After you have developed your model and deemed it good enough to be useful, you will want to deploy it. There is no single deployment method that is best for all models. Therefore, Domino offers four different deployment options. One may fit your needs better than the others depending on your use case.
The available deployment methods are:
-
Scheduled reports
-
Launchers
-
Web applications
-
Model APIs
The remaining sections of this tutorial are not dependent on each other. For example, you will not need to complete the Scheduled report section to understand and complete the Web application section.
In our previous section, Step 5, we installed the Prophet package in Rstudio in order to train the model. In Domino, any package installed in one work session will not persist to another. In order to avoid having to re-install Prophet each time we need it, you can add it to a custom compute environment.
-
Create a new compute environment.
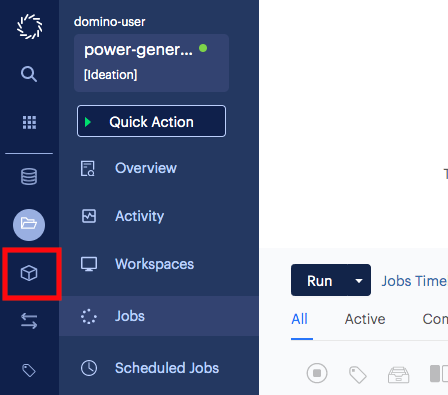
-
Go to the Environments page in Domino.
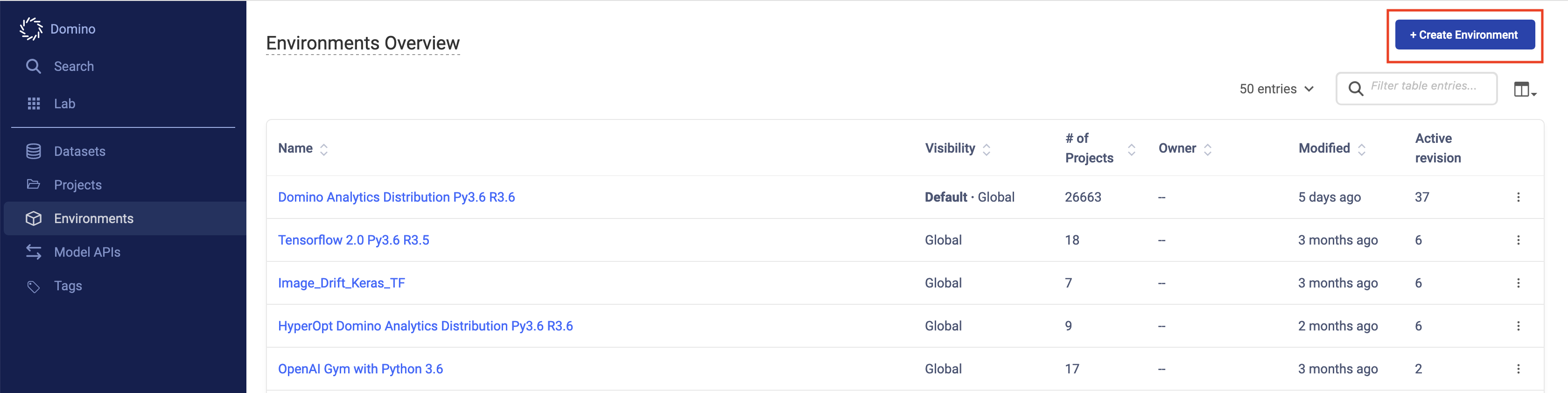
-
Click Create Environment.
-
Name the environment and enter a description for the new environment.
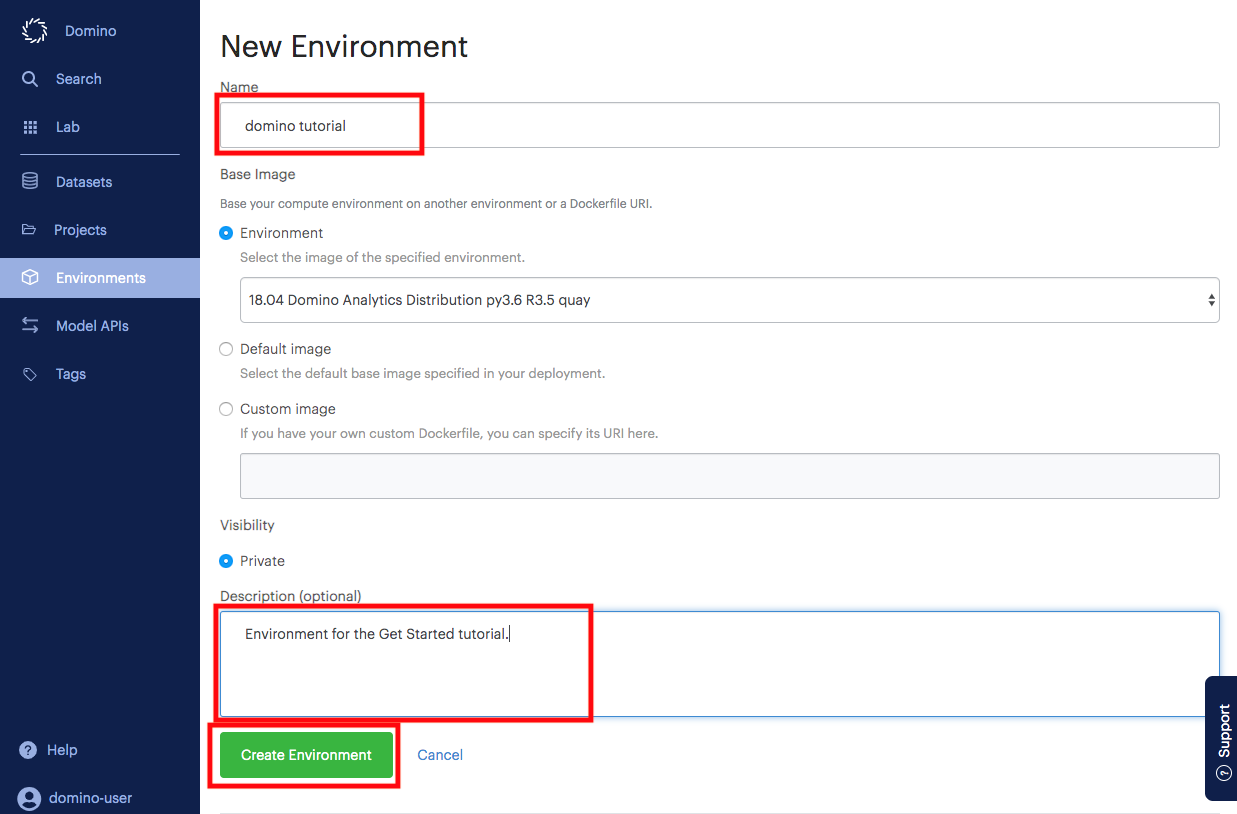
-
Click Create Environment.
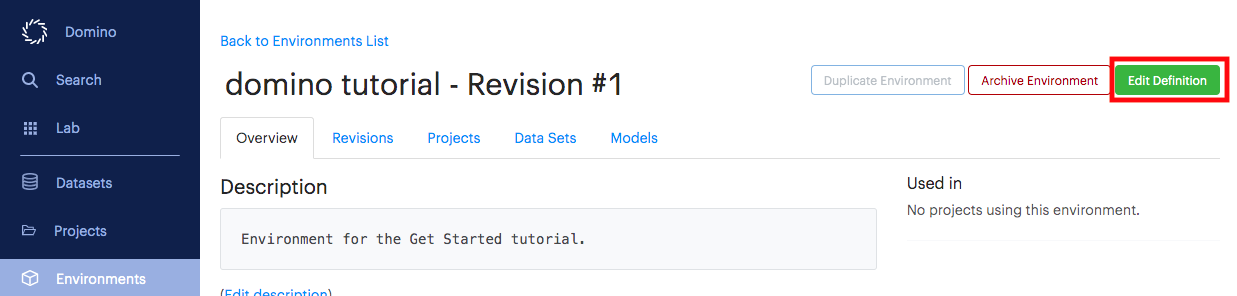
-
Click Edit Definition.
-
In the Dockerfile Instructions section, enter the following:
RUN R --no-save -e "install.packages(c('prophet'))"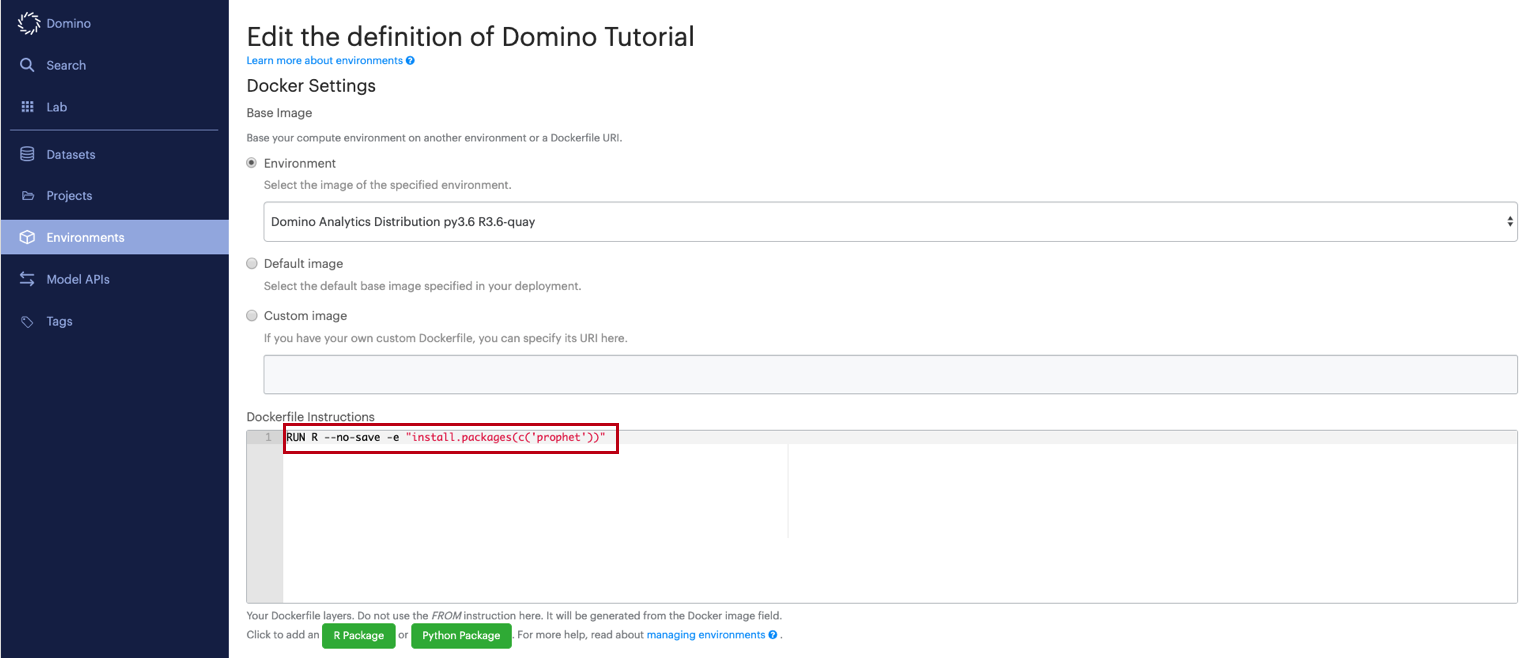
-
Scroll to the bottom of the page and click Build.
This will start the creation of your new compute environment. These added packages will now be permanently installed into your environment and be ready whenever you start a job or workspace session with this environment selected.
-
Go back to your project page and go to the Settings page.
-
Select your newly created environment from the Compute Environments menu.
-
If you want to learn more about how to customize your environment, see the Environments tutorials. You can also learn more about what’s included in our default environment, the Domino Standard Environment.
The Scheduled Jobs feature in Domino allows you to run a script on a regular basis. In Domino, using the R package knitr, you can blend text, code, and plots in an RMarkdown to create attractive HTML or pdf reports automatically.
In our case, we can imagine that each day we receive new data on power usage and want to email out a visualization of the latest data daily.
-
Start a new Rstudio session.
-
Create a new Rmarkdown file named
power_report.Rmdand select HTML as our desired output.
-
Rstudio automatically creates a sample Rmarkdown file for you, but you can replace it entirely with the following which reuses code from our
power.Rscript from step 5.title: "Power_Report" output: html_document --- ```{r setup, include=FALSE} knitr::opts_chunk$set(echo = TRUE) library(tidyverse) library(lubridate) col_names <- c('HDF', 'date', 'half_hour_increment', 'CCGT', 'OIL', 'COAL', 'NUCLEAR', 'WIND', 'PS', 'NPSHYD', 'OCGT', 'OTHER', 'INTFR', 'INTIRL', 'INTNED', 'INTEW', 'BIOMASS', 'INTEM') df <- read.csv('data.csv', header = FALSE, col.names = col_names, stringsAsFactors = FALSE) #remove the first and last row df <- df[-1,] df <- df[-nrow(df),] #Tidy the data df_tidy <- df %>% gather('CCGT', 'OIL', 'COAL', 'NUCLEAR', 'WIND', 'PS', 'NPSHYD', 'OCGT', 'OTHER', 'INTFR', 'INTIRL', 'INTNED', 'INTEW', 'BIOMASS', 'INTEM', key="fuel", value="megawatt") ```R Markdown
Combining R Markdown, Knitr and Domino allows you to create attractive scheduled reports that mix text, code and plots.
```{r, echo=FALSE, warning=FALSE} df_tidy <- df_tidy %>% mutate(datetime=as.POSIXct(as.Date(date, "%Y%m%d"))+minutes(30*(half_hour_increment-1))) print(head(df_tidy)) ```Including Plots
You can also embed plots, for example:
```{r, echo=FALSE} p <- ggplot(data=df_tidy, aes(x=datetime, y=megawatt, group=fuel)) + geom_line(aes(color=fuel)) print(p) ``` -
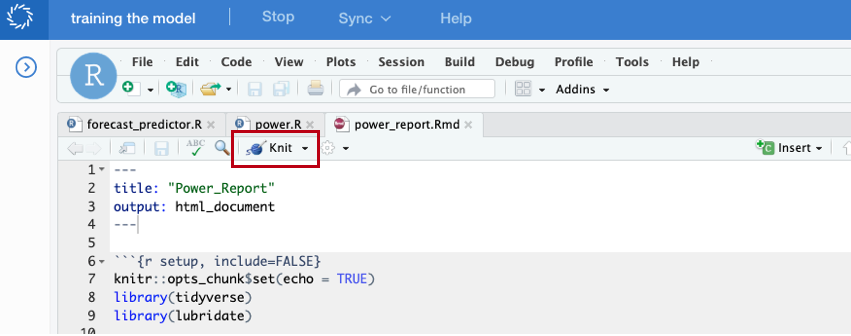
With your new Rmarkdown file, you can "knit" this into an html file and preview it directly in Domino by hitting the "Knit" button.
-
To create a repeatable report, you must create a script that you can schedule that will automatically render your Rmarkdown file to html. Start by creating a new R script named
render.Rwith the following code:rmarkdown::render("power_report.Rmd") -
Save your files and *Stop and Commit() your workspace.
-
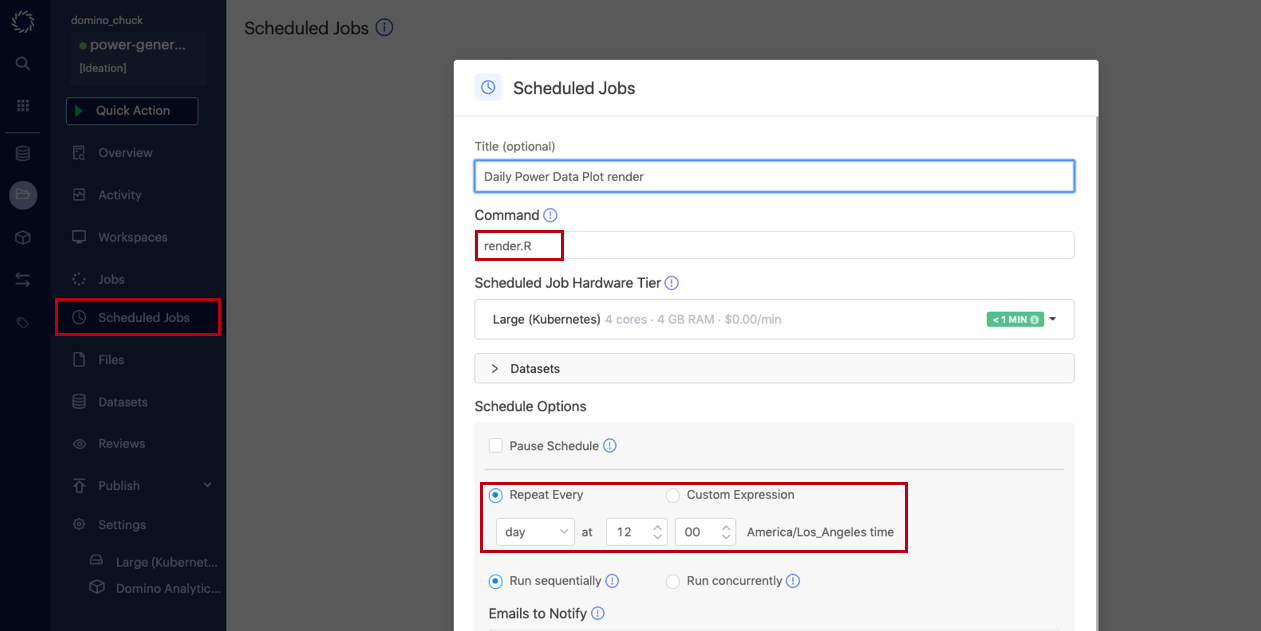
Go to the Scheduled Jobs page.
-
Enter the file that you want to run. This will be the
render.Rscript you created earlier. -
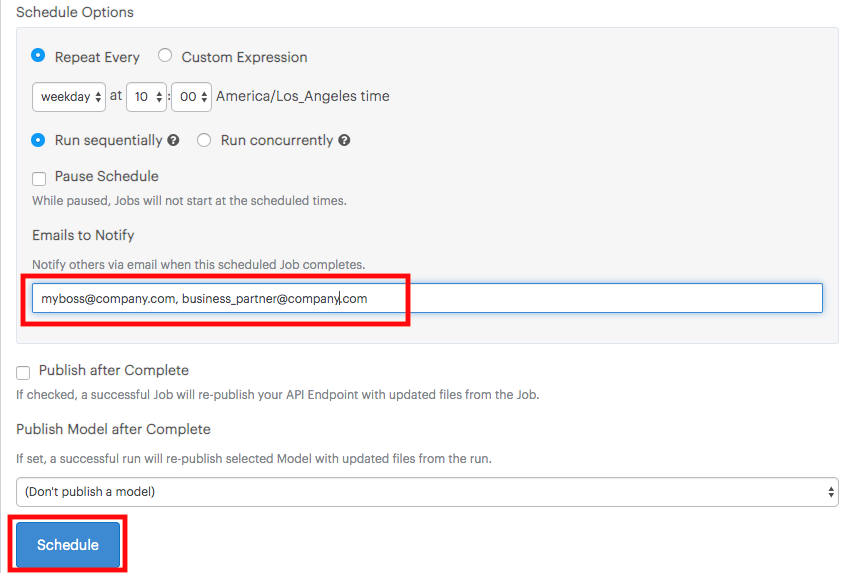
Select how often and when to run the file.
-
Enter emails of people to send the resulting file(s) to.
-
Click Schedule.
To discover more tips on how to customize the resulting email, see Set Notification Preferences for more information.
Launchers are simple web forms that allow users to run templatized scripts. They are especially useful if your script has command line arguments that dynamically change the way the script executes. For heavily customized script, those command line arguments can quickly get complicated. Launcher allows you to expose all of that as a simple web form.
Typically, we parameterize script files (that is, files that end in .py,
.R, or .sh). Since we have been working with an R script until now,
we will parameterize and reuse our R script that we created when we
developed the R model.
To do so, we will insert a few new lines of code into a copy of the R script, and configure a Launcher.
-
Parameterize your R script by setting it to take command line arguments:
-
Start an Rstudio session.
-
Create script named
Power_for_Launcher.Rwith the following:library(tidyverse) library(lubridate) #Pass in command line arguments args <- commandArgs(trailingOnly = TRUE) fuel_type <- args[1] col_names <- c('HDF', 'date', 'half_hour_increment', 'CCGT', 'OIL', 'COAL', 'NUCLEAR', 'WIND', 'PS', 'NPSHYD', 'OCGT', 'OTHER', 'INTFR', 'INTIRL', 'INTNED', 'INTEW', 'BIOMASS', 'INTEM') df <- read.csv('data.csv', header = FALSE, col.names = col_names, stringsAsFactors = FALSE) #remove the first and last row df <- df[-1,] df <- df[-nrow(df),] #Tidy the data df_tidy <- df %>% gather('CCGT', 'OIL', 'COAL', 'NUCLEAR', 'WIND', 'PS', 'NPSHYD', 'OCGT', 'OTHER', 'INTFR', 'INTIRL', 'INTNED', 'INTEW', 'BIOMASS', 'INTEM', key="fuel", value="megawatt" ) #Create a new column datetime that represents the starting datetime of the measured increment. df_tidy <- df_tidy %>% mutate(datetime=as.POSIXct(as.Date(date, "%Y%m%d"))+minutes(30*(half_hour_increment-1))) #Filter the data df_fuel_type <- df_tidy %>% filter(fuel==fuel_type) %>% select(datetime,megawatt) #Save out data as csv write.csv(df_fuel_type, paste(fuel_type,"_",Sys.Date(),".csv",sep="")) -
Notice the lines in our script that define an object from a command line arguments
args <- commandArgs(trailingOnly = TRUE) fuel_type <- args[1] -
Save the files and Stop and Commit the workspace session.
-
-
Configure the Launcher.
-
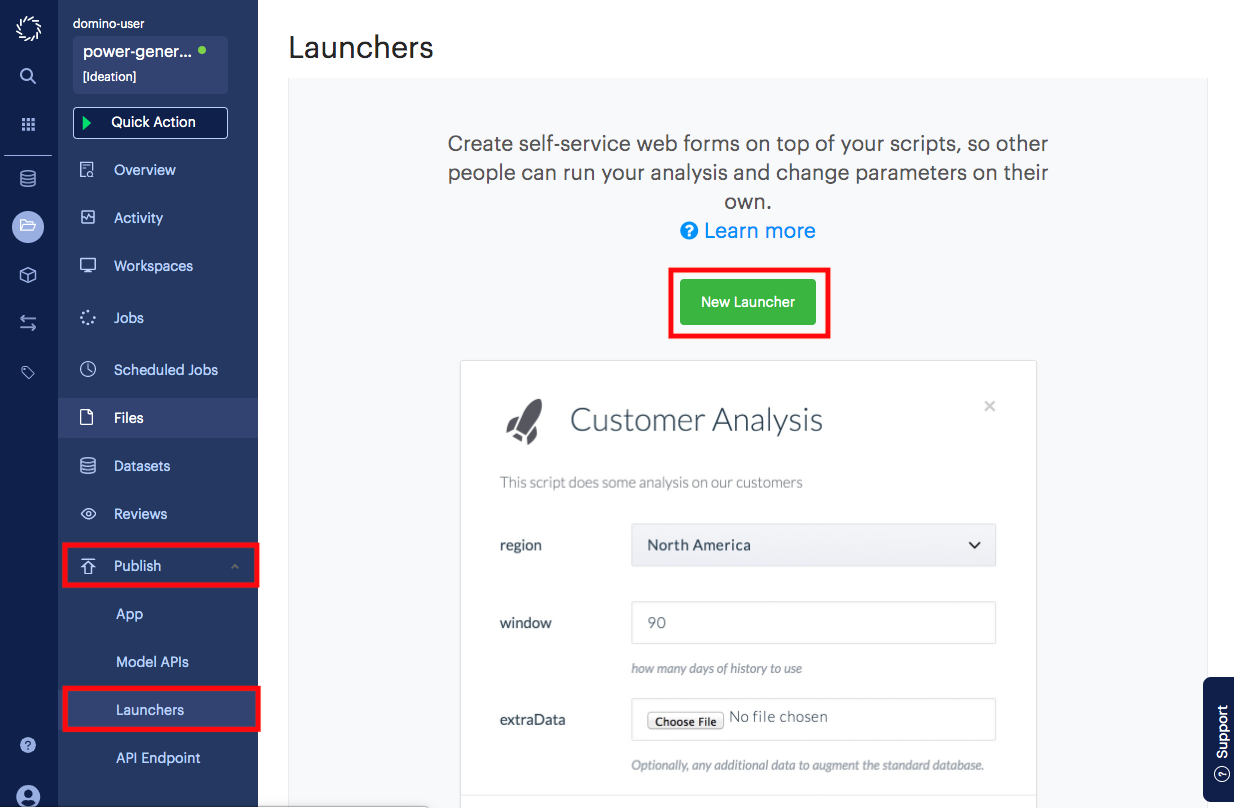
Go to the Launcher page. It is under the Publish menu on the project page.
-
Click New Launcher.
-
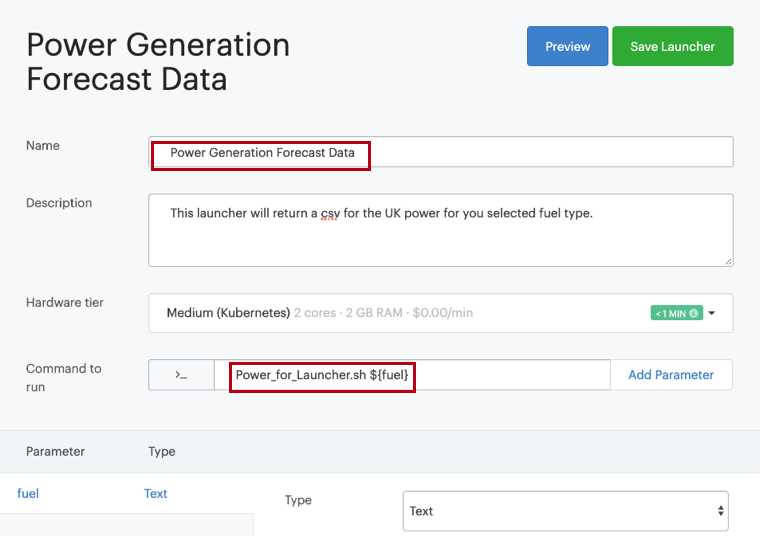
Name the launcher "Power Generation Forecast Data".
-
Copy and paste the following into the field "Command to run":
Power_for_Launcher.R ${fuel}You should see the following parameters:
-
Select the fuel_type parameter and change the type to Select (Drop-down menu).
-
Copy and paste the following into the Allowed Values field:
CCGT, OIL, COAL, NUCLEAR, WIND, PS, NPSHYD, OCGT, OTHER, INTFR, INTIRL, INTNED, INTEW, BIOMASS, INTEM -
Click Save Launcher.
-
-
Try out the Launcher.
-
Go back to the main Launcher page.
-
Click Run for the "Power Generation Forecast Trainer" launcher.
-
Select a fuel type from the dropdown.
-
Click Run.
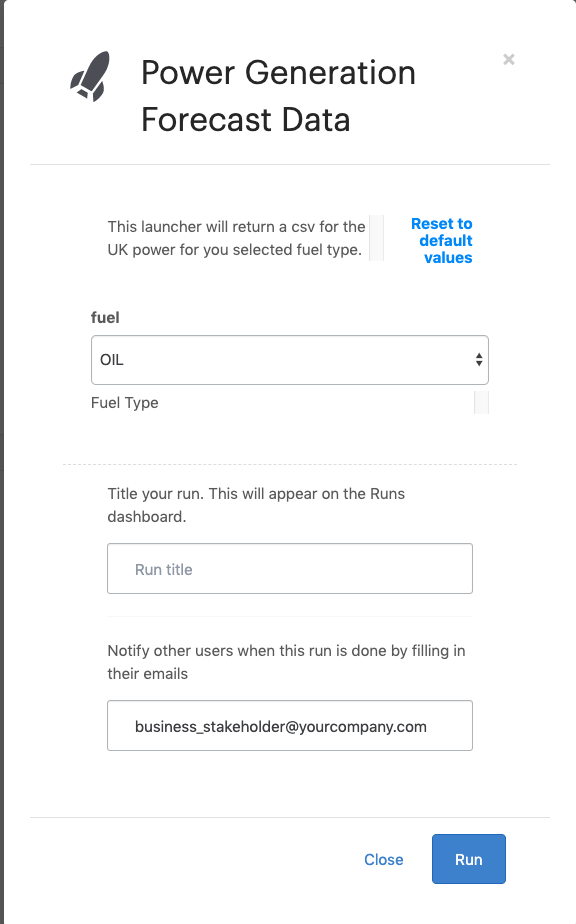
This will execute the parameterized R script with the parameters that you selected. In this particular launcher, your dataset is filtered based on your input parameter with the results returned as a csv. When the run has been completed, an email will be sent to you and others that you optionally specified in the launcher with the resulting files. If you optionally specified in the launcher with the resulting files. See Set Custom Execution Notifications to learn how to customize the resulting email.
-
If you want your model to serve another application, you will want to serve it in the form of an API endpoint. Model APIs are scalable REST APIs that can create an endpoint from any function in a Python or R script. The Model APIs are commonly used when you need an API to query your model in near real-time.
For example, we created a model to forecast power generation of combined cycle gas turbines in the UK.
In this section, we will deploy an API that uses the previously trained model to predict the generated power given a date in the future. To do so, we will create a new compute environment to install necessary packages, create a new file with the function we want to expose as an API, and finally deploy the API.
-
Create a new file with the function we want to expose as an API.
-
From the Files page of your project, click Add File.
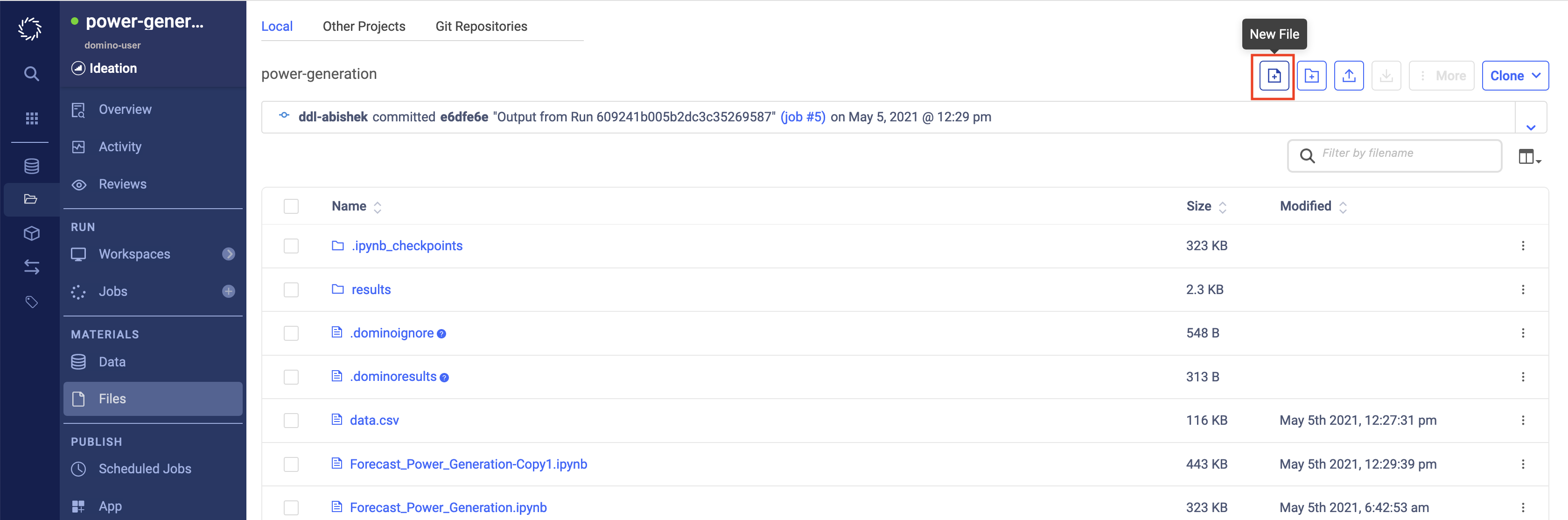
-
Name your file
forecast_predictor.R. -
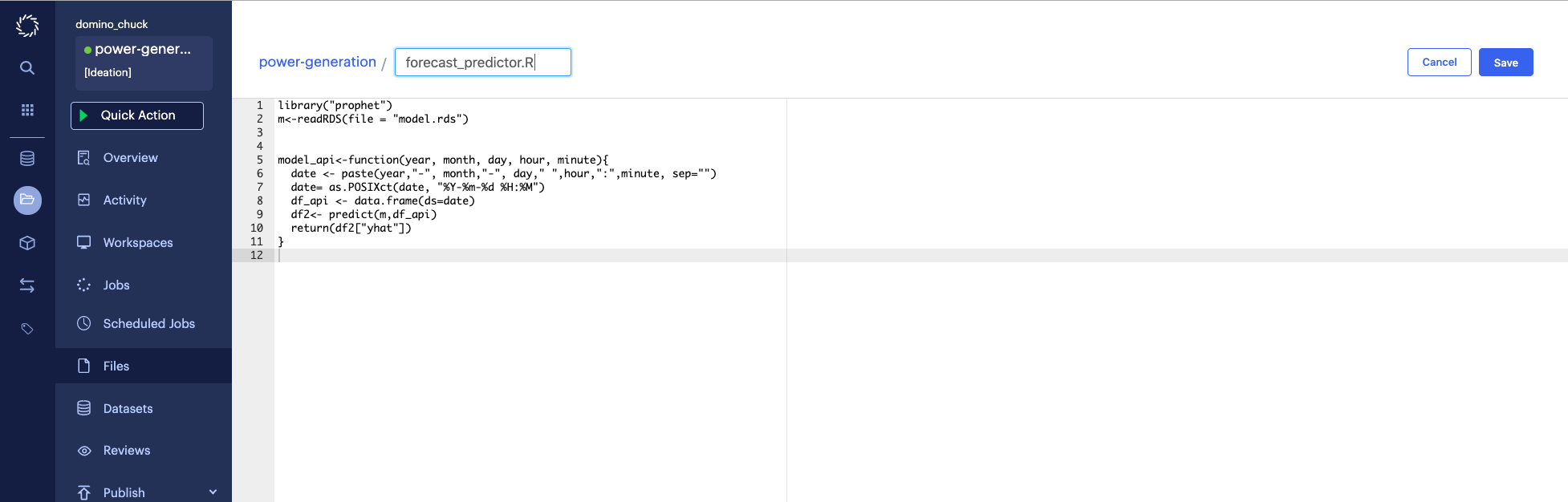
Enter the following contents:
library("prophet") m <- readRDS(file = "model.rds") model_api <- function(year, month, day, hour, minute) { date <- paste(year, "-", month, "-", day, " ", hour, ":", minute, sep="") date = as.POSIXct(date, format="%Y-%m-%d %H:%M") df_api <- data.frame(ds=date) df2 <- predict(m, df_api) return(df2["yhat"]) } -
Click Save.
-
-
Deploy the API.
-
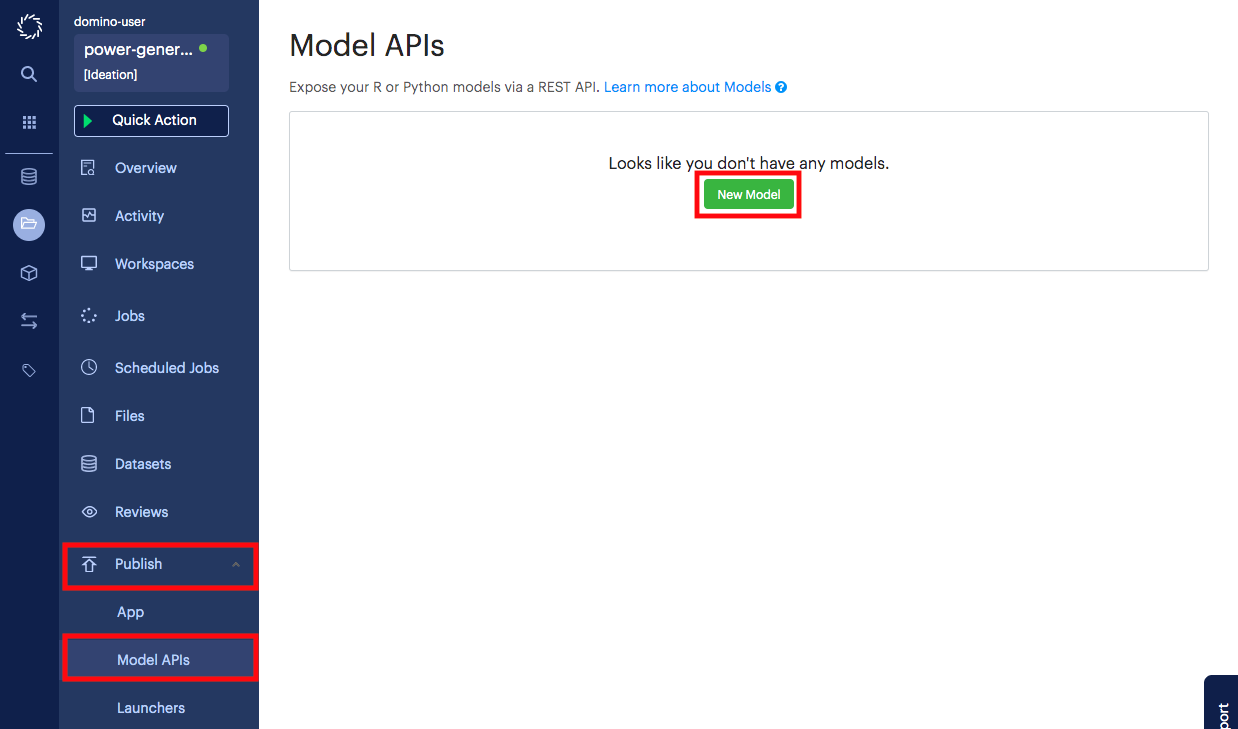
Go to the Publish/Model APIs page in your project.
-
Click New Model.
-
Name your model, provide a description, and click Next.
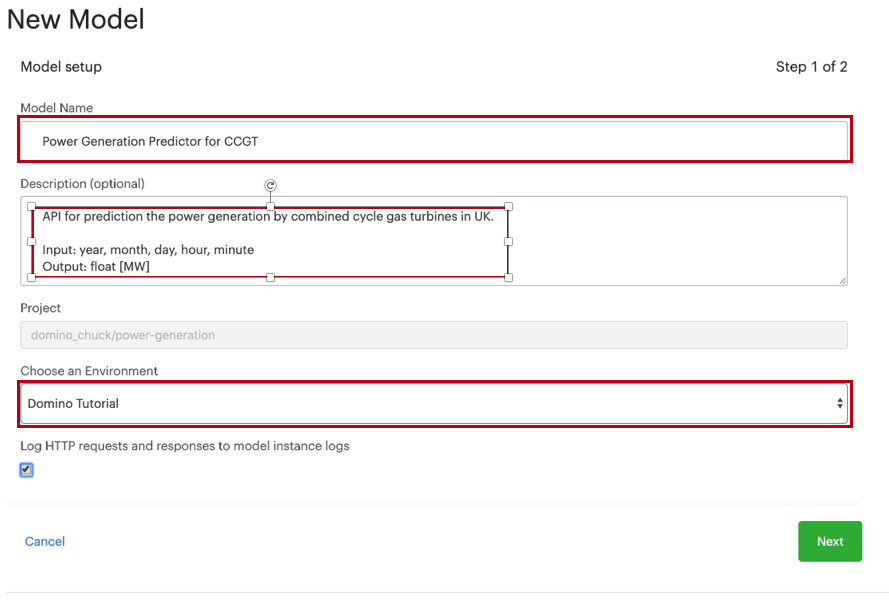
-
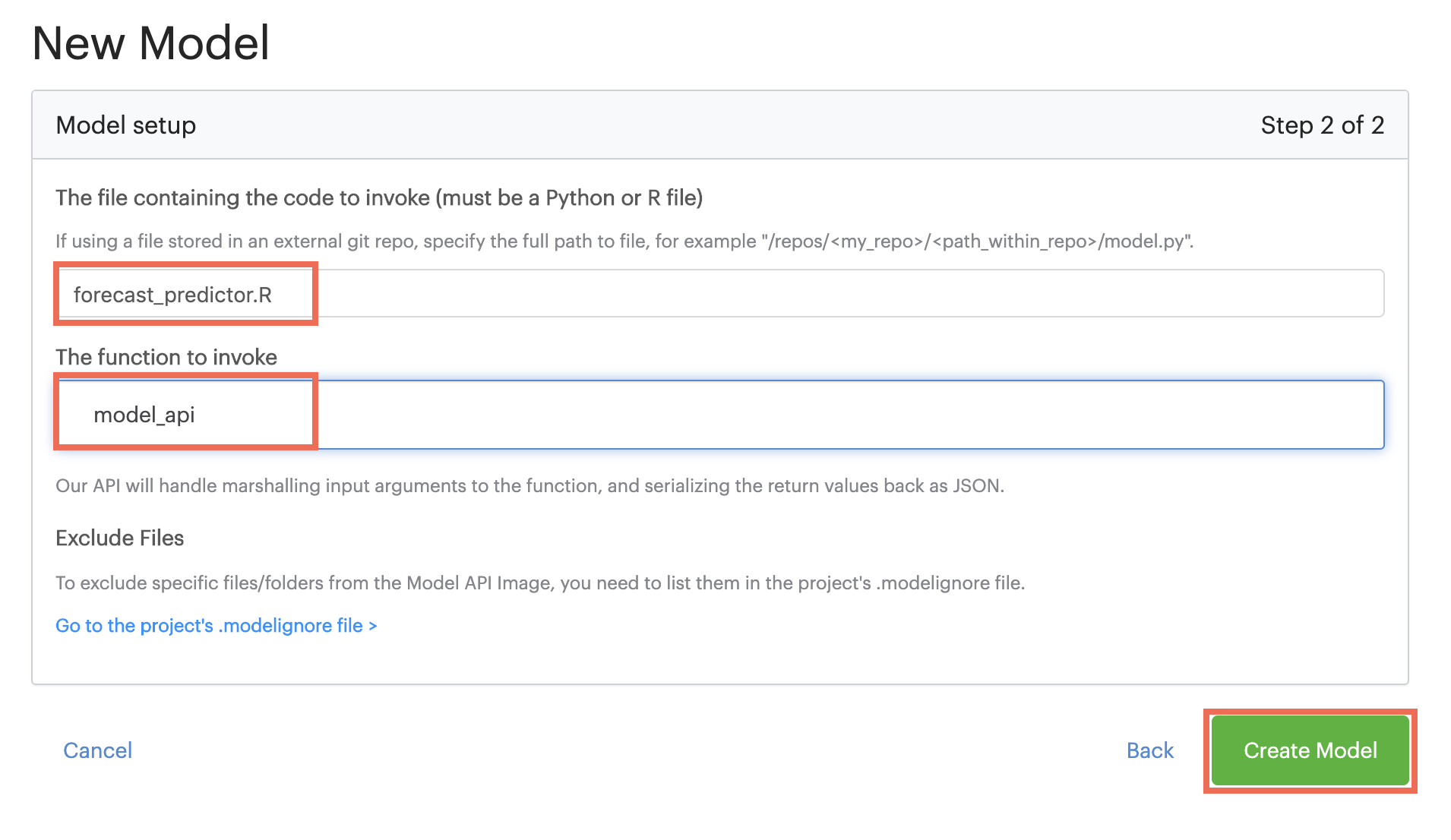
Enter the name of the file that you created in the previous step.
-
Enter the name of the function that you want to expose as an API.
-
Click Create Model.
-
-
Test the API.
-
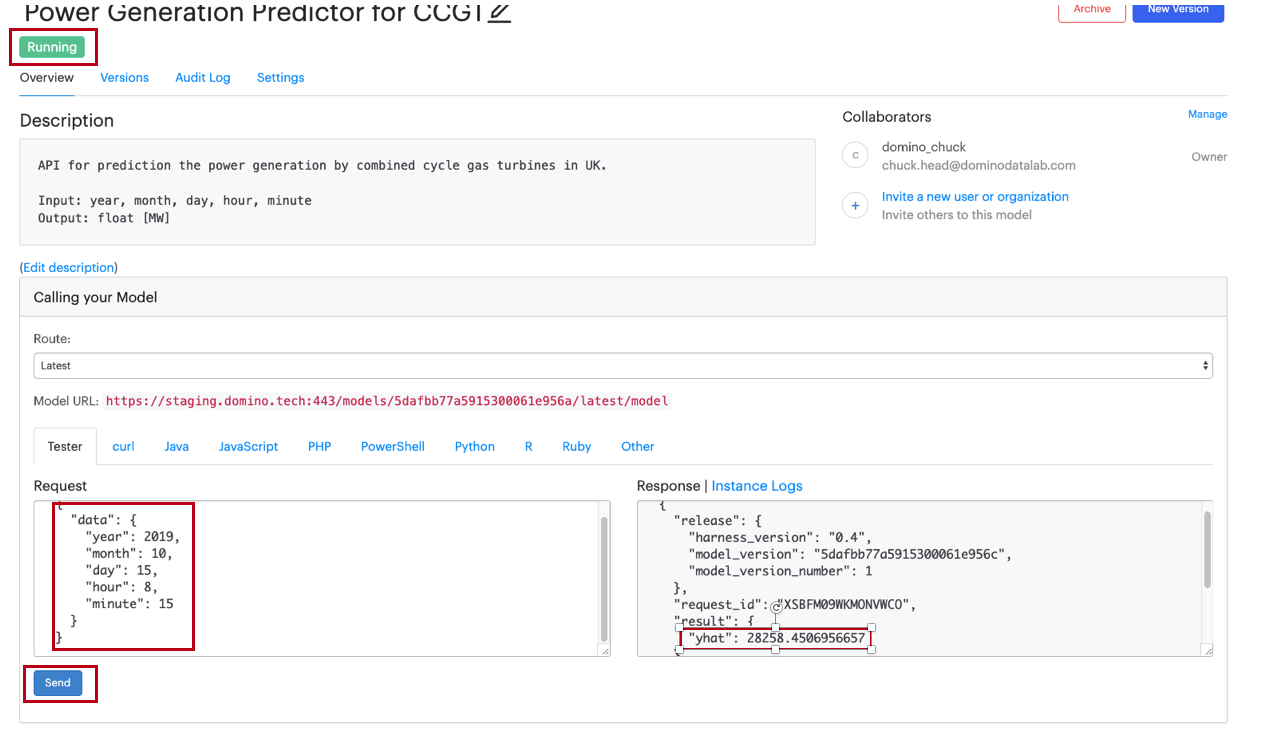
Wait for the Model API status to turn to Running. This might take a few minutes.
-
Click the Overview tab.
-
Enter the following into the tester:
{ "data": { "year": 2019, "month": 10, "day": 15, "hour": 8, "minute": 15 } } -
Click Send. If successful, you will see the response on the right panel.
-
As a REST API, any other common programming language will be able to call it. Code snippets from some popular languages are listed in the other tabs.
Model APIs are built as docker images and deployed on Domino. You can export the model images to your external container registry and deploy them in any other hosting environment outside of Domino using your custom CI/CD pipeline. The Domino Platform API enables you to programmatically build new model images on Domino and export them to your external container registry.
When experiments in Domino yield interesting results that you want to share with your colleagues, you can easily do so with a Domino App. Domino supports hosting Apps built with many popular frameworks, including Flask, Shiny, and Dash.
While Apps can be significantly more sophisticated and provide far more functionality than a Launcher, they also require significantly more code and knowledge in at least one framework. In this section, we will convert some code that we developed when we developed the model and create a Shiny app.
-
Add the
app.Rfile, which will describe the app in Shiny, to the project:library(tidyverse) library(lubridate) library(prophet) library(dygraphs) col_names <- c('HDF', 'date', 'half_hour_increment', 'CCGT', 'OIL', 'COAL', 'NUCLEAR', 'WIND', 'PS', 'NPSHYD', 'OCGT', 'OTHER', 'INTFR', 'INTIRL', 'INTNED', 'INTEW', 'BIOMASS', 'INTEM') df <- read.csv('data.csv',header = FALSE,col.names = col_names,stringsAsFactors = FALSE) #remove the first and last row df <- df[-1,] df <- df[-nrow(df),] fuels <- c('CCGT', 'OIL', 'COAL', 'NUCLEAR', 'WIND', 'PS', 'NPSHYD', 'OCGT', 'OTHER', 'INTFR', 'INTIRL', 'INTNED', 'INTEW', 'BIOMASS', 'INTEM') predict_ln <- round((nrow(df))*.2) #Tidy the data and split by fuel df_tidy <- df %>% mutate(ds=as.POSIXct(as.Date(date, "%Y%m%d"))+minutes(30*(half_hour_increment-1))) %>% select(-c('HDF', 'date', 'half_hour_increment')) %>% gather("fuel", "y", -ds) %>% split(.$fuel) #remove unused column df_tidy <- lapply(df_tidy, function(x) { x["fuel"] <- NULL; x }) #Train the model m_list <- map(df_tidy, prophet) #Create dataframes of future dates future_list <- map(m_list, make_future_dataframe, periods = predict_ln,freq = 1800 ) #Pre-Calc yhat for future dates #forecast_list <- map2(m_list, future_list, predict) # map2 because we have two inputs ui <- fluidPage( verticalLayout( h2(textOutput("text1")), selectInput(inputId = "fuel_type", label = "Fuel Type", choices = fuels, selected = "CCGT"), dygraphOutput("plot1"))) server <- function(input, output) { output$plot1 <- renderDygraph({ forecast <- predict(m_list[[input$fuel_type]], future_list[[input$fuel_type]]) dyplot.prophet(m_list[[input$fuel_type]], forecast) }) output$text1 <- renderText({ input$fuel_type }) } shinyApp(ui = ui, server = server) -
Add an
app.shfile to the project, which provides the commands to instantiate the app:R -e 'shiny::runApp("app.R", port=8888, host="0.0.0.0")' -
Publish the App.
-
Go to the App page under the Publish menu of your project.
-
Enter a title and a description for your app.
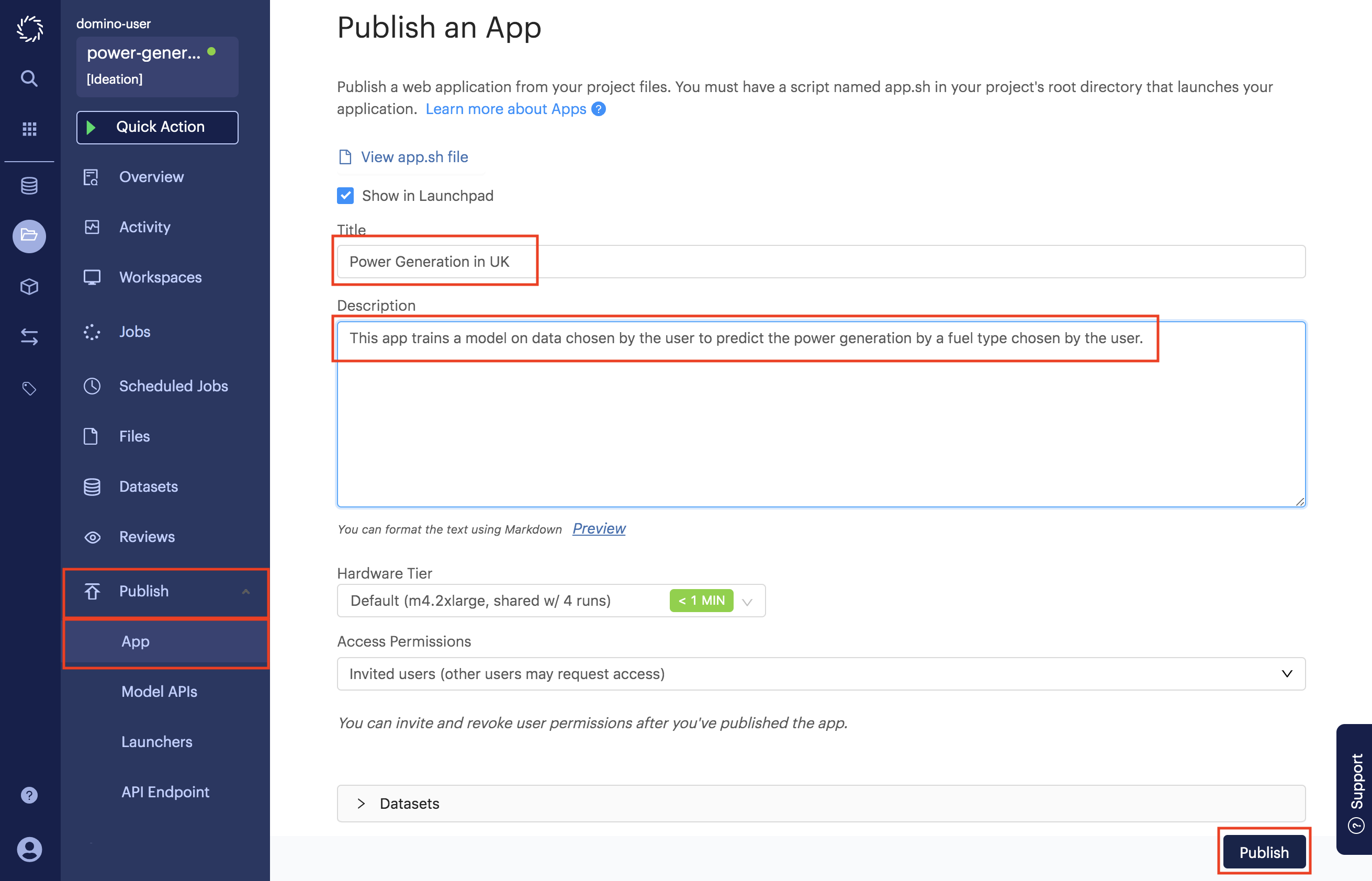
-
Click Publish.
-
After your app starts successfully, which might take a few minutes, you can click View App to open it.
-
-
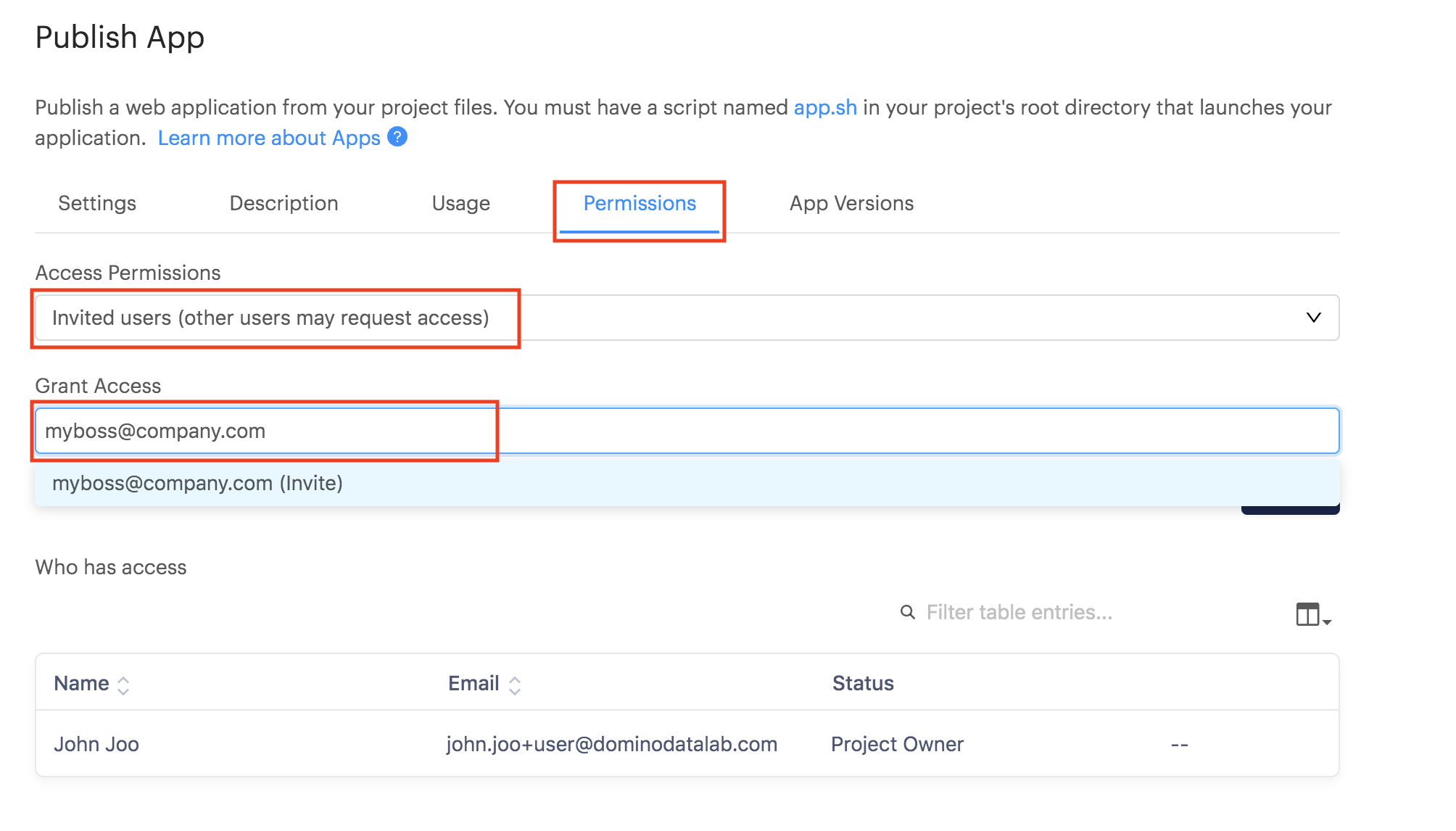
Share your app with your colleagues.
-
Back on the Publish/App page, click the App Permissions tab.
-
Invite your colleagues by username or email.
-
Or, toggle the Access Permissions level to make it publicly available.
-
See Domino Apps for more information.