Automatically generate professional ML model documentation from code and Experiment Manager artifacts.
Auto Model Documentation is an LLM-powered tool that automatically generates professional documentation for machine learning models. It analyzes your ML codebase, extracts information from MLflow artifacts, and produces comprehensive Word documents and Jupyter notebooks describing your models, features, training pipelines, and performance metrics.
Key Capabilities
| Feature | Description |
|---|---|
Code Analysis | Scans Python source files to understand model architecture, feature engineering, and training logic |
Experiment Manager Integration | Extracts metrics, parameters, and artifacts from registered models and experiments |
LLM-Powered Generation | Uses Claude or GPT-4 to create natural language documentation from technical artifacts |
Word Document Output | Generates professional .docx files with tables, charts, and formatted sections |
Jupyter Notebook Output | Creates editable notebooks for further customization and sharing |
Installation
Install the package and its dependencies:
# Clone or download the repository
cd auto_model_docs
# Install in development mode
pip install -e .
# Or install dependencies directly
pip install -r requirements.txtThe package requires the following core dependencies:
| Package | Purpose |
|---|---|
anthropic | Anthropic Claude API client |
openai | OpenAI GPT API client |
mlflow | MLflow tracking and model registry access |
python-docx | Word document generation |
matplotlib | Chart and visualization generation |
pyyaml | YAML spec file parsing |
rich | Terminal progress display |
Environment Setup
Set up your API keys and MLflow configuration. Create a .env file in the project root or set environment variables:
# LLM API Keys (set one or both)
ANTHROPIC_API_KEY=your-anthropic-api-key
OPENAI_API_KEY=your-openai-api-key
# Optional: Custom OpenAI-compatible endpoint
OPENAI_BASE_URL=https://api.example.com/v1
# MLflow Configuration (optional)
MLFLOW_TRACKING_URI=https://your-mlflow-server.com|
Tip
| In Domino environments, the MLflow tracking URI is automatically configured. You can also pass API keys directly via the CLI or Web UI. |
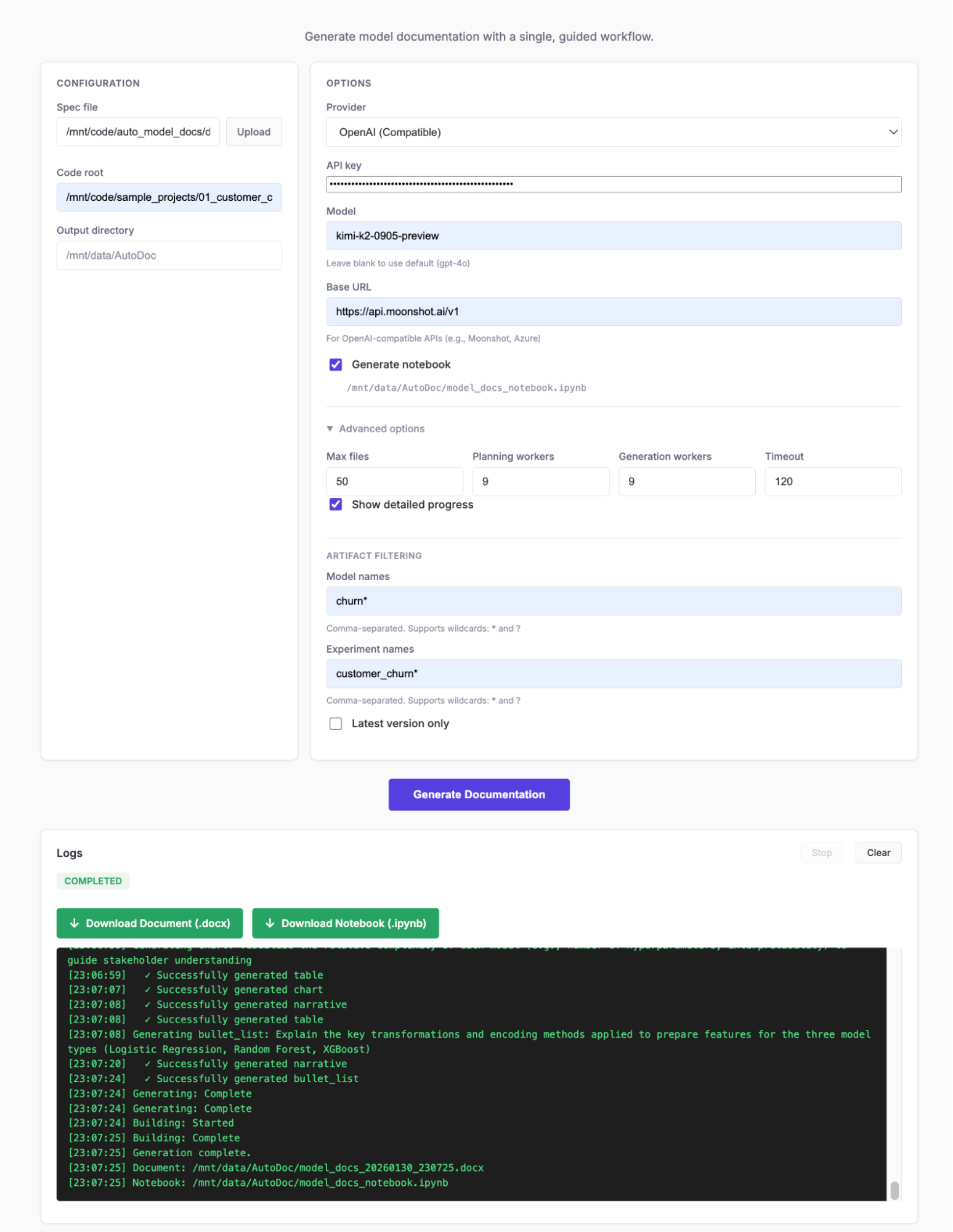
The Web UI provides an intuitive interface for configuring and running documentation generation jobs.
Accessing the Web Interface
Start the web application:
python web_app.pyThe application launches on http://localhost:8000 by default. In Domino, the app is accessible through the app deployments URL.
Configuration Panel
The configuration panel contains the essential settings for document generation.
| Field | Description |
|---|---|
Spec File | Path to the YAML document specification file. Defaults to |
Upload Spec | Alternatively, upload a spec file directly from your computer. |
Code Root | Root directory of the ML codebase to analyze. Defaults to |
Output Directory | Where to save generated documents. Defaults to |
Options Panel
Configure the LLM provider and model settings.
| Field | Description |
|---|---|
Provider | Select |
API Key | Your API key for the selected provider. Can also be set via environment variable. |
Model | Model name override. If blank, uses |
Base URL | Custom API endpoint for OpenAI-compatible services (e.g., Azure OpenAI, local models). |
Advanced Options
Fine-tune the generation process with advanced settings.
| Field | Description | Default |
|---|---|---|
Generation Workers | Number of parallel workers for content generation. Higher values speed up generation but increase API costs. | 4 |
Planning Workers | Number of parallel workers for section planning. | 4 |
Max Files | Maximum number of source files to scan from the codebase. | 50 |
Timeout | Timeout for individual LLM API calls in seconds. | 120 |
Generate Notebook | Also create an editable Jupyter notebook alongside the Word document. | Off |
Notebook Path | Custom path for the generated notebook. |
|
Verbose | Enable detailed logging to show progress of each pipeline step. | Off |
Artifact Filtering
Control which MLflow models and experiments are included in the documentation.
| Field | Description |
|---|---|
Model Names | Comma-separated list of model names to include. Supports wildcards: |
Experiment Names | Comma-separated list of experiment names to include. Supports wildcards. Example: |
Latest Only | When checked, only includes the latest version of each model, ignoring older versions. |
|
Tip
|
Use wildcards to match multiple models. For example, prod_* matches all models starting with "prod_".
|
Running a Job
-
Configure your settings in the form panels
-
Click Generate Documentation to start the job
-
Monitor progress in the Logs panel
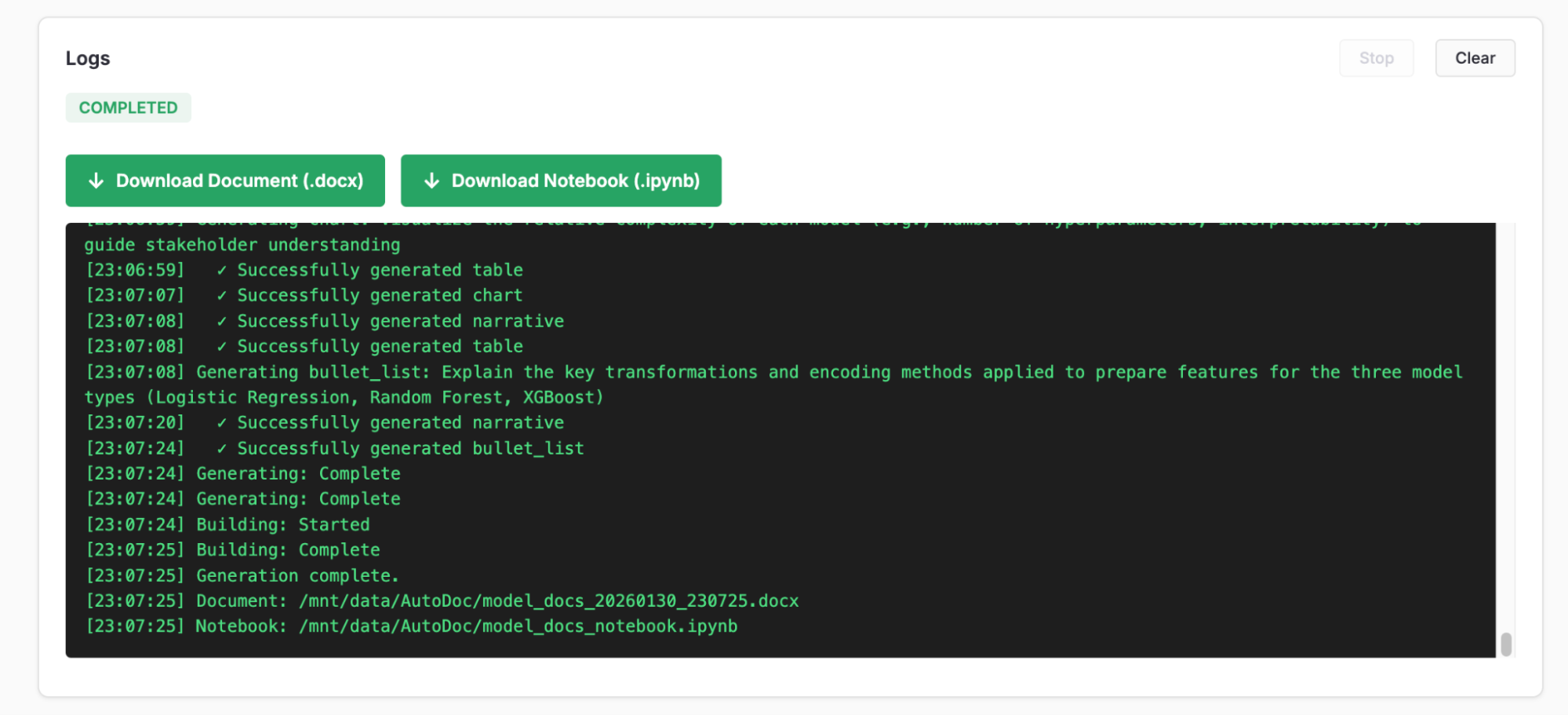
The progress display shows four phases:
-
Scanning: Analyzing code and extracting MLflow artifacts
-
Planning: LLM planning content blocks for each section
-
Generating: Creating narratives, tables, and charts
-
Building: Assembling the final Word document
Once complete, download links appear for the generated files:
|
Tip
| Click Stop to cancel a running job. The application will clean up any partial artifacts. |
The command-line interface provides full control over documentation generation for automation and scripting.
Key Arguments
| Argument | Short | Description |
|---|---|---|
|
| Required. Path to YAML document specification file. |
|
| Output directory for generated documents. |
|
| Root directory of codebase to analyze. |
|
| LLM provider: |
|
| Model name override (uses provider default if not set). |
|
| Enable verbose output with detailed progress. |
| Also generate an editable Jupyter notebook. | |
| Custom path for the generated notebook. | |
| Regenerate notebook from cached results (skips full pipeline). |
Filtering Options
Filter which MLflow models and experiments are documented:
| Argument | Description |
|---|---|
| Comma-separated list of experiment names/patterns. Supports wildcards. |
| Comma-separated list of model names/patterns. Supports wildcards. |
| Only include the latest version of each model. |
| Disable automatic Domino project filtering (scan all projects). |
Advanced Options
| Argument | Description | Default |
|---|---|---|
| Number of parallel content generation workers. | 4 |
| Number of parallel section planning workers. | 4 |
| Maximum number of source files to scan. | 50 |
| Timeout for individual LLM API calls (seconds). | 120 |
| Maximum retries for failed LLM requests. | 3 |
| Initial backoff delay for retries (seconds). | 3.0 |
| Maximum backoff delay (seconds). | 30.0 |
| Random jitter factor for backoff (0.0-1.0). | 0.2 |
Example Commands
Basic generation with Anthropic Claude:
python main.py --spec doc_spec.yaml --provider anthropicGenerate with verbose output and notebook:
python main.py --spec doc_spec.yaml \
--provider openai \
--notebook \
--verboseFilter to specific models and experiments:
python main.py --spec doc_spec.yaml \
--provider anthropic \
--models "churn_model*,fraud_detector" \
--experiments "production_*" \
--latest-onlyCustom paths and parallel workers:
python main.py --spec custom_spec.yaml \
--code-root /path/to/ml/project \
--output /path/to/output \
--generation-workers 8 \
--planning-workers 4 \
--max-files 100Regenerate notebook from cached results:
python main.py --spec doc_spec.yaml \
--notebook-from-cache \
--notebook-path ./updated_notebook.ipynbThe document specification file defines the structure and content of the generated documentation.
Spec File Structure
A spec file contains three main components:
# Document metadata
title: "Machine Learning Model Documentation"
authors: "Data Science Team"
# Sections to include
sections:
- Executive Summary
- Data Overview
- Model Architecture
- Model Performance
- Conclusion
# Optional hints for content guidance
hints:
"Executive Summary": >
Focus on business impact and key metrics.Section Configuration
The sections list defines which sections appear in the document and their order:
sections:
- Executive Summary
- Data Overview
- Feature Engineering
- Model Architecture
- Training Pipeline
- Model Performance
- Validation Results
- Deployment Considerations
- Conclusion
- AppendixEach section name becomes a heading in the generated document. The LLM generates appropriate content based on the section name and any hints provided.
Per-Model Sections
For multi-model documentation, use the per_model modifier to create separate subsections for each registered model:
sections:
- Executive Summary
- Data Overview
- "Model Performance: per_model" # Creates subsection for each model
- ConclusionThis generates sections like:
-
5. Model Performance
-
5.1 Model Performance: churn_predictor
-
5.2 Model Performance: fraud_detector
Hints for Guiding Content
Use hints to guide the LLM on what content to emphasize for each section:
hints:
"Executive Summary": >
Focus on business impact, key metrics, and high-level model capabilities.
Keep it suitable for non-technical stakeholders.
"Data Overview": >
Describe data sources, volume, quality considerations, and any data
preprocessing steps applied before feature engineering.
"Model Performance": >
Present key metrics (accuracy, AUC, F1, etc.), confusion matrix
insights, and performance analysis across different segments.
"Validation Results": >
Document the validation approach based on what is found in the code.
Do not describe validation methods that were not actually implemented.
"Conclusion": >
Summarize key model capabilities and performance highlights.
Do not introduce new technical details - synthesize what was covered.|
Tip
| Be specific in hints about what to include or exclude. The LLM will follow these guidelines when generating content. |
Example Spec File
Complete example specification:
# Document Specification for Auto Model Documentation
title: "Machine Learning Model Documentation"
authors: "Data Science Team"
sections:
- Executive Summary
- Data Overview
- Feature Engineering
- Model Architecture
- Training Pipeline
- "Model Performance: per_model"
- Validation Results
- Deployment Considerations
- Conclusion
- Appendix
hints:
"Executive Summary": >
Focus on business impact, key metrics, and high-level model capabilities.
Keep it suitable for non-technical stakeholders.
"Data Overview": >
Describe data sources, volume, quality considerations, and any data
preprocessing steps applied before feature engineering.
"Feature Engineering": >
Document feature transformations, encoding methods, scaling approaches,
and feature selection rationale.
"Model Architecture": >
Include model type, hyperparameters, training configuration,
and architectural decisions.
"Model Performance": >
Present key metrics (accuracy, AUC, F1, etc.), confusion matrix
insights, and performance analysis across different segments.
"Validation Results": >
Document the validation approach used based on what is found in the code.
If cross-validation was implemented, cover those results.
If only holdout/test set validation was used, document that approach.
"Deployment Considerations": >
Address inference latency, resource requirements, monitoring strategy,
and model refresh cadence.
"Conclusion": >
Summarize the key model capabilities and performance highlights.
Describe recommended monitoring approach based on the model type.Auto Model Documentation executes a 4-phase pipeline to generate documentation.

Scanning Phase
The scanning phase extracts information from two sources in parallel:
Code Scanner:
-
Scans Python files in the code root directory
-
Extracts function definitions, class structures, and docstrings
-
Identifies ML-related patterns (model training, feature engineering)
-
Respects
max_fileslimit to control scope
Artifact Scanner:
-
Connects to MLflow tracking server
-
Queries registered models and experiment runs
-
Extracts metrics, parameters, tags, and artifact metadata
-
Applies model/experiment filters if specified
Planning Phase
The planning phase uses the LLM to create a content plan for each section:
-
Analyzes the scanned context (code + artifacts)
-
Determines what content blocks are needed for each section
-
Plans narratives, tables, charts, and other elements
-
Considers hints from the spec file
-
Runs in parallel with configurable worker count
Generation Phase
The generation phase creates actual content for each planned block:
-
Narratives: Natural language descriptions and explanations
-
Tables: Structured data like metrics, parameters, feature lists
-
Charts: Visualizations of metrics, performance trends, distributions
-
Processes blocks in parallel for efficiency
Word Document (.docx)
The primary output is a professionally formatted Word document:
| Feature | Description |
|---|---|
Structured Sections | Hierarchical headings matching the spec file structure |
Formatted Tables | Metrics, parameters, and data presented in clean tables |
Embedded Charts | Matplotlib visualizations inserted as images |
Consistent Styling | Professional typography and layout |
Editable | Open in Microsoft Word or Google Docs for further editing |
Default location: <output_dir>/model_documentation.docx
Jupyter Notebook (.ipynb)
When --notebook is enabled, generates an editable notebook:
| Feature | Description |
|---|---|
Markdown Cells | Section content as editable markdown |
Code Cells | Executable code for reproducing charts and tables |
Interactive | Run and modify in Jupyter Lab or VS Code |
Shareable | Export to HTML, PDF, or other formats |
Default location: <output_dir>/model_docs_notebook.ipynb
Cache File
A JSON cache file stores generation results:
| Feature | Description |
|---|---|
Fast Regeneration | Rebuild notebook without re-running the full pipeline |
Preserves Content | All generated text, tables, and chart data |
Use with | Skip scanning, planning, and generation phases |
Location: <output_dir>/.autodoc_cache.json
Environment Variables
All settings can be configured via environment variables with or without the AUTODOC_ prefix:
| Variable | Description | Default |
|---|---|---|
| Anthropic Claude API key | - |
| OpenAI GPT API key | - |
| Custom OpenAI-compatible endpoint | - |
| MLflow tracking server URI | - |
| Root directory of codebase |
|
| Output directory |
|
| Maximum files to scan | 50 |
| Content generation workers | 1 |
| Section planning workers | 1 |
LLM Provider Settings
| Variable | Description | Default |
|---|---|---|
| Provider: |
|
| Model name override | Provider default |
| Max retries for requests | 3 |
| Initial retry backoff (seconds) | 3.0 |
| Maximum retry backoff (seconds) | 30.0 |
| Jitter factor (0.0-1.0) | 0.2 |
Default models by provider:
| Provider | Default Model |
|---|---|
Anthropic |
|
OpenAI |
|
Parallelization Settings
Control parallel execution to balance speed and API costs:
| Setting | Recommended Value | Notes |
|---|---|---|
Generation Workers | 4-8 | Higher values speed up generation |
Planning Workers | 4 | Planning is typically faster than generation |
Max Files | 50-100 | Increase for larger codebases |
|
Tip
| Start with lower worker counts and increase if you have API rate limit headroom. |
Tips for Better Documentation
-
Write descriptive docstrings in your ML code. The scanner extracts these for context.
-
Use meaningful MLflow experiment and model names. These appear in the generated documentation.
-
Log comprehensive metrics to MLflow. The more metrics available, the richer the documentation.
-
Organize code logically. Separate feature engineering, model training, and evaluation into distinct modules.
-
Use clear function and variable names. The LLM uses these to understand code intent.
Recommended YAML Spec Patterns
-
Start broad, then specific:
sections: - Executive Summary # High-level overview - Technical Deep Dive # Detailed technical content - Appendix # Supporting details -
Use per_model for multi-model projects:
sections: - "Model Performance: per_model" - "Deployment Guide: per_model" -
Provide detailed hints for critical sections:
hints: "Executive Summary": > This section is for executive stakeholders. Focus on business value and ROI. Avoid technical jargon.
Performance Optimization
-
Limit file scanning for large codebases:
--max-files 30 -
Use model filtering to focus on specific models:
--models "production_*" --latest-only -
Increase workers if you have API rate limit headroom:
--generation-workers 8 --planning-workers 4 -
Use notebook caching for iterative refinement to the notebook generation without calling the LLM during development:
# First run: full generation python main.py --spec doc_spec.yaml --notebook # Subsequent runs: fast notebook rebuild python main.py --spec doc_spec.yaml --notebook-from-cache -
Enable verbose mode for debugging:
python main.py --spec doc_spec.yaml --verbose
For additional help or to report issues, refer to the project repository or contact your support team.