Machine learning (ML) pipelines are crucial for streamlining the complex processes involved in building and deploying ML models. These pipelines not only enhance collaboration among data scientists, engineers, and IT professionals but also improve training efficiency and reduce costs. This article explores the significance of ML pipelines, their differences from CI/CD pipelines, and how tools like Kubeflow, Airflow, and Domino can be integrated to manage the complete data processing, model training, and deployment workflows.
While ML pipelines focus on the model development lifecycle, CI/CD pipelines are centered on software development and delivery processes. CI/CD pipelines automate the steps involved in integrating code changes from multiple contributors, testing them, and deploying stable versions to production. In contrast, ML pipelines manage the flow of data through various stages of processing, model training, and deployment within ML projects.
The core of an ML pipeline is to split a complete ML task into a multistep workflow. Each step is a manageable component that can be developed, optimized, configured, and automated individually. Steps are connected through well-defined interfaces.
This modular approach brings two key benefits:
-
Standardize the MLOps practice and support scalable team collaboration
Machine learning operations (MLOps) automate the process of building ML models and taking the model to production. This is a complex process that usually requires collaboration from different teams with different skills. A well-defined ML pipeline can abstract this complex process into a multistep workflow, mapping each step to a specific task such that each team can work independently.
For example, a typical ML project includes the steps of data collection, data preparation, model training, model evaluation, and model deployment. Data engineers usually concentrate on data steps, data scientists spend most of their time on model training and evaluation, and ML engineers focus on model deployment and automation of the entire workflow. By leveraging the ML pipeline, each team only needs to work on building their own steps. The best way to build steps is to use the Azure Machine Learning component (v2), a self-contained piece of code that does one step in an ML pipeline. All these steps, built by different users, are finally integrated into a single workflow through the pipeline definition.
The pipeline is a collaboration tool for everyone in the project. The process of defining a pipeline and all its steps can be standardized by each company’s preferred development operations (DevOps) practice. The pipeline can be further versioned and automated. If the ML projects are described as a pipeline, then the best MLOps practice is already applied.
-
Training efficiency and cost reduction
The ML pipeline not only puts MLOps into practice but also improves the training efficiency and reduces the cost of a large model. For example, modern natural language model training requires pre-processing large amounts of data and GPU-intensive transformer model training. It takes hours to days to train a model each time. When the model is being built, the data scientist wants to test different training codes or hyperparameters and run the training many times to get the best model performance. In most cases, there are small changes from one training iteration to another. It would be a significant waste to conduct the entire training process, from data processing to model training, each time. By using an ML pipeline, unchanged step results can be calculated and outputs from previous training iterations can be reused automatically.
Additionally, the ML pipeline supports running each step on different computation resources. For example, the memory-heavy data processing work can run on high-memory CPU machines, while the computation-intensive training can run on expensive GPU machines. By properly choosing which step to run on which type of machine, the training cost can be significantly reduced.
The starting point of building an ML pipeline might vary, depending on your team’s maturity and familiarity with ML. There are a few typical approaches to building a pipeline.
The first approach usually applies to teams that haven’t used pipelines before. In this situation, data scientists typically have developed some ML models on their local environment using their favorite tools. ML engineers need to take the data scientists' output into production. The work often involves cleaning up some unnecessary code from original notebooks or Python code, changing the training input from local data to parameterized values, splitting the training code into multiple steps as needed, performing a unit test of each step, and finally wrapping all steps into a pipeline.
The second approach applies to teams that have some familiarity with pipelines and have done the first approach a few times so that common patterns have begun to emerge. Once the teams get familiar with pipelines and want to do more ML projects using pipelines, they’ll find the first approach is hard to scale. To accelerate and scale adoption, they may have a centralized team set up a few pipeline templates, each trying to solve one specific ML problem. The template predefines the pipeline structure and includes the number of steps, each step’s inputs and outputs, and the connectivity of each. To start a new ML project, the team first forks one template repository. The team leader then assigns each member a specific step to work on. The data scientists and data engineers continue with their regular work and when they’re happy with their results, they structure their code to fit the predefined steps. Once the structured codes are checked in, the pipeline can be executed or automated. If any changes are necessary, each member only needs to work on their piece of code without touching the rest of the pipeline code.
Once a team has built a collection of ML pipelines and reusable components, they can start to build the ML pipeline by cloning previous pipelines or tying existing reusable components together. At this stage, the team’s overall productivity would have improved significantly.
You can seamlessly integrate Kubeflow and Airflow with Domino.
Use Kubeflow with Domino
Kubeflow is an open-source platform designed to orchestrate ML pipelines using Kubernetes. It is particularly well-suited for managing complex workflows in ML projects that involve large datasets and require scalable processing. Domino’s code-first approach aligns well with defining tasks within Kubeflow pipelines to initiate Jobs in Domino.
Architecturally, Kubeflow pipelines are defined, managed, and operated within a Kubernetes cluster, separate from your Domino Environment. Kubeflow will require network connectivity to access the Domino API for executing Jobs in your Domino Projects. The code for each step within the pipeline, such as data retrieval, cleaning, and model training, is stored and versioned in your Domino Project. This integration ensures collaboration between Kubeflow’s orchestration capabilities and Domino’s reproducibility features.
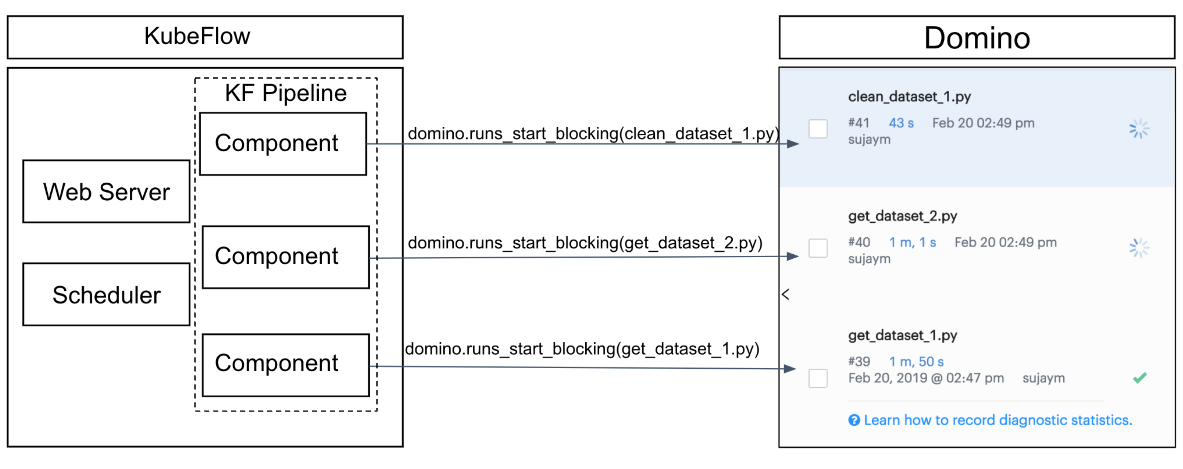
To learn more about using Kubeflow with Domino, see Orchestrate Jobs with Kubeflow.
Use Airflow with Domino
Apache Airflow is another powerful tool used to orchestrate complex computational workflows. Airflow’s scheduler executes tasks on an array of workers while following specified dependencies. The example graph below was developed using Airflow and python-domino and executes all the dependencies in Domino using the Airflow scheduler. It trains a model using multiple datasets and generates a final report.
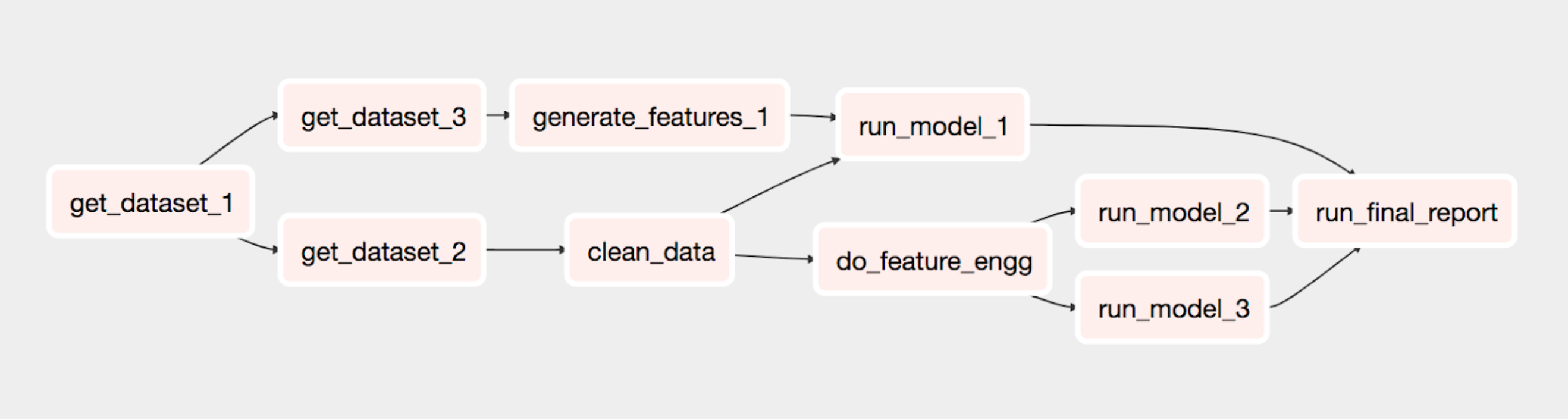
To learn more about using Airflow with Domino, see Orchestrate Jobs with Apache Airflow.