To monitor a model’s data drift you must ingest training data. Training data is the data used while constructing a model that leverages machine learning techniques. Training data records must include both model input values and a previously-known corresponding output for each input value combination from which the model can learn.
Your model’s training data is used to analyze data drift. This topic describes how to register a training set for monitoring purposes.
Before you proceed, you must create a training set that was used to build a model (.pkl file), and then that model was deployed into a model API.
-
On the model API’s page, click Monitoring. The page shows the Monitoring is waiting for data message until you configure training data and ground truth data.
-
Click Configure Monitoring > Data.
-
From the Configure Data window, select the Training Data and Version.
-
Select Classification or Regression, depending on your model type. If your Training Set code includes prediction data defined in
target_columns, select the model type that matches your Training Set:-
If
target_columnsis acategoricalcolumn, select Classification. -
If
target_columnsis anumericalcolumn, select Regression.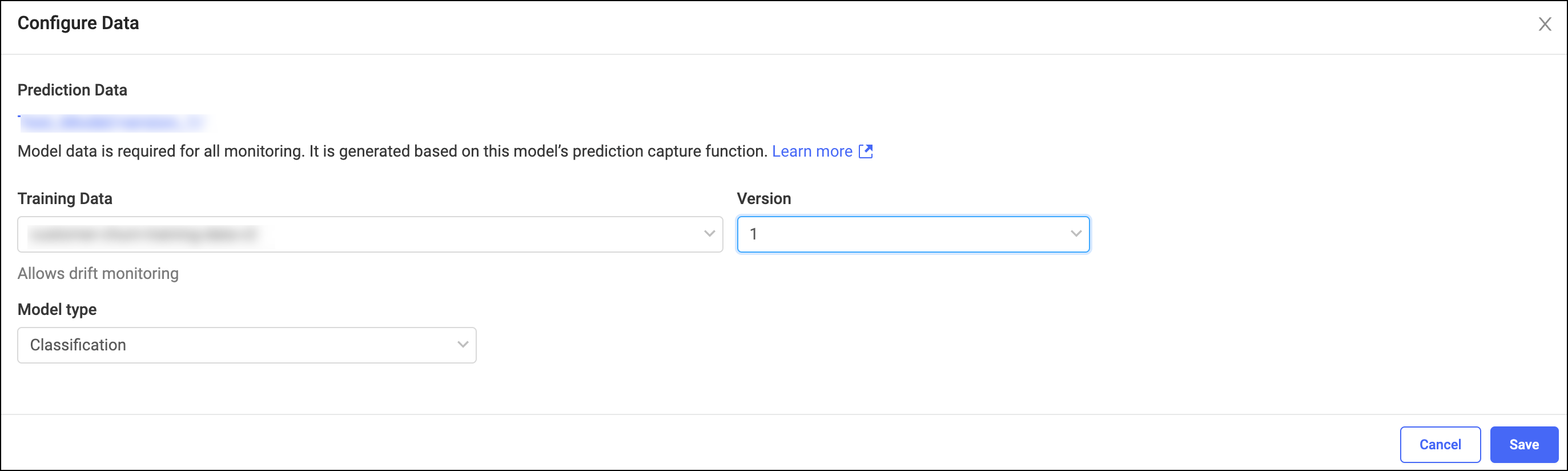
-
-
Click Save.
|
Note
| When using the Configure Data window to register a model for monitoring, the default binning strategy will be used to create bins for both numerical and categorical variables. To change the binning strategy, including the number of bins to use for numerical or categorical variables, reach out to your Domino representative. See Supported binning methods for more details on binning. |
Domino captures prediction data in a Domino Dataset in hourly batches.
Validate your setup without waiting for the Scheduled Check to run:
-
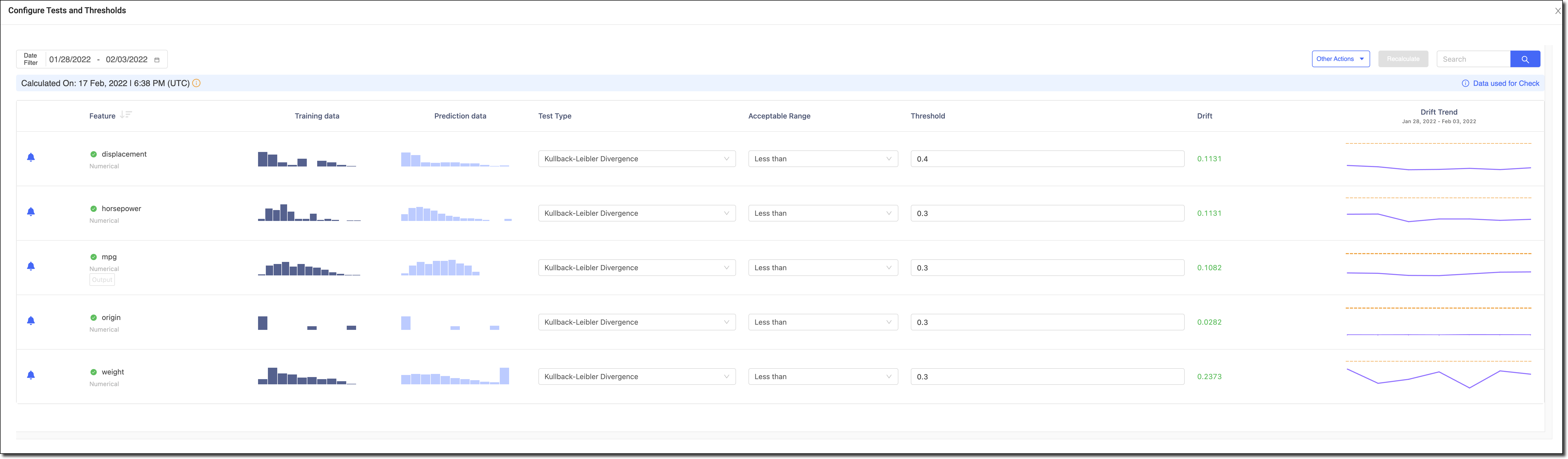
On the Model API’s Monitoring tab, go to Configure Monitoring > Target Ranges.
-
If the Configure Tests and Thresholds page populates with data, then your setup is complete. See Analyze Data Drift to learn how to configure tests and thresholds.