Develop and publish a large language model (LLM)-based chatbot on Domino with the Streamlit framework. Learn how to quickly create a Domino-hosted app that takes user input to call generative artificial intelligence (AI) APIs from Hugging Face and your own Domino Domino endpoint.
For more generative AI LLM sample projects, see Domino LLM Reference Projects.
To complete this how-to you must fulfill the following prerequisites.
Hugging Face API key
Get a Hugging Face API key to access models hosted on Hugging Face.
-
Create your account on Hugging Face.
-
Create a new Domino user level environment variable called
HUGGING_FACE_API_TOKENand add your API key as its value.
Jupyter server proxy
Create a compute environment in Domino with Jupyter or Jupyterlab and jupyter server proxy. If you use a Domino Standard Environment, then Jupyter, Jupyterlab, and jupyter server proxy are already installed for you.
Domino endpoint
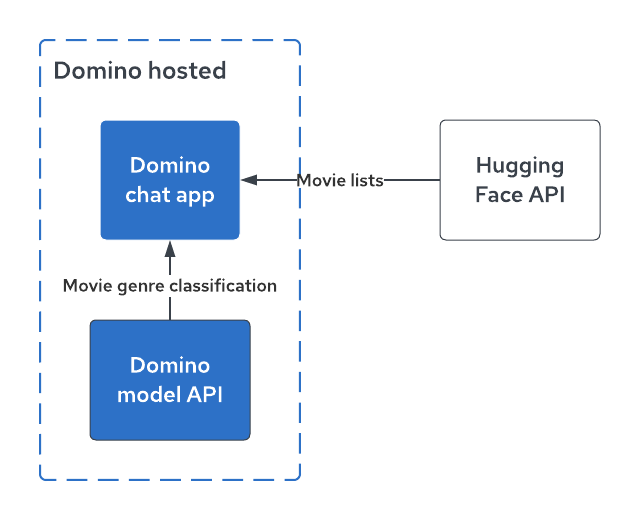
The app uses both a Hugging Face Domino endpoint and a Domino Domino endpoint to demonstrate how to access multiple models from a single app.
To host the model used in this how-to, follow the instructions in the Domino Streamlit app repository.
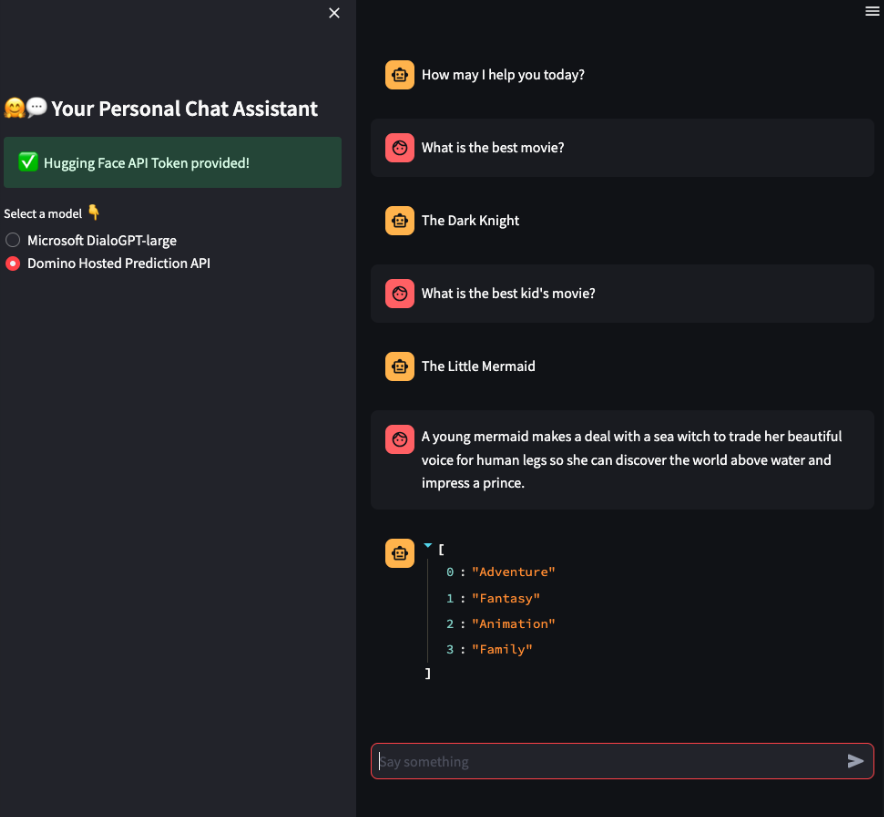
You will create an app frontend using Streamlit chat elements to interact with two different models and get answers to movie-based questions.
The app uses a model from the Hugging Face LLM Models repo to generate lists of movies, and another model deployed as a Domino endpoint to classify movie summaries by genre.
Create a simple chat app that has the following elements:
-
Title.
-
Sidebar with the following:
-
A password field to add a Hugging Face API key.
-
A radio button to select between the two models.
-
-
A body with the chat interface.
You can interactively develop your Streamlit app in a Domino Workspace and see your changes live via an app URL.
Create the app title and sidebar
-
Launch a new Jupyter or Jupyterlab workspace in Domino. Make sure the jupyter server proxy package is installed.
-
Create a new file in your
/mntdirectory calledchatbot.py -
Add the following code to add a title and sidebar.
import streamlit as st import os import json import requests import pandas as pd API_TOKEN = os.environ['HUGGING_FACE_API_TOKEN'] API_URL = "https://api-inference.huggingface.co/models/microsoft/DialoGPT-large" headers = {"Authorization": f"Bearer {API_TOKEN}"} # App title st.set_page_config(page_title="🤖💬 Your Personal Chat Assistant") # App sidebar with st.sidebar: st.title('🤖💬 Your Personal Chat Assistant') if API_TOKEN == "": API_TOKEN = st.text_input('Enter Hugging Face API Token:', type='password') if not (API_TOKEN): st.warning('Please enter your Hugging Face API Token', icon='⚠️') else: st.success('Proceed to entering your prompt message!', icon='👉') else: st.success('Hugging Face API Token provided!', icon='✅') model = st.radio( "Select a model :point_down:", ('Microsoft DialoGPT-large', 'Your Domino Hosted Prediction API')) -
Open a new terminal window in your IDE and run the following code.
echo -e "import os print('https://your-domino-url/{}/{}/notebookSession/{}/proxy/8501/'.format(os.environ['DOMINO_PROJECT_OWNER'], os.environ['DOMINO_PROJECT_NAME'], os.environ['DOMINO_RUN_ID']))" | python3 -
Replace
your-domino-urlwith your Domino domain. This is the app URL you’ll use to access the app in a new browser tab once it is deployed from within the workspace.Note the use of
8501in the URL. This is the default port at which Streamlit deploys an app. -
Type
streamlit run chatbot.pyin the terminal. You should see your app being published by Streamlit and running on the default8501port. -
View your app in a new browser tab using the app URL.
Capture user inputs
Next, let’s use Streamlit session state to capture new user inputs.
-
Add the following code to
chatbot.py.# Seek new input prompts from user if prompt := st.chat_input("Say something"): st.session_state.messages.append({"role": "user", "content": prompt}) with st.chat_message("user"): st.write(prompt) -
Store the bot and user’s conversation, and view the updated app.
# Store LLM generated responses if "messages" not in st.session_state.keys(): st.session_state.messages = [{"role": "assistant", "content": "How may I help you today?"}] # And display all stored chat messages for message in st.session_state.messages: with st.chat_message(message["role"]): st.write(message["content"]) -
View the updated app in the app URL to see the changes.
Call the Hugging Face API and Domino endpoint
-
Write a function to call the Microsoft/DialoGPT-large model hosted on Hugging Face via an API call.
# Query the microsoft DialoGPT def query_DialoGPT_model(prompt_input, past_user_inputs = None, generated_responses = None): payload = { "inputs": { "past_user_inputs": past_user_inputs, "generated_responses": generated_responses, "text": prompt_input, }, } data = json.dumps(payload) response = requests.request("POST", API_URL, headers=headers, data=data) response = json.loads(response.content.decode("utf-8")) response.pop("warnings") return response.get('generated_text') -
Create a new function that invokes the second model hosted as a Domino endpoint in your Domino deployment.
# Query your own internal Domino endpoint def query_domino_endpoint(prompt_input): response = requests.post("https://{your-domino-url}:443/models/{model-id}/latest/model", auth=( "{domino-endpoint-access-token-here}", "{domino-endpoint-access-token-here}" ), json={ "data": { "{model-parameter-1}": prompt_input } } ) return response.json().get('result')[0] -
Create a function that invokes the Hugging Face LLM model or Domino endpoint hosted in Domino based on the radio button selection in the sidebar.
# Function for generating LLM response def generate_response(prompt): if model == "Microsoft DialoGPT-large": response_generated = query_DialoGPT_model(prompt) elif model == "Your Domino Hosted Prediction API": response_generated = query_domino_endpoint(prompt) return response_generated # Generate a new response if last message is not from assistant if st.session_state.messages[-1]["role"] != "assistant": with st.chat_message("assistant"): with st.spinner("Thinking..."): response = generate_response(prompt) st.write(response) message = {"role": "assistant", "content": response} st.session_state.messages.append(message)
Putting it all together, your app code should look like the following:
import streamlit as st
import os
import json
import requests
import pandas as pd
API_TOKEN = os.environ['HUGGING_FACE_API_TOKEN']
API_URL = "https://api-inference.huggingface.co/models/microsoft/DialoGPT-large"
headers = {"Authorization": f"Bearer {API_TOKEN}"}
# App title
st.set_page_config(page_title="🤖💬 Your Personal Chat Assistant")
# App sidebar
with st.sidebar:
st.title('🤖💬 Your Personal Chat Assistant')
if API_TOKEN == "":
API_TOKEN = st.text_input('Enter Hugging Face API Token:', type='password')
if not (API_TOKEN):
st.warning('Please enter your Hugging Face API Token', icon='⚠️')
else:
st.success('Proceed to entering your prompt message!', icon='👉')
else:
st.success('Hugging Face API Token provided!', icon='✅')
model = st.radio(
"Select a model :point_down:",
('Microsoft DialoGPT-large', 'Your Domino Hosted Prediction API'))
# Store LLM generated responses
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": "How may I help you today?"}]
# And display all stored chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
# Seek new input prompts from user
if prompt := st.chat_input("Say something"):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# Query the Microsoft DialoGPT
def query_DialoGPT_model(prompt_input, past_user_inputs = None, generated_responses = None):
payload = {
"inputs": {
"past_user_inputs": past_user_inputs,
"generated_responses": generated_responses,
"text": prompt_input,
},
}
data = json.dumps(payload)
response = requests.request("POST", API_URL, headers=headers, data=data)
response = json.loads(response.content.decode("utf-8"))
response.pop("warnings")
return response.get('generated_text')
# Query your own internal Domino endpoint
def query_domino_endpoint(prompt_input):
response = requests.post("https://{your-domino-url}:443/models/{model-id}/latest/model",
auth=(
"{domino-endpoint-access-token-here}",
"{domino-endpoint-access-token-here}"
),
json={
"data": {
"{model-parameter-1}": prompt_input
}
}
)
return response.json().get('result')[0]
# Function for generating LLM response
def generate_response(prompt):
if model == "Microsoft DialoGPT-large":
response_generated = query_DialoGPT_model(prompt)
elif model == "Your Domino Hosted Prediction API":
response_generated = query_domino_endpoint(prompt)
return response_generated
# Generate a new response if last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = generate_response(prompt)
st.write(response)
message = {"role": "assistant", "content": response}
st.session_state.messages.append(message)Finally, lets view the app again and make sure all the parts are working as expected. Converse with both models and observe the output. If all looks good, sync all changes to your project and stop your workspace.
Use Domino’s publish app feature to publish the chatbot app. Before we do so, we need to create an app.sh file. Recall that Domino requires the app to be hosted with hostname 0.0.0.0 and port 8888. Streamlit, by default, publishes an app at port 8501 but provides us with the option to set the host and port in its config.toml file.
-
Create an
app.shfile and add the content below to the file:mkdir ~/.streamlit echo "[browser]" > ~/.streamlit/config.toml echo "gatherUsageStats = true" >> ~/.streamlit/config.toml echo "serverAddress = \"0.0.0.0\"" >> ~/.streamlit/config.toml echo "serverPort = 8888" >> ~/.streamlit/config.toml echo "[server]" >> ~/.streamlit/config.toml echo "port = 8888" >> ~/.streamlit/config.toml echo "enableCORS = false" >> ~/.streamlit/config.toml echo "enableXsrfProtection = false" >> ~/.streamlit/config.toml streamlit run chatbot.py -
Click Deployments > App from the project sidebar.
-
Give your app an informative title and description, and set permissions to Anyone can access. This allows anyone with a network connection to your Domino deployment to access the app if they have the URL.
TipSelect Make globally discoverable to make your app easily discoverable. You can always change this later. -
Click Publish Domino App.
-
After the app status says "Running", click View App to load your app.
Now, you can set the permissions on your app to Anyone can access to share it with colleagues who have access to your Domino instance. You can try this out yourself by opening a private or incognito browser, or logging out of Domino, and navigating to the Deployments > App > Copy App Link.
To browse more apps, click Deploy > Apps in the top navigation menu.
For more generative AI LLM sample projects, see Domino LLM Reference Projects.