Learn how to train a low-code model with Domino AutoML. Select your dataset and specify the prediction task, AutoML generates code to prepare the data, test multiple algorithms, and optimize hyperparameters to find the best model for you.
Data scientists can use AutoML to speed up repetitive tasks and generate starting code for more advanced projects. Data analysts can use it to run initial ML experiments before working with data scientists to fine tune experiments.
Domino leverages FLAML (Fast and Lightweight AutoML), an open-source Python library that automates model selection and hyperparameter tuning.
Unlike other AutoML tools, Domino provides immediate code access, eliminating the black-box approach. AutoML offers the following benefits:
-
Time saving - Streamline model development by automating tasks like experiment setup and hyperparameter tuning.
-
Accessibility - Empower data analysts to perform early-stage machine learning without extensive data science knowledge.
-
Reproducibility and transparency - Maintain control over the entire process with full code visibility and ownership.
-
Collaboration - Use code-first collaboration tools like Git, leveraging the code provided by AutoML.
-
Start a Jupyter workspace to use AutoML.
-
Hover over the
 icon to show a popup menu.
icon to show a popup menu. -
Select Load data > QUICK-START > iris to load the iris dataset.
AutoML currently supports classification, regression, and forecasting machine learning tasks.
-
In the next cell of the Jupyter notebook, hover over the
icon and select AutoML > Classifications. -
Configure the AutoML experiment:
-
Data frame - Select the dataframe variable that contains your dataset. In this case, select
df. -
Predict value - Select the variable that you want to predict. In this case, select
species. -
Features - Specify the data features that you want to train your model on. Remove
species_idto make sure you don’t train on data that already contains the correct value.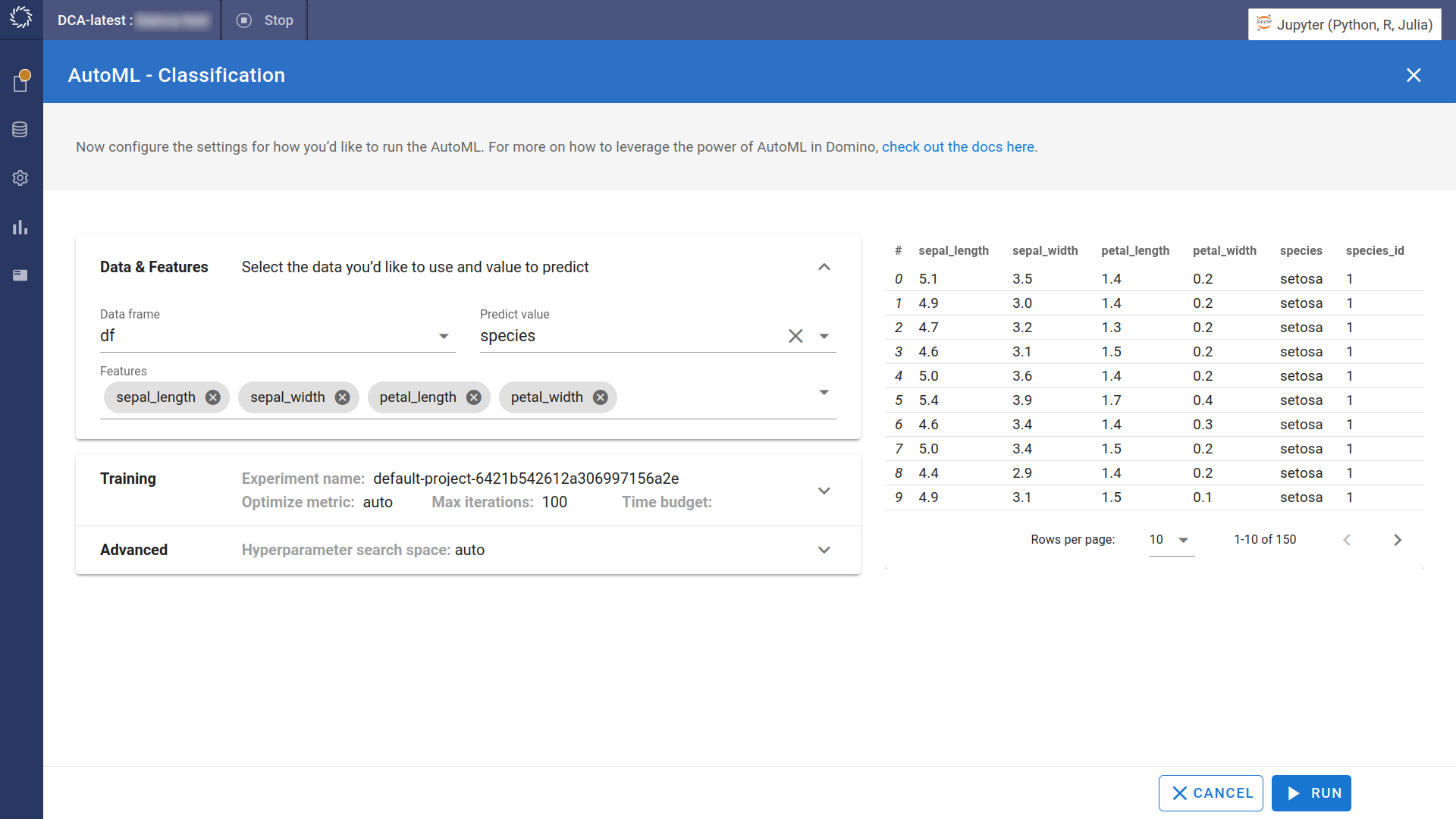
-
-
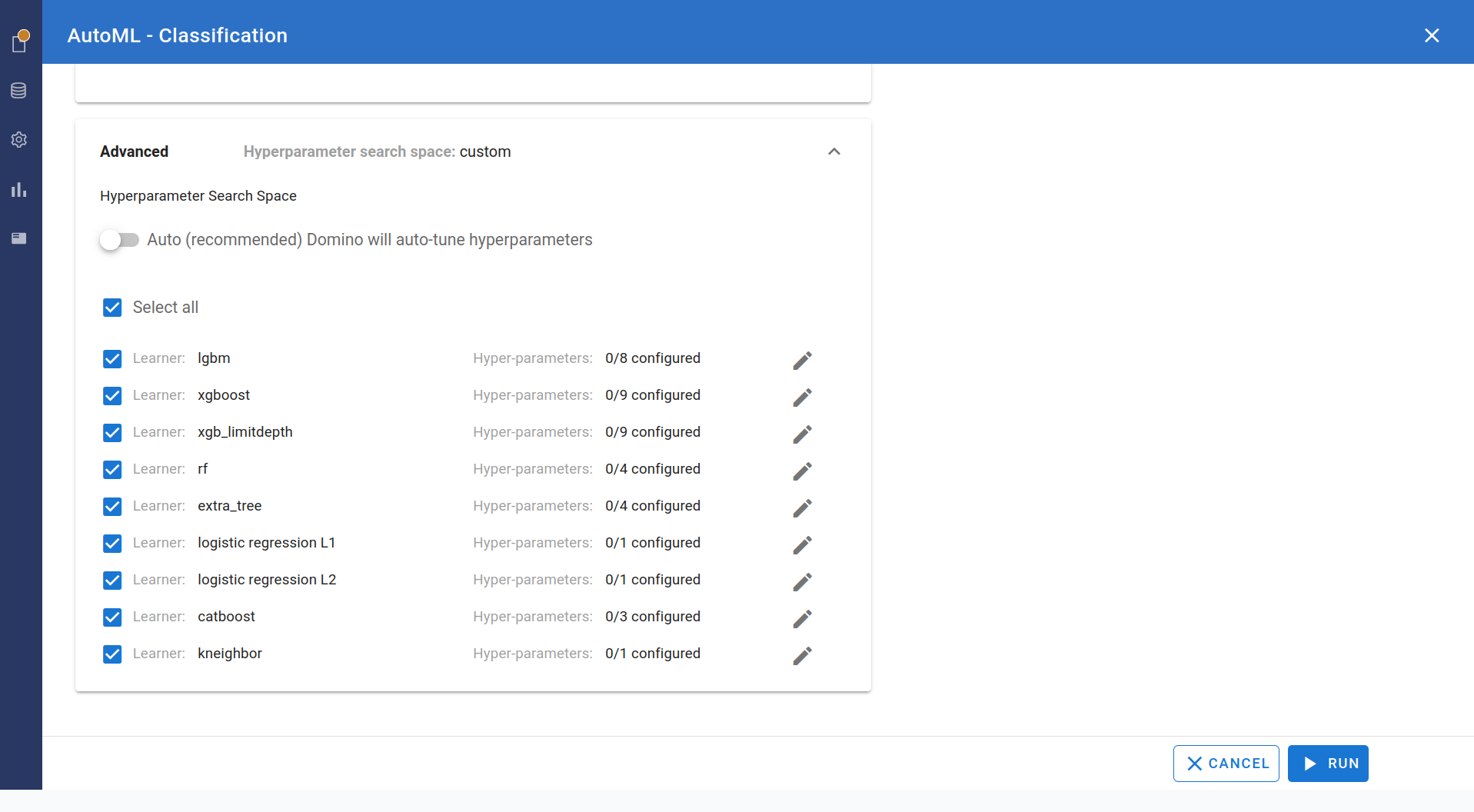
Expand the Training and Advanced settings to customize run parameters, algorithm selection, and hyperparameter tuning.
-
Click to add the training code to the notebook and run it.
Code Assist automatically adds MLflow tracking to let you view results and monitor progress. It uses the default experiment to track results. However, you can specify a different experiment by editing the experiment_name variable.
-
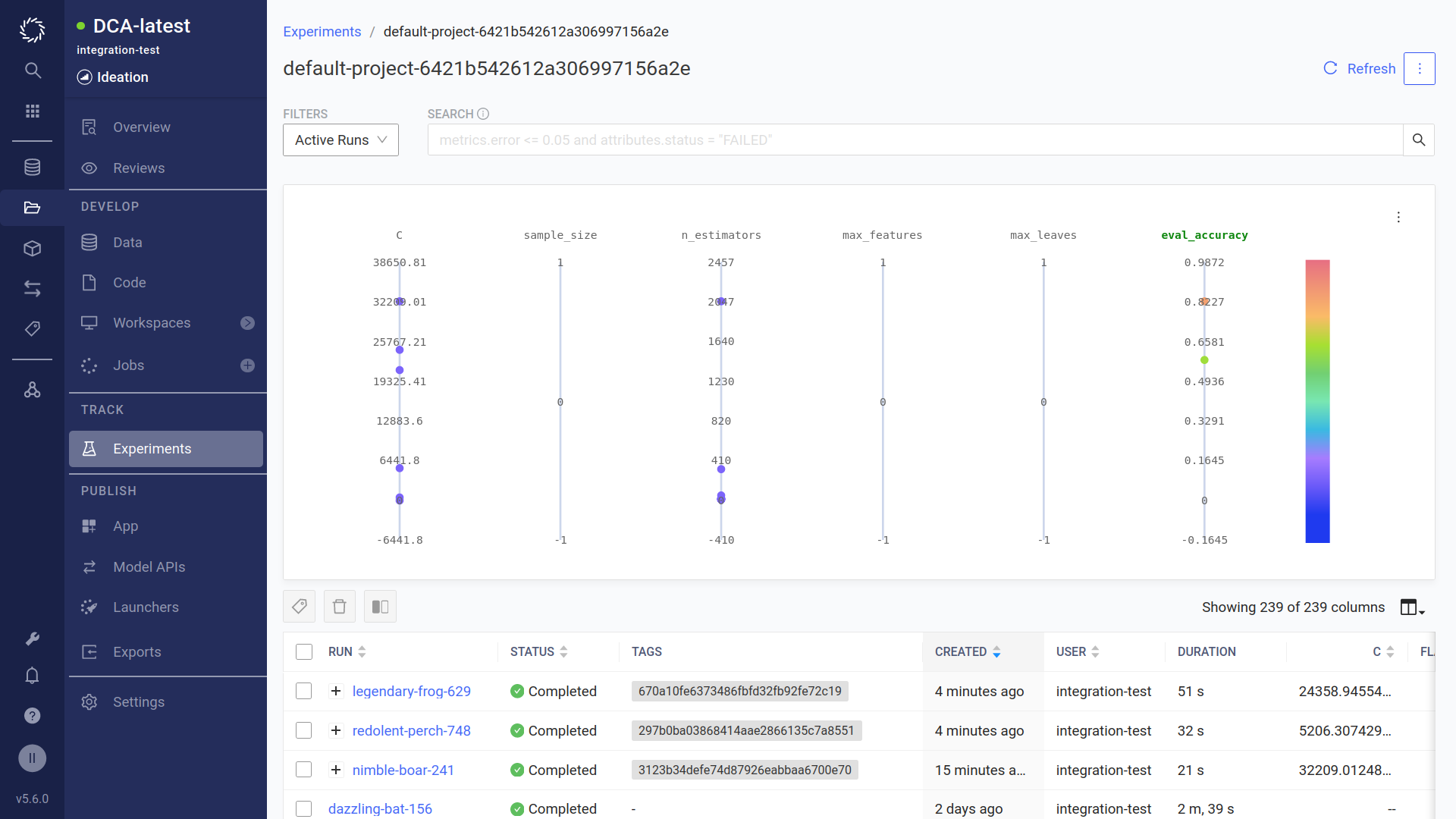
To view the experiment, click . Note the Run-name indicated.
You will see the parent iteration together with the child iterations.
-
Click on the experiment name you noted earlier in the RUN column to view details of the experiment including parameters, metrics, outputs, and logs.
To edit the experiment, modify the code in the cell and rerun the code, or choose the Edit item from the Domino Code Assist context menu.
For more advanced edits, see the FLAML docs to learn more.