Track and manage your machine learning models with Domino’s MLflow-based model registry. The model registry lets you do the following:
-
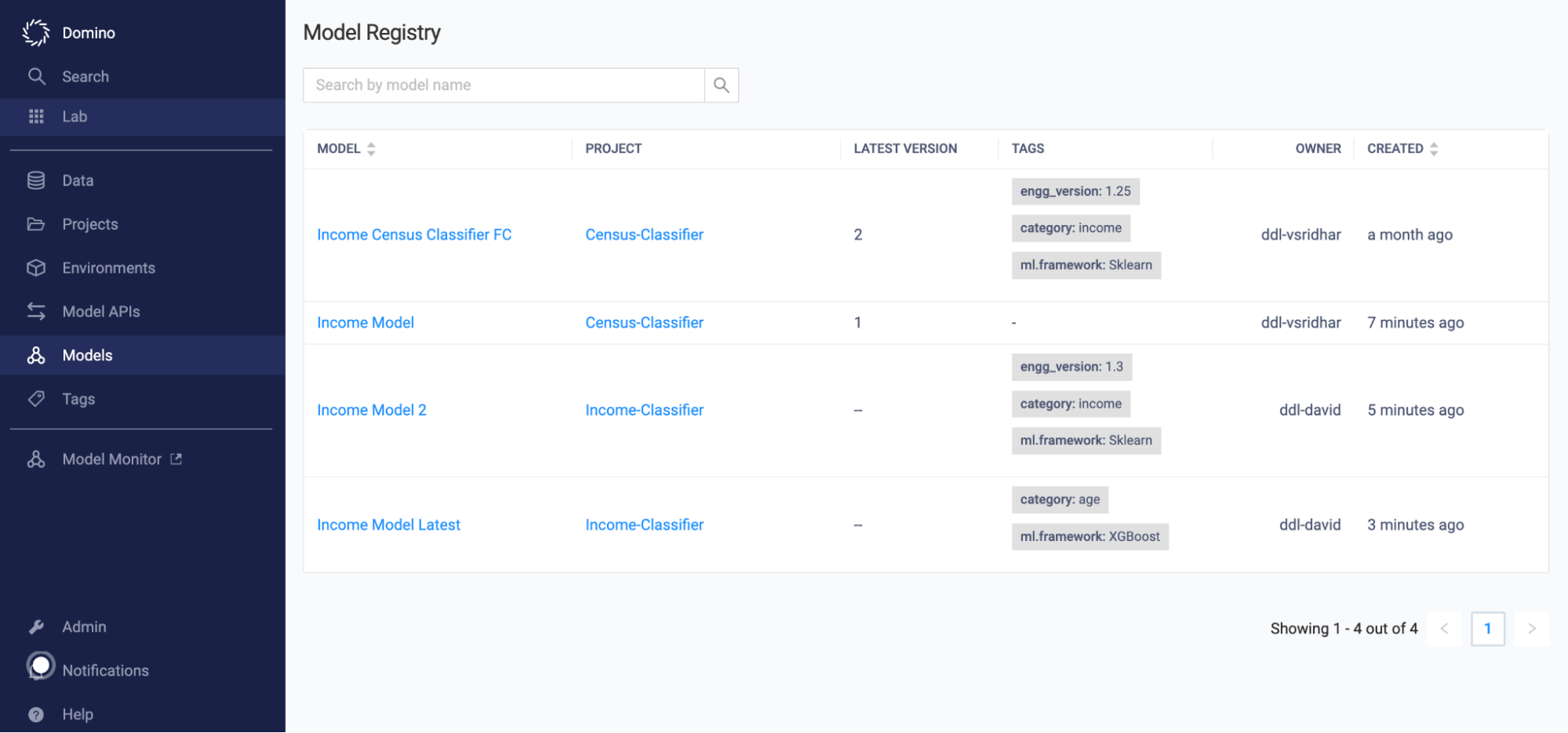
Discover models in project-scoped and deployment-scoped registries.
-
Record model metadata and lineage for auditability and reproducibility.
-
Create custom model cards to capture notes on fairness, bias, and other important information.
-
Manage model versions and deploy models to Domino-hosted or externally-hosted, endpoints.
-
Use RBAC (role-based access control) to limit who can view, edit, and collaborate on registered models.
|
Note
| Model registry doesn’t support R-based models. |
Domino uses MLflow to track and manage Domino experiments. Each Domino experiment can be associated with one or more models that you can publish to the model registry. You can register models using the MLflow API or through the Domino web UI.
Register models using the MLflow API
Register your model to the model registry programmatically with the MLflow API. This method is especially useful if you are already using Domino’s experiment management workflow to log training runs using MLflow. After you successfully train a model that you want to register, add the following code to name, tag, and register the model.
Use MLflow tags to add custom attributes or versions to a model in order to track additional metadata.
|
Note
| Model registry tags are distinct and cannot be used with Project tags or Model Monitoring tags. |
import random
import string
random_string = ''.join(random.choice(string.ascii_letters) for _ in range(3))
import mlflow.sklearn
from mlflow.store.artifact.runs_artifact_repo import RunsArtifactRepository
from mlflow import MlflowClient
from sklearn.ensemble import RandomForestRegressor
client = MlflowClient()
# Register model name in the model registry
name = "RandomForestRegression_" + random_string
registered_model = client.create_registered_model(name)
# create an experiment run in MLflow
params = {"n_estimators": 3, "random_state": 42}
rfr = RandomForestRegressor(**params).fit([[0, 1]], [1])
# Log MLflow entities
with mlflow.start_run() as run:
mlflow.log_params(params)
model_info = mlflow.sklearn.log_model(rfr, artifact_path="sklearn-model")
runs_uri = model_info.model_uri
# Create a new model version of the RandomForestRegression model from this run
desc = "A testing version of the model"
model_src = RunsArtifactRepository.get_underlying_uri(runs_uri)
mv = client.create_model_version(name, model_src, run.info.run_id, description=desc)
print("Name: {}".format(mv.name))
print("Version: {}".format(mv.version))
print("Description: {}".format(mv.description))
print("Status: {}".format(mv.status))
print("Stage: {}".format(mv.current_stage))
print("You created your first registered model!")
print(f"Go to the Models UI and click on the {name} model to see the Model Card.")Starting with Domino 5.11.1, you can now upload large artifact files directly to blob storage without needing to go through the MLflow proxy server. This is an experimental feature that must be enabled inside user notebook code by setting the environment variable MLFLOW_ENABLE_PROXY_MULTIPART_UPLOAD to true.
import os
# Enable MLflow multipart uploads
os.environ['MLFLOW_ENABLE_PROXY_MULTIPART_UPLOAD'] = "true"
# (default: `10_485_760` (10 MB)) - set to 200MB instead here. Select size based on maximum of 1000 chunks.
os.environ['MLFLOW_MULTIPART_UPLOAD_CHUNK_SIZE'] = '200_000_000'This feature is useful for both log_artifact calls and registering large language models. It is currently supported only in AWS and GCP environments. There are 2 additional settings available for configuring this feature:
-
MLFLOW_MULTIPART_UPLOAD_MINIMUM_FILE_SIZE- the minimum file size required to initiate multipart uploads. -
MLFLOW_MULTIPART_UPLOAD_CHUNK_SIZE- the size of each chunk of the multipart upload. Note that a file may be divided into a maximum of 1000 chunks.
See the MLflow multipart upload for proxied artifact access documentation for further details.
Domino helps you manage your models through model cards. Model cards are automatically created whenever you publish a model to the registry. Model cards help you do the following:
-
Ensure reproducibility and auditability by automatically tracking metadata, lineage, and downstream usage for each version of your models.
-
Document the model with information like data science techniques, limitations, performance, fairness considerations, and explainability.
-
Govern your models with built-in review and approval processes.
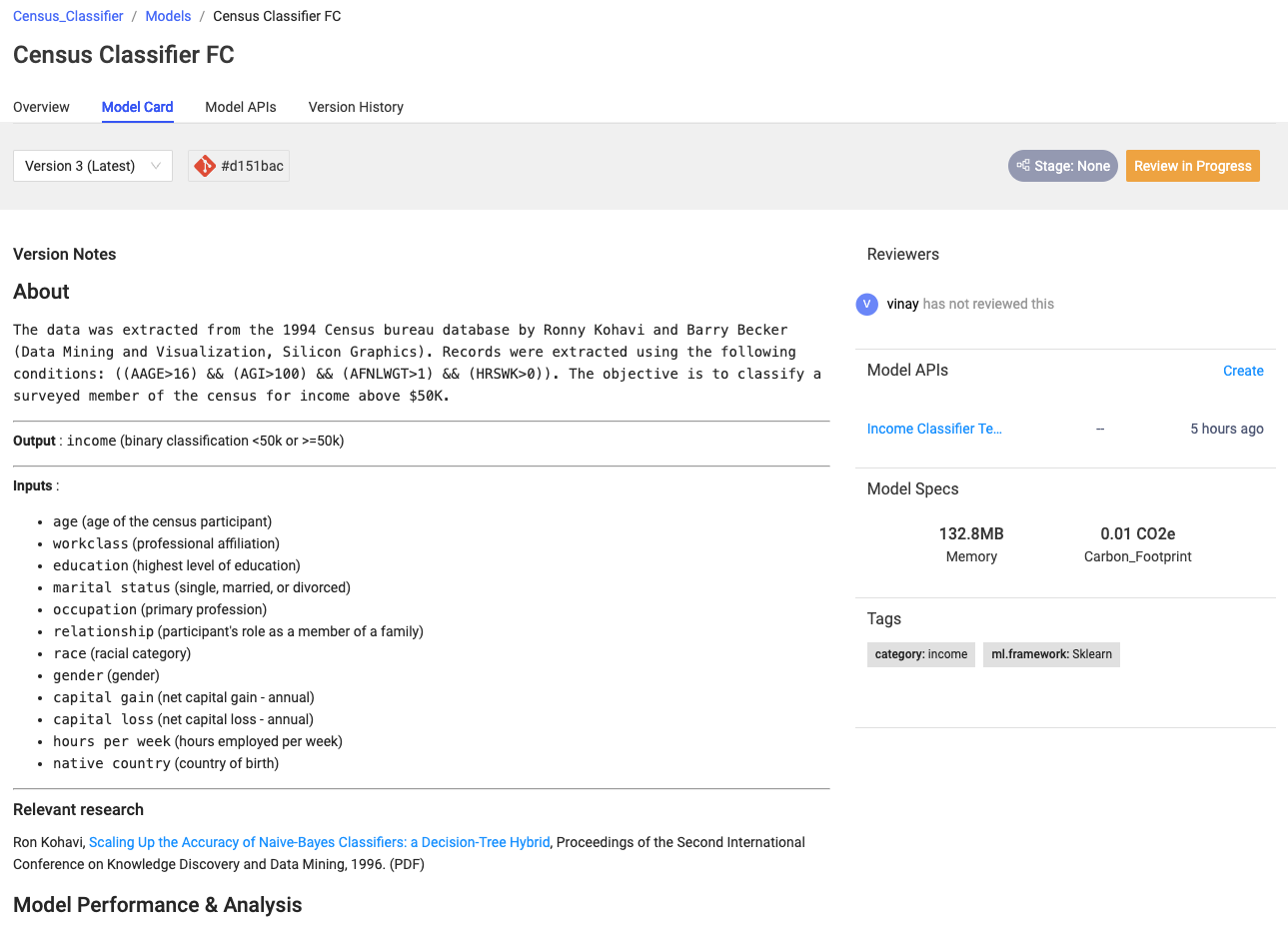
Lineage and metadata tracking
Domino automatically records the code, environment, workspace settings, and any datasets or data sources used for each experiment and associates them with the registered model. This system of record lets you track and reproduce the training context for your models for auditing and validation. Domino automatically adds all of this information to every model card for easy reference.
Custom model cards
When publishing your model, you can either import model cards from other sources or add your own markdown content to the model’s description. Custom model cards can be used to bring together other resources to provide a single point of truth for your model. For example, you could link to relevant research, dashboards, or external applications that help you evaluate models for fairness and bias.
You can update model card markdown programmatically, as in this example:
with open('Model Card v2.md', 'r') as file:
markdown_description = file.read()
client.update_registered_model(name, markdown_description)You can also directly edit the model card in the web UI:
-
Go to Models > Overview.
-
Select the Edit icon and edit the model card.
Domino uses project-based access controls to determine who can view, manage, and deploy models. Users must authenticate into Domino to use MLflow and Domino APIs for model tasks. Project user roles govern the model registry actions that a user can perform. For more information on model registry user roles, see model registry roles.
You can toggle Models in the Model Registry to be "publicly" discoverable to other Domino users within the organization. By allowing models to be publicly discoverable, organizations can improve visibility, reduce redundancy, and increase collaboration between otherwise siloed projects.
For example, a data scientist may want to explore models from other teams to avoid duplicating work. Meanwhile, a data science leader may want a consolidated view of all models across the organization to measure the success of the data science team.
In the Model Registry, users see two lists:
Global Models: A list of all the models that are marked publicly discoverable, regardless of whether the user has adequate project permissions to use the models. This serves as a dashboard for data scientists who want to explore and use models from other teams.
Collaborating Models: A list of all the models that a user is allowed to see. This includes models marked as publicly discoverable (annotated by the globe icon). Data science leaders can use this as a consolidated dashboard to track model development, usage, and metrics across projects.
Create a publicly discoverable model
To make a new model publicly discoverable:
-
Check the checkbox for Model Discoverability.
|
Note
|
The checkbox’s default setting is determined by the com.cerebro.domino.registeredmodels.newModelDiscoverability.default Central Config setting, which is initially set to true.
|
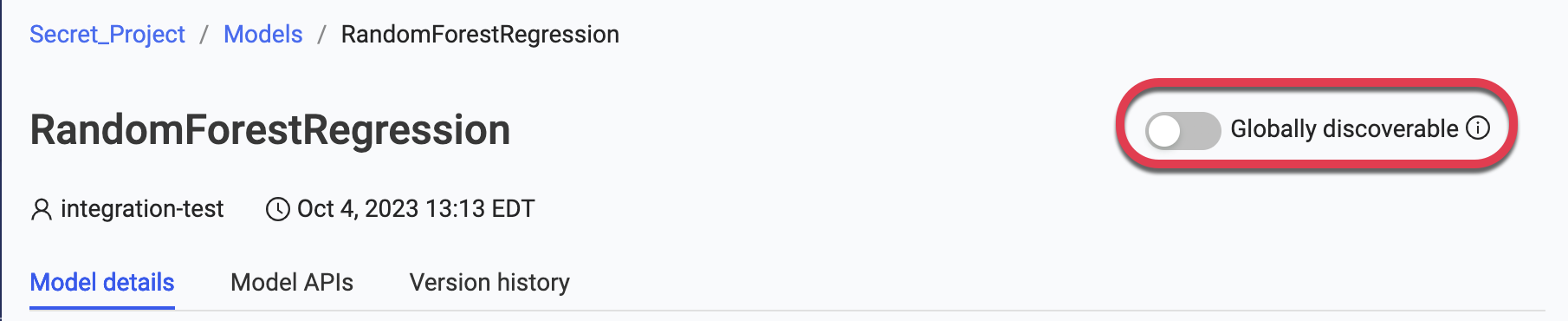
Toggle an existing model as discoverable
Once the model is created, a System Admin or Project Owner can toggle the model in and out of public discoverability using one of two ways.
-
Through the model card UI:
-
Through the public API PATCH endpoint (API not published on API guide).
|
Note
| If you turn off a Model’s public discoverable setting, Domino users without project permissions will no longer be able to see the model in their global model list or view the model card. |
Domino shows a limited, read-only version of the model card for publicly discoverable models to users without project permissions. The read-only model card hides the discoverability toggle, doesn’t allow edits to the model description, and does not render Model API components. Additionally, links on various components of the model card may lead to 403 error pages if the user doesn’t have the proper permissions to view assets such as Data Sources, experiment runs, code, etc.
You can request access to a read-only model from the project owners:
-
Go to the Model Card.
-
In the Model Card header, click How can I use this Model?
See examples of how to use various MLflow-supported models such as XGBoost, Sklearn, PyTorch, TensorFlow, and custom Pyfunc models for tasks like registering various flavors of MLflow models, enabling integrated monitoring, and creating Model APIs.
See Model governance and approval for the integrated model review process.