Domino monitors data drift and model quality.
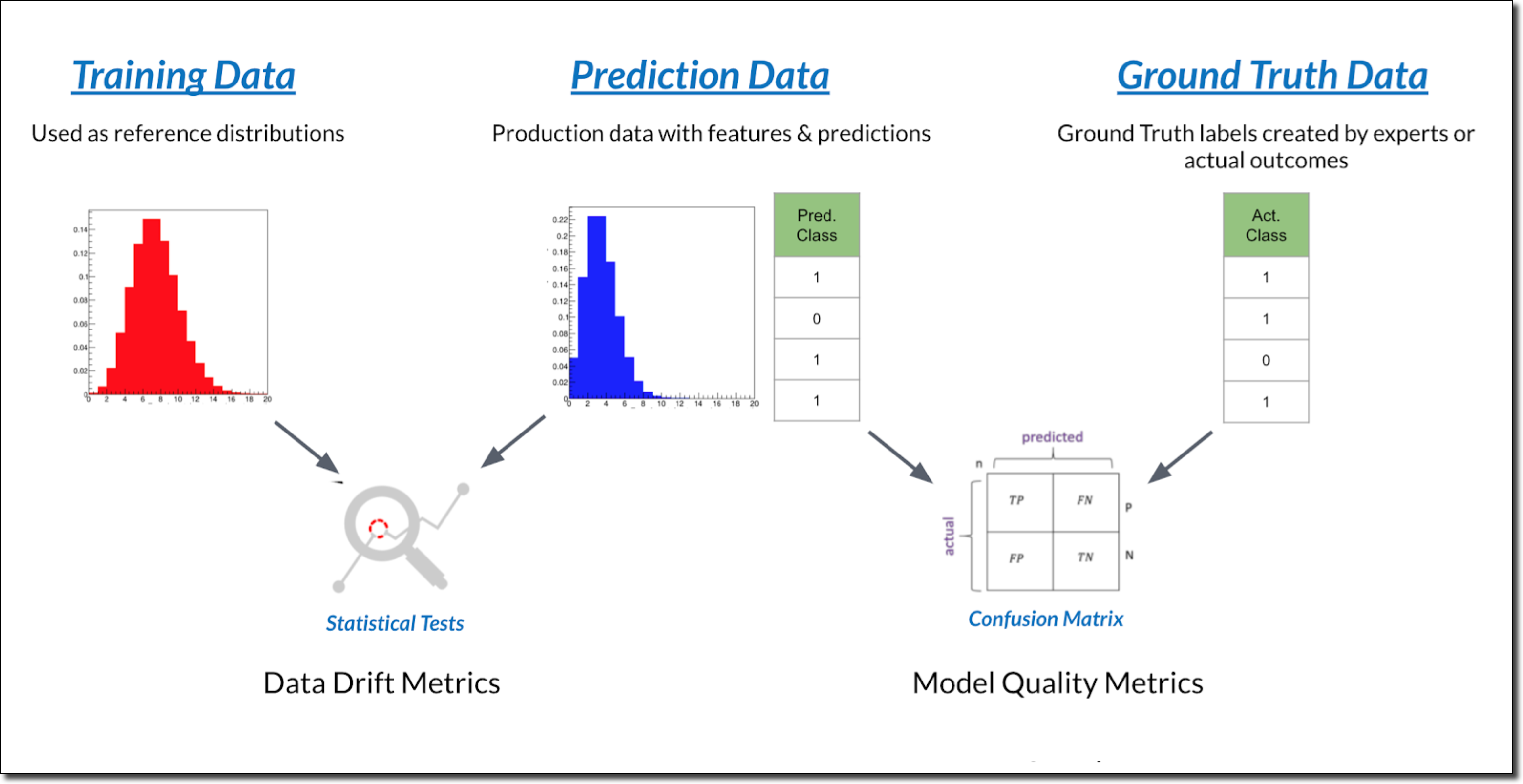
Data drift occurs when production data diverges from the model’s original training data. Data drift can happen for many reasons, including a changing business environment, evolving user behavior and interest, modifications to data from third-party data sources, data quality issues, and even issues in upstream data processing pipelines. Data drift monitoring compares live predictions with the model’s training data, and then sends an alert when live predictions diverge too much from the training data. See Analyze Data Drift.
Model quality monitoring compares the model’s predicted values against the actual results (or labels for the predictions) using ground truth data to generate quality metrics. For classification models, Domino reports the following metrics:
-
Accuracy
-
Precision
-
Recall
-
F1
-
AUC ROC
-
Log Loss
-
Gini (Normalized)
Domino also provides a confusion matrix and classification report for further quality evaluation.
For regression models, Domino reports the following metrics.
-
Mean Square Error (MSE)
-
Mean Absolute Error (MAE)
-
Mean Absolute Percentage Error (MAPE)
-
R-Squared (R2)
-
Gini (Normalized)
See Metrics for classification and regression models for details.
When data drift or model quality issues are detected, the Cohort Analysis feature identifies underperforming cohorts of data so you can take remedial action. See Cohort Analysis.
Use Domino to recreate the development environment originally used to train the model. Then, you can use this environment to access the prediction data to diagnose issues, update code, and retrain your model with the latest production data.