Data sources have a global scope in a Domino deployment and are accessible to anyone with the appropriate permissions in any project.
Use the following steps to connect to a Data Store.
|
Note
| Some Data Stores require additional steps, refer to the specific Data Source connector page for more details. |
-
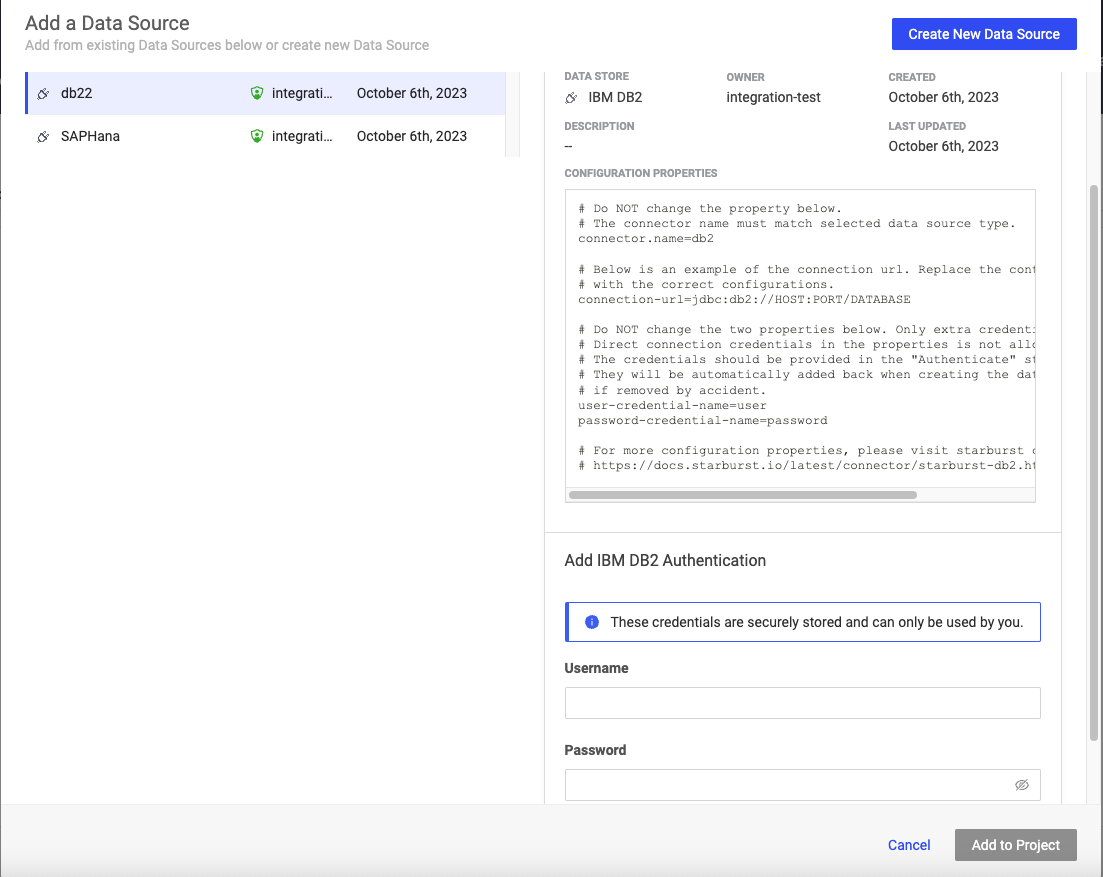
From the navigation pane, click Data > Add a Data Source.
-
Enter credentials for the Data Source.
Your admin can set up Data Sources to use either service account credentials or individual user credentials.
-
Click Add to Project.
You can add Data Sources to a project explicitly (Add a data source on project’s Data page) or implicitly when a Data Source is used directly in code from a project.
If a Data Source has been set up and you have permission to access it, you can add it to a project. This step is not strictly necessary, but it gives you visibility into which Data Sources are used in each of your projects.
If you don’t add a Data Source to a project, you can still use it in your code if you have permission to access it.
-
In your project, go to Data > Data Sources > Add a Data Source.
-
Select an existing Data Source from the list.
-
Click Add to Project.
After a Data Source is properly configured, use the Domino Data API to retrieve data without installing drivers or Data Source-specific libraries.
The auto-generated code snippets provided in your workspace are based on the Domino Data API. The API supports tabular and file-based Data Sources.
|
Note
|
The API supports Python and R. |
The Data API comes pre-packaged in the Domino Standard Environment (DSE). If you are using a custom environment that doesn’t have the Data API, you can install it.
The Data API’s Data Source client uses environment variables available in the workspace to automatically authenticate your identity. You can override this behavior using custom authentication.
Get code snippets
Domino automatically generates code snippets for accessing the Data Sources in your project using the Domino Data API. Code snippets are available for Python and R and customized for tabular and file-based Data Sources. The Data Source must be added to your project to enable snippets.
Here’s how to get a code snippet that you can copy and paste in your workspace:
-
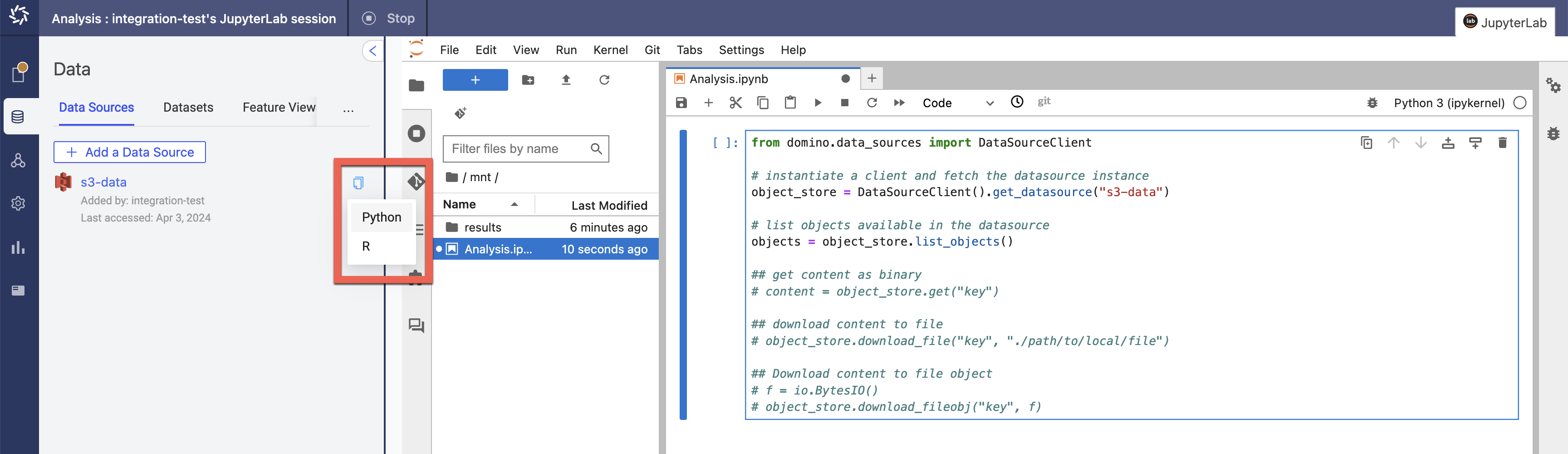
In your workspace, go to Data > Data Sources and click the code snippet button:
-
Click the copy icon to display language options.
-
Select Python or R to copy the code snippet in the desired language.
-
Paste the copied snippet into your own code, and modify it as needed.
For more auto-generated code, try Domino Code Assist.
|
Note
|
Domino data sources do not support querying nested objects.
The workaround is to The following is an example res = ds.query("""
select account_id, t1
from sample_analytics.transactions
cross join unnest (transactions)
as t(t1, t2, t3, t4, t5, t6)
""")
|
Query a tabular store
Assuming a data source named redshift-test is configured with valid credentials for the current user:
from domino.data_sources import DataSourceClient
# instantiate a client and fetch the datasource instance
redshift = DataSourceClient().get_datasource("redshift-test")
query = """
SELECT
firstname,
lastname,
age
FROM
employees
LIMIT 1000
"""
# res is a simple wrapper of the query result
res = redshift.query(query)
# to_pandas() loads the result into a pandas dataframe
df = res.to_pandas()
# check the first 10 rows
df.head(10)library(DominoDataR)
client <- DominoDataR::datasource_client()
query <- "
SELECT
firstname,
lastname,
age
FROM
employees
LIMIT 1000"
# table is a https://arrow.apache.org/docs/r/reference/Table-class.html
table <- DominoDataR::query(client, "redshift-test", query)
#> Table
#> 1000 rows x 3 columns
#> $firstname <string not null>
#> $lastname <string not null>
#> $age <int32 not null>List
Get the datasource from the client:
from domino.data_sources import DataSourceClient
s3_dev = DataSourceClient().get_datasource("s3-dev")library(DominoDataR)
client <- DominoDataR::datasource_client()You can list objects available in the datasource. You can also specify a prefix:
objects = s3_dev.list_objects()
objects_under_path = s3_dev.list_objects("path_prefix")keys <- DominoDataR::list_keys(client, "s3-dev")
keys_under_path <- DominoDataR::list_keys(client, "s3-dev", "path_prefix")By default the number of returned objects is limited by the underlying datasource. You can specify how many keys you want as an optional parameter:
objects = s3_dev.list_objects(page_size = 1500)keys = DominoDataR::list_keys(client, "s3-dev", page_size = 1500)Read
You can get object content, without having to create object entities, by using the datasource API and specifying the Object key name:
# Get content as binary
content = s3_dev.get("key")
# Download content to file
s3_dev.download_file("key", "./path/to/local/file")
# Download content to file-like object
f = io.BytesIO()
s3_dev.download_fileobj("key", f)# Get content as raw vector
content <- DominoDataR::get_object(client, "s3-dev", "key")
# Get content as character vector
content <- DominoDataR::get_object(client, "s3-dev", "key", as = "text")
# Download content to file
DominoDataR::save_object(client, "s3-dev", "key", "./path/to/local/file")You can also get the datasource entity content from an object entity (Python only):
# Key object
my_key = s3_dev.Object("key")
# Get content as binary
content = my_key.get()
# Download content to file
my_key.download_file("./path/to/local/file")
# Download content to file-like object
f = io.BytesIO()
my_key.download_fileobj(f)Write
Similar to the read/get APIs, you can also write data to a specific object key. From the datasource:
# Put binary content to given object key
s3_dev.put("key", b"content")
# Upload file content to specified object key
s3_dev.upload_file("key", "./path/to/local/file")
# Upload file-like content to specified object key
f = io.BytesIO(b"content")
s3_dev.upload_fileobj("key", f)# Put raw or character vector to object key
DominoDataR::put_object(client, "s3-dev", "key", what = "content")
# Upload file content to specified object key
DominoDataR::upload_object(client, "s3-dev", "key", file = "./path/to/local/file")You can also write from the object entity (Python only).
# Key object
my_key = s3_dev.Object("key")
# Put content as binary
my_key.put(b"content")
# Upload content from file
my_key.upload_file("./path/to/local/file")
# Upload content from file-like object
f = io.BytesIO()
my_key.upload_fileobj(f)Parquet
Because Domino uses PyArrow to serialize and transport data, the query result is easily written to a local parquet file. You can also use pandas as shown in the CSV example.
redshift = DataSourceClient().get_datasource("redshift-test")
res = redshift.query("SELECT * FROM wines LIMIT 1000")
# to_parquet() accepts a path or file-like object
# the whole result is loaded and written once
res.to_parquet("./wines_1000.parquet")client <- DominoDataR::datasource_client()
table <- DominoDataR::query(client, "redshift-test", "SELECT* FROM wines LIMIT 1000")
# We can use https://arrow.apache.org/docs/r/reference/write_parquet.html since we leverage the arrow library
arrow::write_parquet(table, "./wines_1000.parquet")CSV
Because serializing to a CSV is lossy, Domino recommends using the Pandas.to_csv API so you can leverage the multiple options that it provides.
redshift = DataSourceClient().get_datasource("redshift-test")
res = redshift.query("SELECT * FROM wines LIMIT 1000")
# See Pandas.to_csv documentation for all options
csv_options = {header: True, quotechar: "'"}
res.to_pandas().to_csv("./wines_1000.csv", **csv_options)client <- DominoDataR::datasource_client()
table <- DominoDataR::query(client, "redshift-test", "SELECT* FROM wines LIMIT 1000")
# We can use https://arrow.apache.org/docs/r/reference/write_csv_arrow.html since we leverage the arrow library
arrow::write_csv_arrow(table, "./wines_1000.csv")When you use the Domino Data API from a Domino execution, your user identity is verified automatically to enforce Domino permissions. The library attempts to use a Domino JWT token, or, if not available, a user API key.
-
In a Domino Nexus deployment, Data Sources can be accessed on both the
Localand remote data planes, with the exception of Starburst Trino. Data sources may not be usable in every data plane due to network restrictions. -
Connectivity issues may originate anywhere between your Domino deployment and the external data store. Consult your administrator to verify that the Data Source is accessible from your Domino deployment.
-
Create training sets using the Domino Data API.
-
Run or schedule a job to train your model or update your model’s predictions using the latest data.
-
Learn more about developing and deploying models in Domino.
-
Use model monitoring to detect data drift.