This quickstart guide covers an example flow for a feature store of File offline store type and SQLite online store type, using these steps:
-
Prerequisites to prepare the Git repository
-
Set up a feature store with the applicable infrastructure and data.
-
Create and publish an example feature view.
-
Train a model on historical features.
-
Materialize features into the online store.
-
Predict the best driver using the trained model and materialized online features.
-
Prepare an empty Git repository.
-
Create a
datafolder in the Git repository if it doesn’t exist. -
Download the
driver_stats.parquetfile and place it in thedatafolder.
-
Follow the instructions to set up a feature store using
Filetype offline store andSQLitetype online store.
-
Enable the feature store on your Project of choice.
-
In your Project Workspace, navigate to the file location found on the mounted feature store Git repository under File Changes > Imported Repositories.
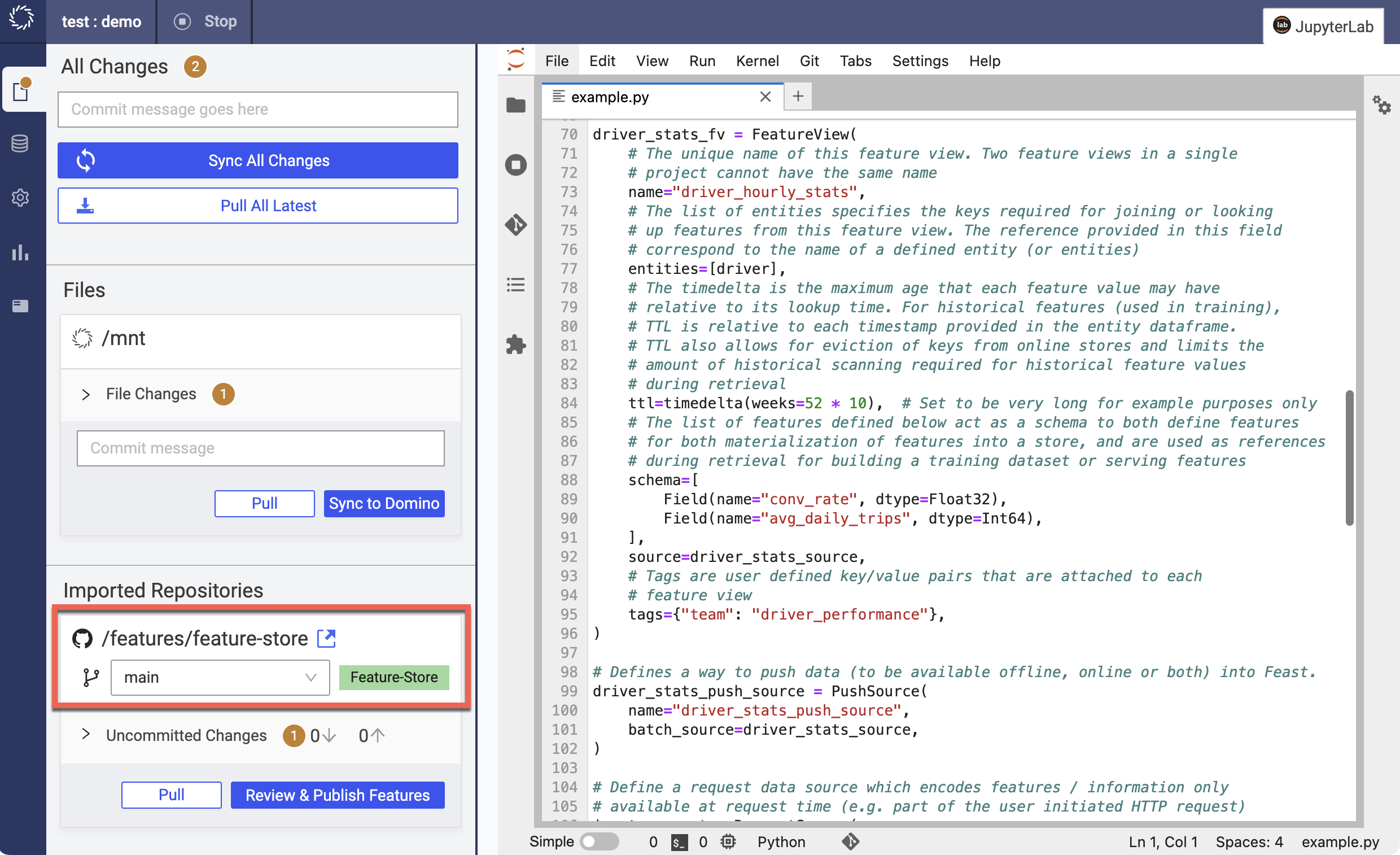
-
Upload the following Python file into the directory at the file location. This Python file defines the offline store and a feature view.
# This is an example feature definition file from datetime import timedelta from pathlib import Path from feast import ( Entity, FeatureView, Field, FileSource, ) from feast.types import Float32, Int64 current = Path.cwd() # Read data from parquet files. Parquet is convenient for local development mode. For # production, you can use your favorite DWH, such as BigQuery. See Feast documentation # for more info. driver_stats_source = FileSource( name="driver_hourly_stats_source", path=str(current / "data/driver_stats.parquet"), timestamp_field="event_timestamp", created_timestamp_column="created", ) # Define an entity for the driver. You can think of an entity as a primary key # used to fetch features. driver = Entity( name="driver", join_keys=["driver_id"], description="driver id", ) # Our parquet files contain sample data that includes a driver_id column, timestamps and # three feature column. Here we define a Feature View that will allow us to serve this # data to our model online. driver_stats_fv = FeatureView( # The unique name of this feature view. Two feature views in a single # project cannot have the same name name="driver_hourly_stats", entities=[driver], ttl=timedelta(days=1), # The list of features defined below act as a schema to both define features # for both materialization of features into a store, and are used as references # during retrieval for building a training dataset or serving features schema=[ Field(name="conv_rate", dtype=Float32), Field(name="acc_rate", dtype=Float32), Field(name="avg_daily_trips", dtype=Int64), ], online=True, source=driver_stats_source, # Tags are user defined key/value pairs that are attached to each # feature view tags={"team": "driver_performance"}, ) -
Publish your changes. When the Job finishes, you should see the created feature view in the global registry at Data > Feature Store.
-
Upload the following script as a Python file called
train.pyin the/mntdirectory. This script retrieves historical features from thedriver_statsdatabase file and uses them to train a model with linear regression.NoteThe /path/to/mounted/feature-storein the script needs to be replaced with the actual mount path of the feature store repository. In the Workspace or Job, the feature store repository mounted path is/features/<repo_name>.from datetime import datetime import feast import pandas as pd from joblib import dump from sklearn.linear_model import LinearRegression # Load driver order data entity_df = pd.DataFrame.from_dict( { "driver_id": [1001, 1002, 1003, 1004, 1001], "event_timestamp": [ datetime(2021, 4, 12, 10, 59, 42), datetime(2021, 4, 12, 8, 12, 10), datetime(2021, 4, 12, 16, 40, 26), datetime(2021, 4, 12, 15, 1, 12), datetime.now() ], "trip_completed": [1, 0, 1, 0, 1] } ) # Connect to your feature store provider fs = feast.FeatureStore(repo_path="/path/to/mounted/feature-store") # replace with actual mount path # Retrieve training data from parquet database file training_df = fs.get_historical_features( entity_df=entity_df, features=[ "driver_hourly_stats:conv_rate", "driver_hourly_stats:acc_rate", "driver_hourly_stats:avg_daily_trips", ], ).to_df() print("----- Feature schema ----- ") print(training_df.info()) print() print("----- Example features ----- ") print(training_df.head()) # Train model target = "trip_completed" reg = LinearRegression() train_X = training_df[training_df.columns.drop(target).drop("event_timestamp")] train_Y = training_df.loc[:, target] reg.fit(train_X[sorted(train_X)], train_Y) # Save model dump(reg, "driver_model.bin")The last line saves the model into
mnt/driver_model.bin. -
After uploading the file, sync your file changes to Domino by going to File Changes > Files and clicking Sync to Domino.
-
Run the script by navigating to the Jobs page and creating a Job for
mnt/train.py. After the Job finishes, themnt/driver_model.binshould show up in the/mntdirectory.
Materializing features moves features from a specific time range into the online store for low-latency serving. This is used for getting near real-time features for model inference work. For example, if you want to use driver data from the last two weeks for prediction, you would use the time period from 2 weeks ago to the current time in your materialize script.
-
Upload the following script into the
/mntdirectory asmaterialize.sh. Replace[feature-store/path/location]with the file mount path of your feature store repository. This script serializes the latest values of features since the beginning of time to prepare for serving.#!/bin/bash set -x echo "Starting materializing" cd [feature-store/path/location] #replace with actual mount path CURRENT_TIME=$(date -u +"%Y-%m-%dT%H:%M:%S") feast materialize 2020-09-15T19:20:01 $CURRENT_TIME git add data/online.db git add data/registry.db git commit -m "Feast materialize to $CURRENT_TIME" git push #feast materialize-incremental $CURRENT_TIME echo "Finished materializing" -
Sync the added file to Domino by visiting File Changes > Files and clicking Sync to Domino.
-
Run the script by navigating to the Jobs page and creating a Job with the
/mnt/materialize.shscript.
-
Upload the following script as a Python file
predict.pyin themntdirectory.NoteThe /path/to/mounted/feature-storein the script needs to be replaced with the actual mount path of the feature store repository. In the ModelAPI, the feature store repository mounted path is/repos/<repo_name>.import feast import pandas as pd from joblib import load class DriverRankingModel: def __init__(self): # Load model self.model = load("driver_model.bin") # If run from workspace or job, the mounted repo path is "/features/<repo_name>" # If run from ModelAPI, the mounted repo path is "/repos/<repo_name>" self.fs = feast.FeatureStore(repo_path="/path/to/mounted/feature-store") # replace with actual mount path def predict(self, driver_ids): # Read features from Feast driver_features = self.fs.get_online_features( entity_rows=[{"driver_id": driver_id} for driver_id in driver_ids], features=[ "driver_hourly_stats:conv_rate", "driver_hourly_stats:acc_rate", "driver_hourly_stats:avg_daily_trips", ], ) df = pd.DataFrame.from_dict(driver_features.to_dict()) # Make prediction df["prediction"] = self.model.predict(df[sorted(df)]) # Choose best driver best_driver_id = df["driver_id"].iloc[df["prediction"].argmax()] # return best driver return best_driver_id def predict(drivers): print("-------") print(f"drivers: {drivers}") print("-------") model = DriverRankingModel() best_driver = model.predict(drivers) print("-------") print(f"best driver: {best_driver}") print("-------") return dict(driver=str(best_driver)) if __name__ == "__main__": drivers = [1001, 1002, 1003, 1004] model = DriverRankingModel() best_driver = model.predict(drivers) print(best_driver)The script selects the best driver based on the selected features.
-
Sync the added file to Domino by visiting File Changes > Files and clicking Sync to Domino.
-
Run the script as a Model API by navigating to the Model APIs page and creating a model API with the
/mnt/predict.pyscript andpredictfunction. -
Input the below JSON block as the request. The model returns the best driver from the inputted IDs.
{
"data": {
"drivers": [
1001,
1002,
1003,
1004
]
}
}-
Discover and reuse features that are available in the Domino feature store.
-
Learn how to define and publish features.