracks data drift in the model’s input features and output predictions. See Use Monitoring for more information about model monitoring.
-
In the navigation pane, click Exports to review the Drift and Model Quality columns.

-
Inspect the results.
-
A green circle with a checkmark indicates that the drift and model quality metrics are healthy.
-
A red circle with a number indicates the number of alerts that exceed the threshold for the drift or metrics during the most recent check.
-
A gray circle without any icon or number indicates a null value; no metrics are available.
-
-
After this setup, call the UDF from inside your Snowpark Python application to perform inference against a Domino trained model.
-
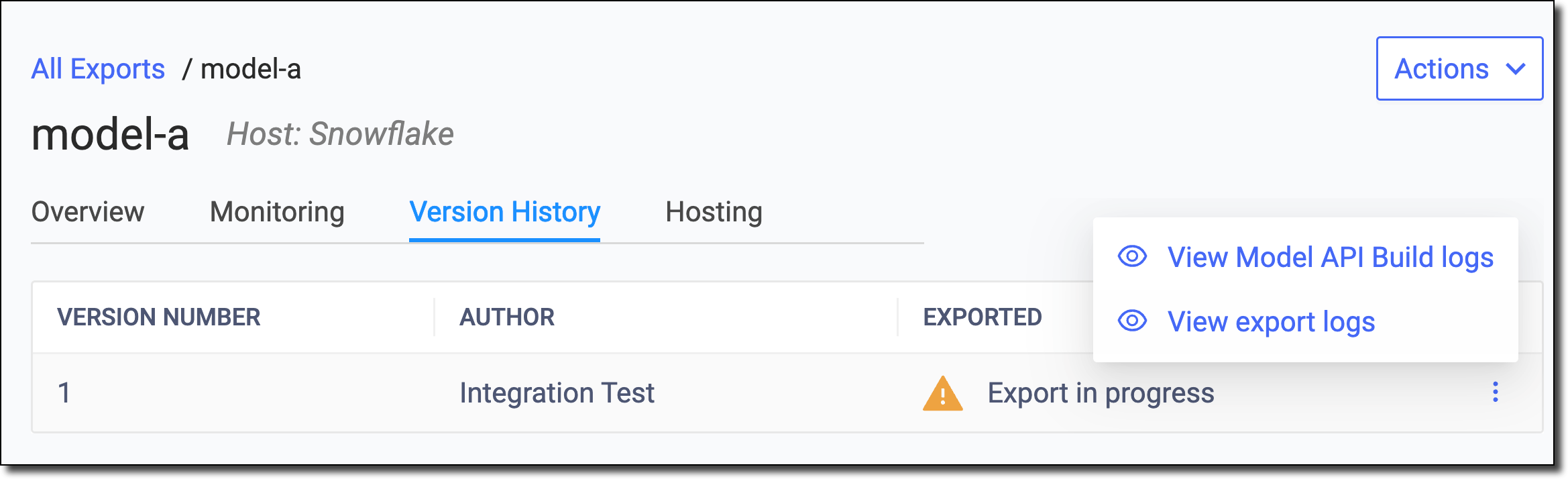
To gain the most insight, examine logs for the export:
-
Go to the Jobs dashboard of the Project and examine the last Domino Job for the export.
-
Use the Export UI (view export logs) to navigate to the Domino Job that was used for this export.
-
Examine the User Output under the Job.
 Note
NoteFor Snowflake models, when you hover over the command on the Jobs page, the password SNOWFLAKErepresents an environment variable, not your actual password.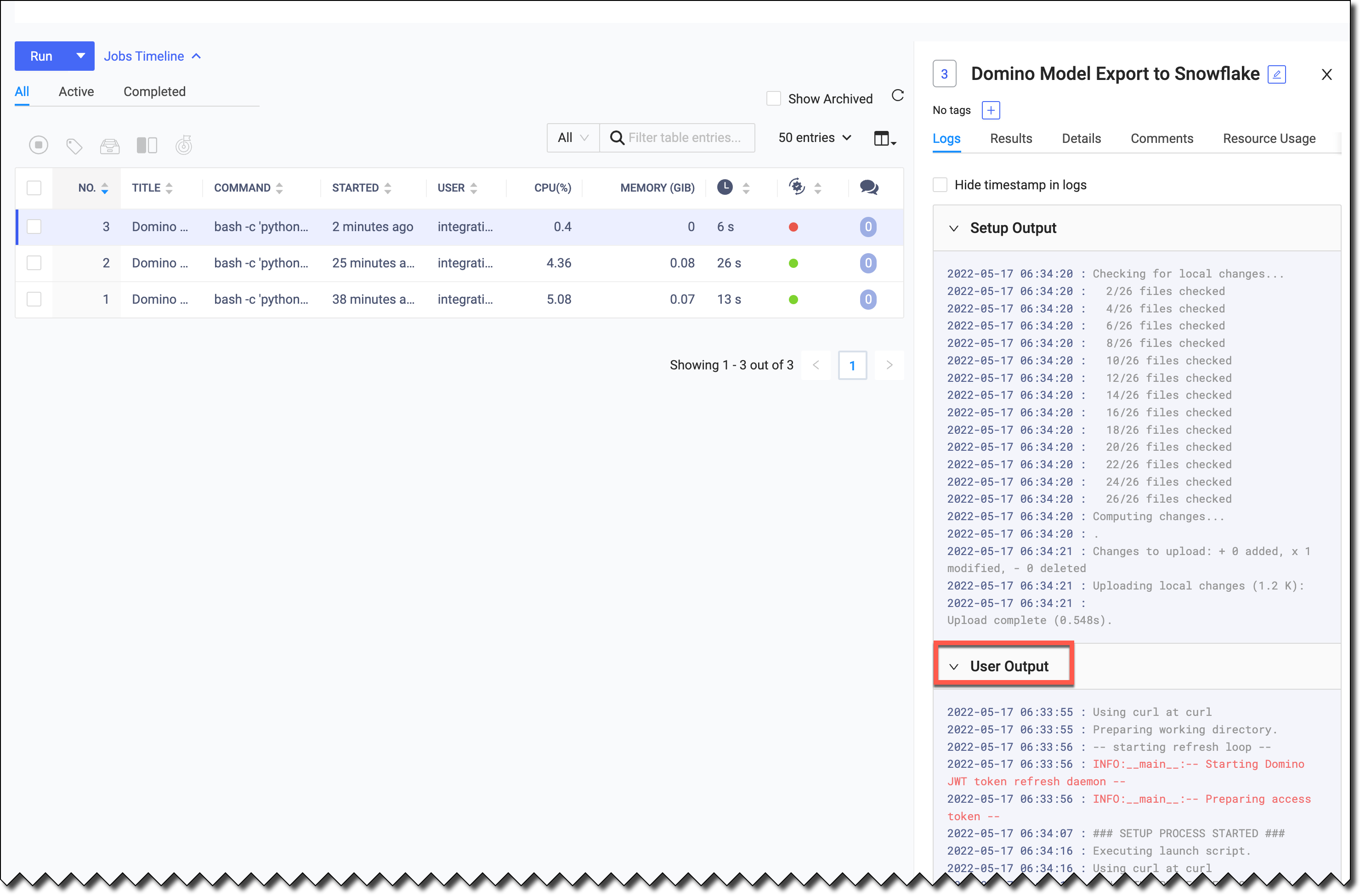
-
-
If your Domino model uses an external file, such as a pickle file in the predict function, you must specify a different directory path for Snowflake than for Domino. See Reading Files from a UDF.
-
Authentication or networking issues might cause exports to fail.
If an export to Snowflake fails because of code issues, you might have to update the model. Then, you can push a new version.
|
Note
| If you push a new version, the version number increments the next time you export the model. |