Domino supports connecting to a Hortonworks cluster through the addition of cluster-specific binaries and configuration files to your Domino environment.
At a high level, the process is as follows:
-
Connect to your Hortonworks cluster edge node and gather the required binaries and configuration files, then download them to your local machine.
-
Upload the gathered files into a Domino project to allow access by the Domino environment builder.
-
Create a new Domino environment that uses the uploaded files to enable connections to your cluster.
-
Enable YARN integration for the Domino projects that you want to use with the Hortonworks cluster.
Domino supports the following types of connections to a Hortonworks cluster:
You will find most of the necessary files for setting up your Domino environment on your edge node. To get started, connect to the edge node via SSH, then follow the steps below.
-
Create a directory named
hadoop-binaries-configsat/tmp.mkdir /tmp/hadoop-binaries-configs -
Create the following subdirectory inside
/tmp/hadoop-binaries-configs/.mkdir /tmp/hadoop-binaries-configs/configs -
(Optional) If your cluster uses Kerberos authentication, create the following subdirectory in
/tmp/hadoop-binaries/configs/.mkdir /tmp/hadoop-binaries-configs/kerberosThen, copy the
krb5.confKerberos configuration file from/etc/to/tmp/hadoop-binaries-configs/kerberos.cp /etc/krb5.conf /tmp/hadoop-binaries-configs/kerberos/ -
Copy the
hadoop,hive,spark, andspark2directories from/etc/to/tmp/hadoop-binaries-configs/configs/.cp -R /etc/hadoop /tmp/hadoop-binaries-configs/configs/ cp -R /etc/hive /tmp/hadoop-binaries-configs/configs/ cp -R /etc/spark2 /tmp/hadoop-binaries-configs/configs/ cp -R /etc/spark /tmp/hadoop-binaries-configs/configs/ -
On the edge node, run the following command to identify the version of Java running on the cluster.
java -versionYou should then download a JDK .tar file from the Oracle downloads page that matches that version. The filename will have a name like the following:
jdk-8u211-linux-x64.tar.gzKeep this JDK handy on your local machine for use in a future step.
-
Compress the
/tmp/hadoop-binaries-configs/directory to a gzip archive.cd /tmp tar -zcf hadoop-binaries-configs.tar.gz hadoop-binaries-configsWhen finished, use SCP to download the archive to your local machine.
-
Next, you’ll need to extract the archive on your local machine, add a java subdirectory, then add the JDK .tar file you downloaded earlier to the java subdirectory.
tar xzf hadoop-binaries-configs.tar.gz mkdir hadoop-binaries-configs/java cp jdk-8u211-linux-x64.tar.gz hadoop-binaries-configs/java/ -
When finished, your
hadoop-binaries-configsdirectory should have the following structure:hadoop-binaries-configs/ ├── configs/ ├── hadoop/ ├── hive/ ├── spark/ └── spark2/ ├── java/ └── jdk-8u211-linux-x64.tar.gz └── kerberos/ # optional └── krb5.conf -
If your directory contains all the required files, you can now compress it to a gzip archive again in preparation for uploading to Domino in the next step.
tar -zcf hadoop-binaries-configs.tar.gz hadoop-binaries-configs
Use the following procedure to upload the archive you created in the previous step to a public Domino project. This will make the file available to the Domino environment builder.
-
Log in to Domino, then create a new public project.
-
Open the Code page for the new project, then click to browse for files and select the archive you created in the previous section. Then click Upload.
-
After the archive has been uploaded, click the gear menu next to it on the Files page, then right click Download and click Copy Link Address. Save the copied URL in your notes, as you will need it in the next step.
After you have recorded the download URL of the archive, you’re ready to build a Domino environment for connecting to your Hortonworks cluster.
-
Click Environments from the Domino main menu, then click Create Environment.
-
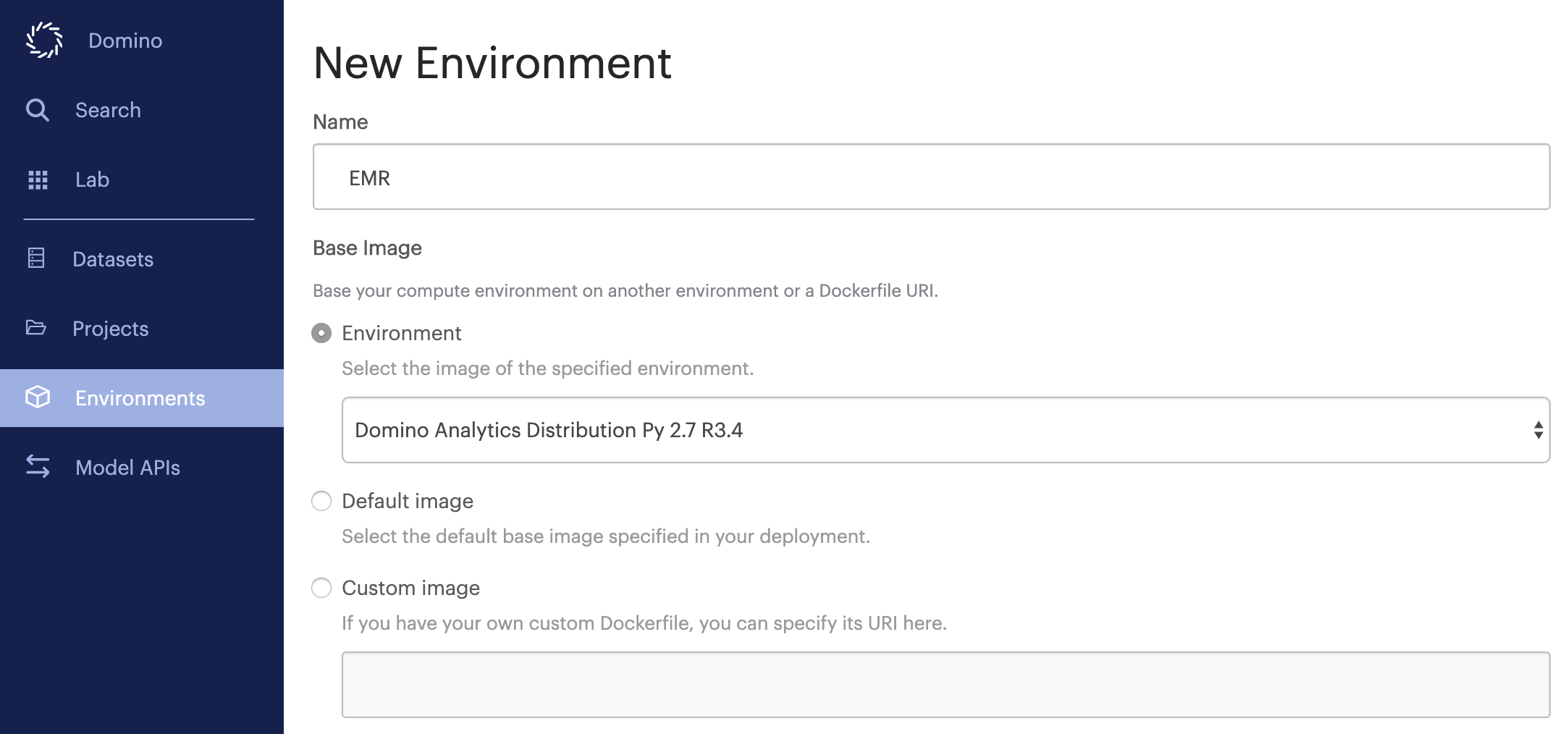
Give the environment an informative name, then choose a base environment that includes the version of Python that is installed on the nodes of your Hortonworks cluster. Most Linux distributions ship with Python 2.7 by default, so you will see the Domino Analytics Distribution for Python 2.7 used as the base image in the following examples. Click Create when finished.
-
After creating the environment, click Edit Definition. Copy the below example into your Dockerfile Instructions, then be sure to edit it wherever necessary with values specific to your deployment and cluster.
In this Dockerfile, wherever you see a hyphenated instruction enclosed in angle brackets like
<paste-your-domino-download-url-here>, be sure to replace it with the corresponding value you recorded in previous steps.Additionally, follow the instructions in the comments carefully, as you may need to modify the commands based on versions and filenames from your system. You may also need to edit commands that follow to match downloaded filenames.
USER root # Give user ubuntu ability to sudo as any user including root in the compute environment RUN echo "ubuntu ALL=(ALL:ALL) NOPASSWD: ALL" >> /etc/sudoers # Setup directories RUN mkdir /tmp/domino-hadoop-downloads && mkdir /usr/jdk64 # This downloaded gzip file should have the following # - java installation tar file in 'java' sub-directory # - krb5.conf in 'kerberos' sub-directory # - hadoop, hive, spark2 and spark config directories from hadoop edgenode in a 'configs' sub-directory # Make sure your URL is updated to reflect where you uploaded your configs. # You should have this saved from your preparation steps RUN wget --no-check-certiticate <paste-your-domino-download-url-here> -O /tmp/domino-hadoop-downloads/hadoop-binaries-configs.tar.gz && tar xzf /tmp/domino-hadoop-downloads/hadoop-binaries-configs.tar.gz -C /tmp/domino-hadoop-downloads/ # Install kerberos client and update the kerberos configuration file RUN apt-get update && apt-get -y install krb5-user telnet && cp /tmp/domino-hadoop-downloads/hadoop-binaries-configs/kerberos/krb5.conf /etc/krb5.conf # Install version of java that matches hadoop cluster and update environment variables RUN tar xvf /tmp/domino-hadoop-downloads/hadoop-binaries-configs/java/jdk-8u112-linux-x64.tar -C /usr/jdk64 && ln -s /usr/jdk64/jdk1.8.0_112 /usr/jdk64/default ENV JAVA_HOME=/usr/jdk64/default RUN echo "export JAVA_HOME=/usr/jdk64/default" >> /home/ubuntu/.domino-defaults && echo "export PATH=$JAVA_HOME/bin:$PATH" >> /home/ubuntu/.domino-defaults # Install HDP hadoop-client and spark binaries from Hortonworks Ubuntu repository. # Update the repo URL based for the version that matches what's running on your cluster. # This example shows version 2.6.5. RUN wget http://public-repo-1.hortonworks.com/HDP/ubuntu14/2.x/updates/2.6.5.0/hdp.list -O /etc/apt/sources.list.d/hdp.list && apt-key adv --keyserver keyserver.ubuntu.com --recv 07513CAD && apt-get update && apt-get -y install hadoop-client spark2-python spark-python # Copy hadoop, hive, spark and spark2 configurations RUN mv /etc/hadoop /tmp/domino-hadoop-downloads/hadoop-binaries-configs/configs/hadoop-etc-local.backup && mv /etc/spark /tmp/domino-hadoop-downloads/hadoop-binaries-configs/configs/spark-etc-local.backup && mv /etc/spark2 /tmp/domino-hadoop-downloads/hadoop-binaries-configs/configs/spark2-etc-local.backup && cp -r /tmp/domino-hadoop-downloads/hadoop-binaries-configs/configs/hadoop /etc/hadoop && cp -r /tmp/domino-hadoop-downloads/hadoop-binaries-configs/configs/hive /etc/hive && cp -r /tmp/domino-hadoop-downloads/hadoop-binaries-configs/configs/spark2 /etc/spark2 && cp -r /tmp/domino-hadoop-downloads/hadoop-binaries-configs/configs/spark /etc/spark # Update symlinks to point to correct configurations # When you are creating these symlinks make sure that right versions are specified. # Example: In the command 'ln -s /etc/spark2/2.6.5.0-292/0 /etc/spark2/conf' # make sure that 2.6.5.0-292/0 is right version according to the edgenode and set the correct version similar to the hortonwork edgenode. RUN rm /etc/spark2/conf && rm /etc/spark/conf && rm /etc/hadoop/conf && rm /etc/hive/conf && ln -s /etc/spark2/2.6.5.0-292/0 /etc/spark2/conf && ln -s /etc/spark/2.6.5.0-292/0 /etc/spark/conf && ln -s /etc/hadoop/2.6.5.0-292/0 /etc/hadoop/conf && ln -s /etc/hive/2.6.5.0-292/0 /etc/hive/conf # Update SPARK and HADOOP environment variables. Make sure py4j file name is correct as per your edgenode ENV SPARK_HOME=/usr/hdp/2.6.5.0-292/spark2 RUN echo "export HADOOP_HOME=/usr/hdp/2.6.5.0-292/hadoop" >> /home/ubuntu/.domino-defaults && echo "export HADOOP_CONF_DIR=/etc/hadoop/conf" >> /home/ubuntu/.domino-defaults && echo "export YARN_CONF_DIR=/etc/hadoop/conf" >> /home/ubuntu/.domino-defaults && echo "export SPARK_HOME=/usr/hdp/2.6.5.0-292/spark2" >> /home/ubuntu/.domino-defaults && echo "export SPARK_CONF_DIR=/etc/spark2/conf" >> /home/ubuntu/.domino-defaults && echo "export SPARK_MAJOR_VERSION=2" >> /home/ubuntu/.domino-defaults && echo "export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.6-src.zip" >> /home/ubuntu/.domino-defaults # Backup existing spark-defautls.conf file. # Change spark-defaults.conf directory permission as a new spark-defaults.conf file gets created by Domino's spark integration RUN mv /etc/spark2/conf/spark-defaults.conf /etc/spark2/ && chmod 777 /etc/spark2/2.6.5.0-292/0 USER ubuntu -
Scroll down to the Pre Run Script field and add the following lines.
cat /etc/spark2/spark-defaults.conf >> /etc/spark2/conf/spark-defaults.conf sed -i.bak '/spark.ui.port=0/d' /etc/spark2/conf/spark-defaults.conf -
Scroll down and click Advanced to expand additional fields. Add the following line to the Post Setup Script field.
echo "export YARN_CONF_DIR=/etc/hadoop/conf" >> /home/ubuntu/.bashrc -
Click Build when finished editing the Dockerfile instructions. If the build completes successfully, you are ready to try using the environment.
This procedure assumes that an environment with the necessary client software has been created according to the instructions above. Ask your Domino admin for access to such an environment.
-
Open the Domino project you want to use with your Hortonworks cluster, then click Settings from the project menu.
-
On the Integrations tab, click to select YARN integration from the Apache Spark panel, then click Save. You do not need to edit any of the fields in this section.
-
If your cluster uses Kerberos authentication, you can configure credentials at the user level or project level. Do so before attempting to use the environment. Note that if you followed the instructions above on creating your environment, your Kerberos configuration file has already been added to it.
-
On the Hardware & Environment tab, change the project default environment to the one with the cluster’s binaries and configurations files installed.
You are now ready to start Runs from this project that interact with your Hortonworks cluster.