Fine-tune large language models (LLMs) and computer vision models with Domino Foundation Models to affordably take advantage of large, general-purpose models for your domain-specific needs.
Domino Code Assist provides a friendly UI to select a foundation model and fine-tune it on a new dataset. Domino Code Assist generates code to preprocess the data and execute a model trainer. After training, Domino publishes the fine-tuned model to the Experiments page along with the experiment’s parameters and logged metrics.
Domino Foundation Models give you:
-
Full transparency and control of training code.
-
Rapid testing and iteration with processed data.
-
Integration with MLflow to easily monitor results, register, and deploy models.
-
Rapid setup and configuration.
Domino Foundation Models leverage models and datasets from Hugging Face.
Ensure you are using a Domino Environment that has Domino Code Assist already installed. If not, follow the directions to install Code Assist.
In this example, the bert-base-uncased model is fine-tuned on the glue sst2 dataset from Hugging Face to improve its efficiency and effectiveness.
-
Start a Jupyter workspace to use Domino Foundation Model. For this feature, we recommend using a hardware tier with a minimum of 6 cores, 56GB RAM, and 1 Nvidia V100 GPU.
-
Hover over the Code Assist icon to show a popup menu.
-
Select Foundation Models > Text Classification > bert-base-uncased > FINE-TUNE to fine-tune the bert-base-uncased model from Hugging Face.
NoteDomino lists popular Hugging Face models in the search drawer for your convenience, but you can select any model from the Hugging Face model repository by changing the model_namevariable to the Hugging Face model name.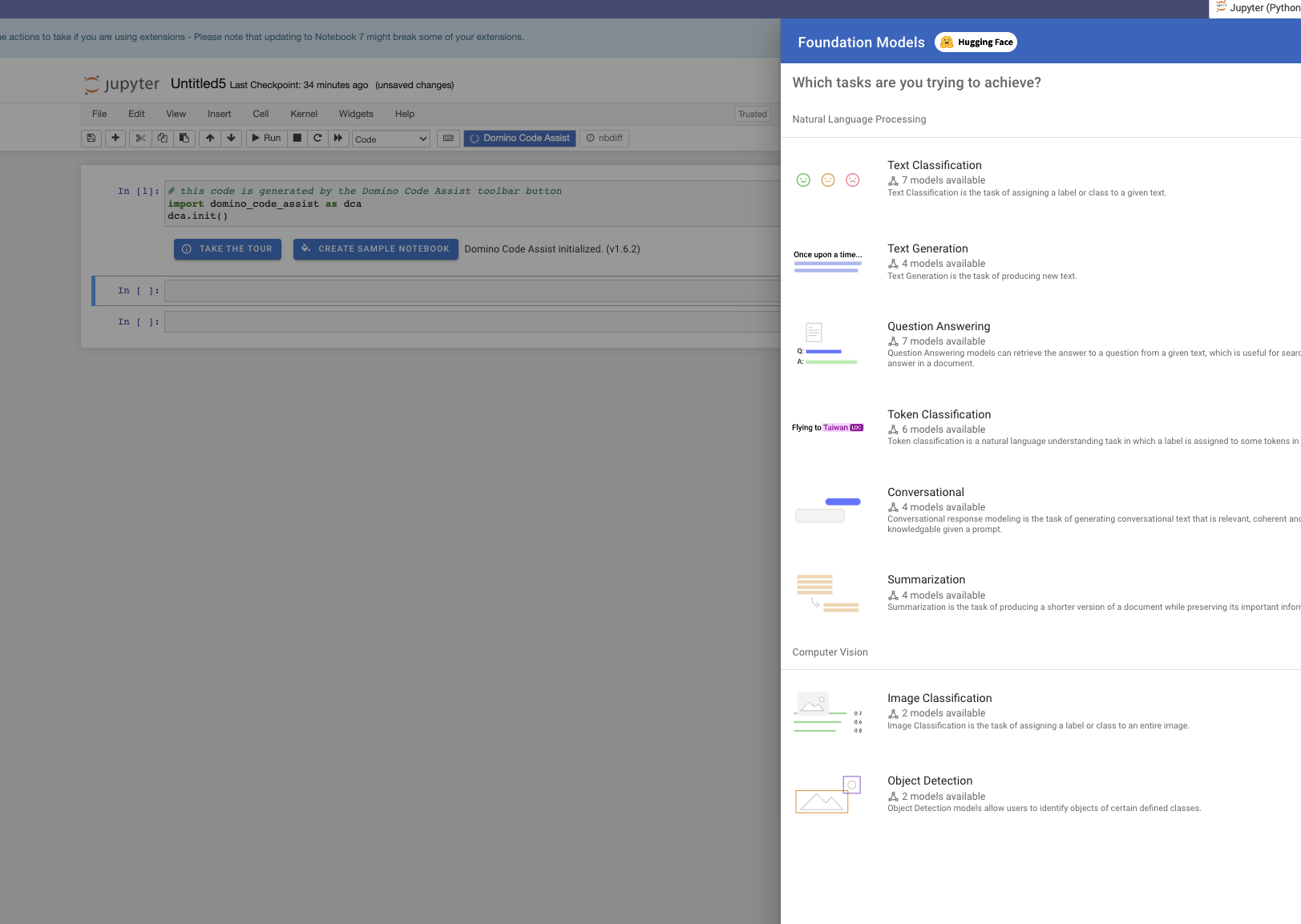
Fine-tune the model on the glue dataset with the sst2 config from Hugging Face. The dataset is comprised of two columns: A "sentence" column and a "label" column of the sentence’s sentiment.
-
Select Dataset > glue and then Config > sst2 to use the glue dataset with sst2 subset from Hugging Face.
NoteYou can select any dataset from the Hugging Face dataset repository by changing the dataset_namevariable to the Hugging Face dataset name. You can also use data from Domino Data Sources, Datasets, or local files for fine-tuning. -
Select Text column > sentence to specify
sentenceas the text column. -
Click on Training, then edit the hyperparameters and training arguments. Select Run to start fine-tuning.
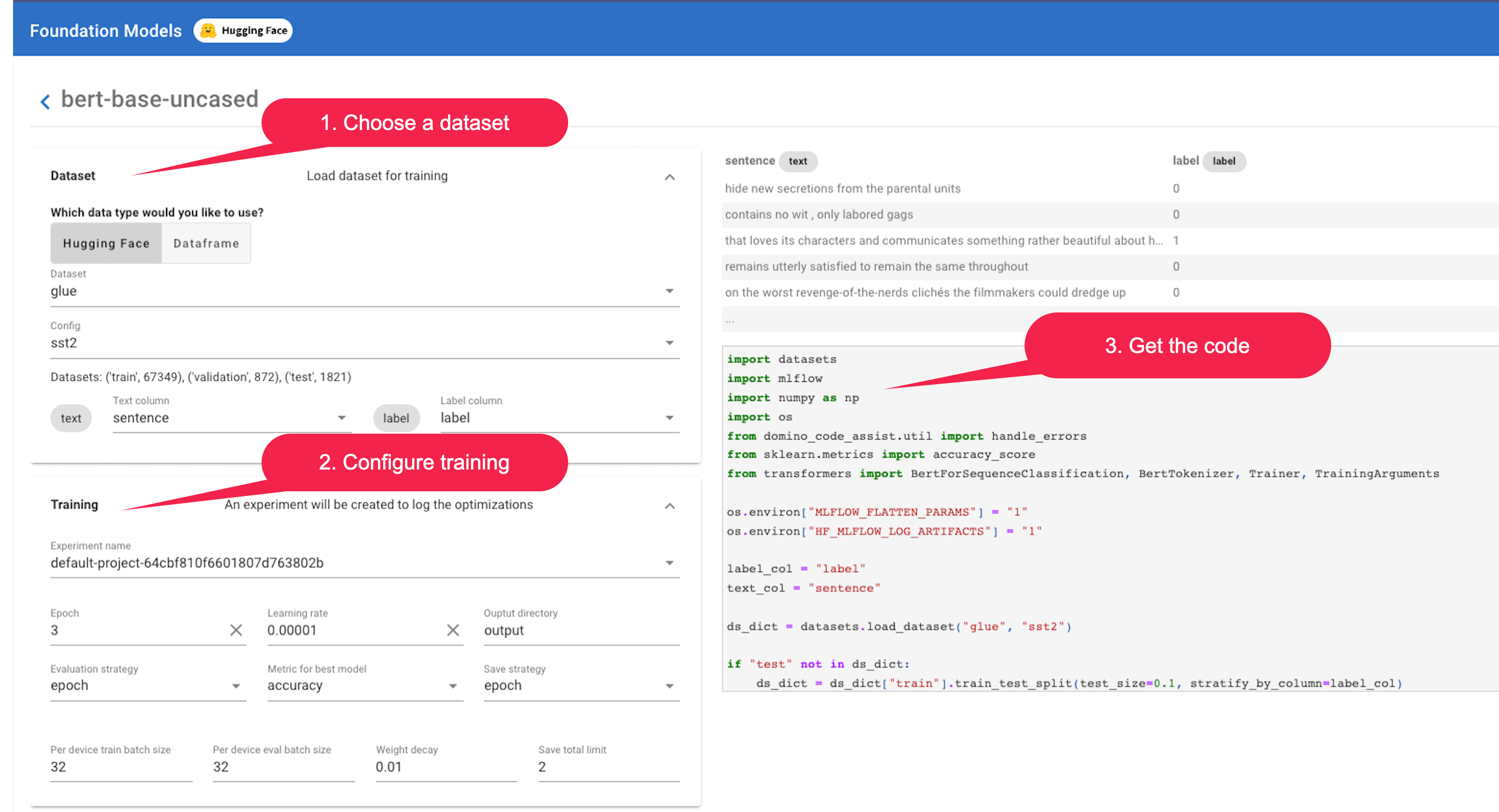
Code Assist automatically adds MLfLow tracking to let you view results and monitor progress. You can specify an experiment_name to override the default tracking experiment.
-
To view the experiment, click Open experiment.
-
Note the Run-name indicated and select your experiment.
View Parameters and Metrics, including real-time statistics such as loss, learning rate, and epoch. Once the fine-tuning finishes, your model appears in the Outputs tab.
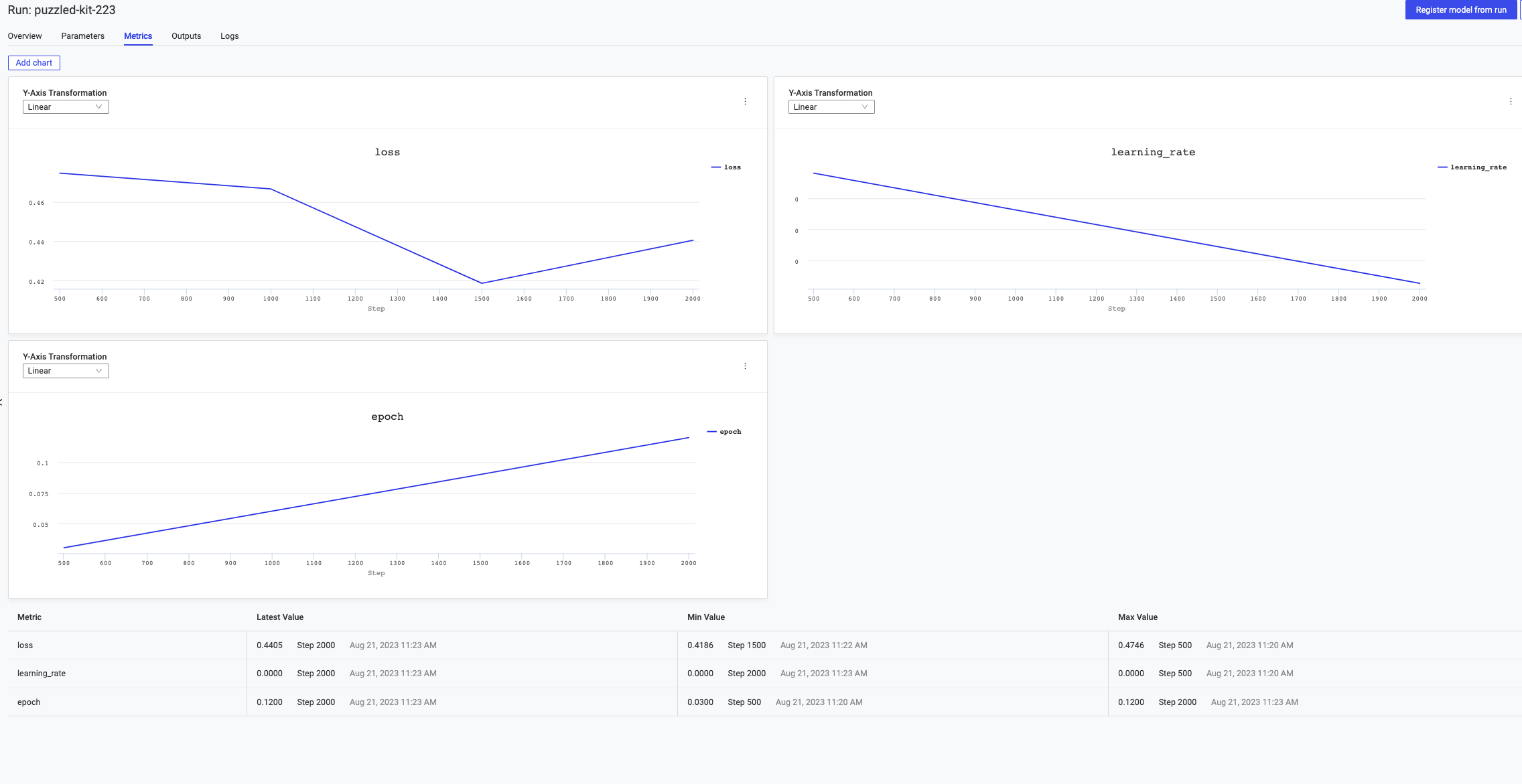
The code that Domino Code Assist generates is just the beginning. Data scientists can use this code to bootstrap their experiments or select Edit from the Code Assist popup to reconfigure their code.
For example, if you’d like to fine-tune the roberta-base model instead of the bert-base-uncased model, simply change the model_name variable in the autogenerated code from bert-base-uncased to roberta-base and rerun the code.
Feel free to use any model from the Hugging Face website or a private model that you have locally.
|
Note
| There are many combinations of models and datasets to fine-tune. You must ensure the fine-tuning dataset matches the model’s expected shape. Domino Foundation Models generates slightly different code for each task type such as the type of Hugging Face Auto Model used and data preprocessing. So, take care when changing models, datasets, or function parameters to avoid errors. |
If you want to tune hyper-parameters, update your code to run on a Ray cluster.